学习率是深度神经网络里最重要的超参数之一,学习率的选取直接影响了我们模型的质量,但有时学习率的选取是很玄学的
训练失败的原因
我们有时会发现自己的模型经过很多次训练,lost不会收敛到一个很小的值,这应该从以下几方面考虑
局部最优解
反向传播更新参数的本质就是让参数向梯度的反方向更新,这一来如果遇到梯度为零却不是 全局最优解 的点,模型就会陷入这个点中不能自拔,这个点我们就称为 局部最优解 。损失函数是一个多维度很复杂的函数,我们很难想象他是什么样的,我们假设他是一个二维函数。下图就解释了 局部最优解 的情况
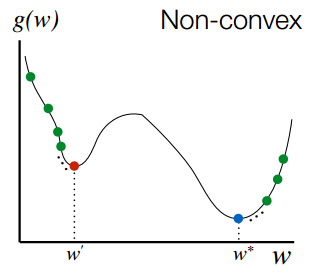
交叉熵损失函数 是常见的损失函数,我们在logistic回归使用他的原因是交叉熵损失函数是权重 w 的凸函数,这样一来就可以防止出现局部最优解的情况。但很不幸,在神经网络中交叉熵损失函数是非凸的。在 这篇文章 中给出了证明
鞍点
随着参数的增多,损失函数的维度就越高越复杂。更多的时候,我们的模型可能在收敛到局部最优解之前就会GG,其实是遇到了如下图所示的鞍点
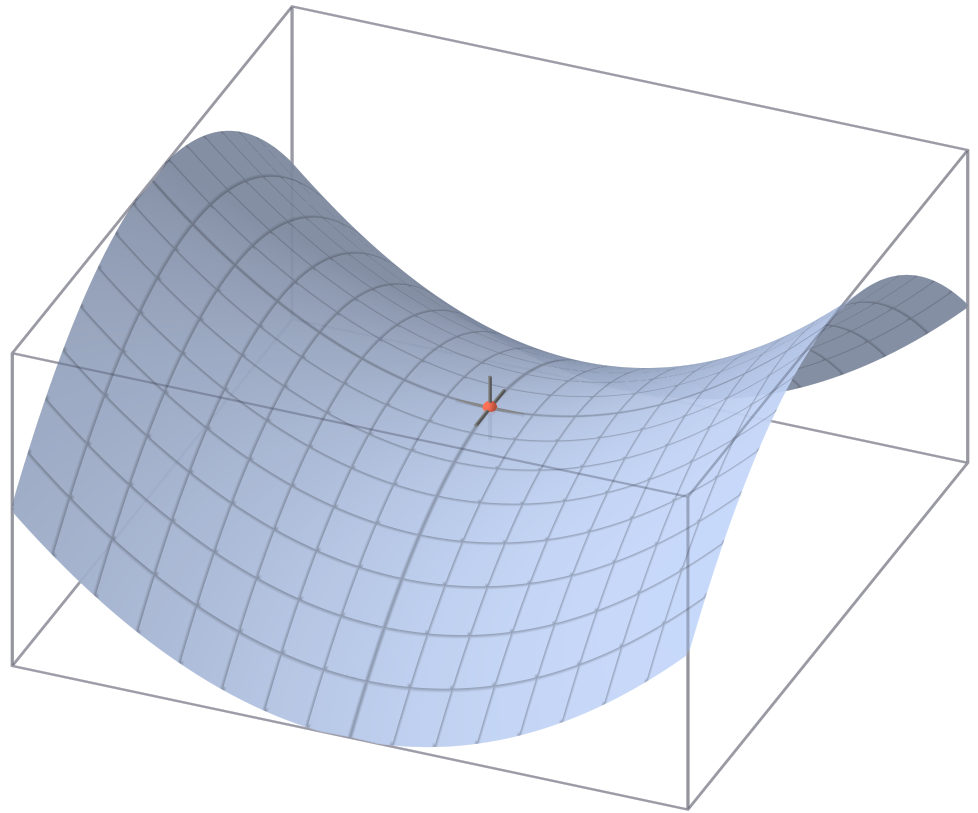
我们以三维为例,实际训练中情况复杂,我们很可能也从来没有真的遇到过局部极值,而是迷失在许多鞍点之中
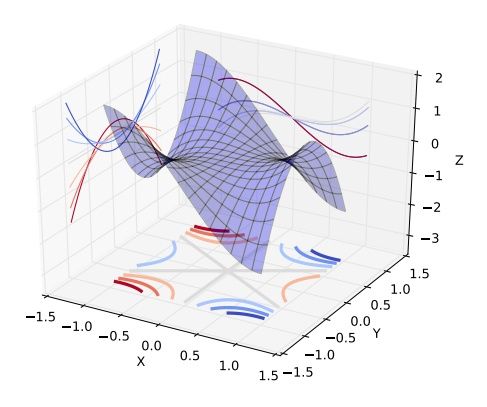
如何避免
- 使用 SGD,由于 SGD 会对数据添加噪声,所以模型有可能走出局部最优解
- 使用 MBGD 时,在每个 epoch 后把数据洗牌一遍,让每个 batch 的数据都不一样
- 可能是权重的初始化值不好,尝试多次训练
- 尝试调高学习率
- 尝试其他优化算法
过高的学习率
过高的学习率会导致参数在最小值附近徘徊而不能收敛到最小值
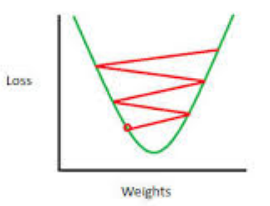
如何选取学习率
以下内容参考了这位 大佬
他将自己的模型用6种不同梯度下降优化算法实现,Gradient Descent, Adam, Adagrad, Adadelta, RMS Prop, Momentum。对于每种算法采用48种不同的学习率。这些学习率是从0.000001到100的对数间隔
首先比较的是训练的时间,要求达到 97% 的 train accuracy。没有画出的点表示训练失败
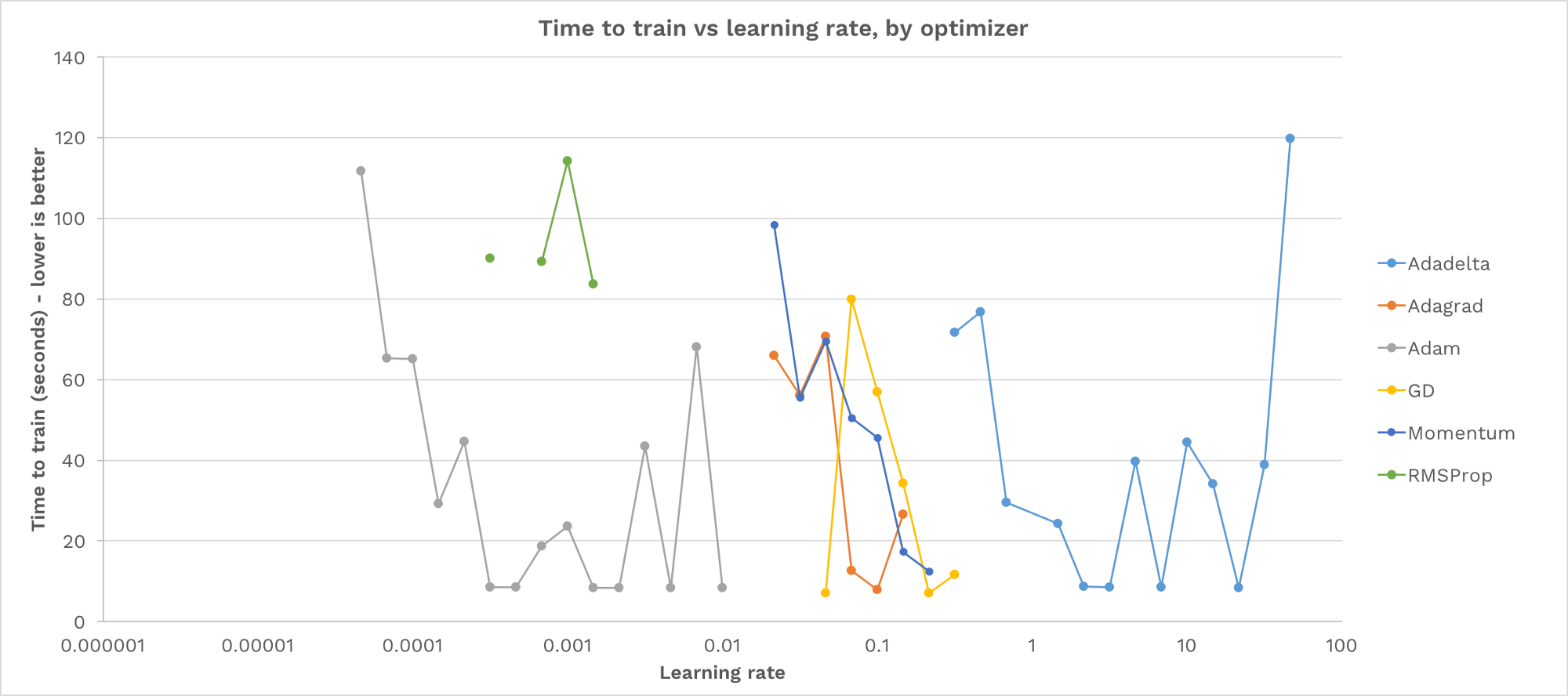
从这张图上我们可以得到:
对于每个算法,大多数学习速率都将导致训练失败
每个优化器都有一个山谷形状:学习率太低,进展缓慢;学习率太高会导致不稳定,永不收敛。在这两者之间,有一个“恰到好处”的学习率训练成功
没有一个普遍适用于所有算法的学习率
学习率可以影响训练时间一个数量级
这位大佬还得到了其他很多结论,其实如果训练数据变了,或者其他参数(如神经网络的层数)变了,都可能导致结论发生变化。对于选取学习率,还是多尝试,学习一些前辈们的相似模型,去借鉴这些模型中超参数的选取
总结
不管黑猫白猫,抓到老鼠的就是好猫,能降低loss就行,管他是局部最优解还是鞍点,反正如果训练样本发生变化,这些超参数还是要调整的

文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2018/12/23/learning-rate/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)