Spark中的重要概念,RDD,算子与共享变量
问题引入
在MapReduce计算模式下,不能够重用某一阶段的工作数据集。这对于迭代计算和交互式数据挖掘工具来说,效率是大大下降的。如果能够将数据保存在内存中,则性能将提高一个数量级。
RDD
RDD 全称Resilient Distributed Datasets,即弹性分布式数据集。它具有以下特点:
- RDD 中的数据集根据某种规则(用户可控)划分为了多个partition
- 惰性计算
- 只读不可更改
- 可以错误恢复
- 只有在并行运算时才会物理化,不会持续保存在内存中(如果没有
persist),用户可以控制RDD的持久化 - 适用于批处理程序,且每个元素都应用相同的运算。不适用于异步细粒度的更新,如web应用
构造方法
- 共享文件系统上的文件,
textFile() Scala集合,parallelize()和makeRDD()- 由作用在现有 RDD 的 transformation 算子产生
- 改变现有RDD的持久化策略
cache:当有足够内存时,首次计算后的结果会保存在内存中save:保存至文件系统
窄依赖与宽依赖
- 窄依赖:父RDD的每个partition最多只被一个子RDD的partition依赖
- 运算时,只需在单个结点上顺序计算子RDD的所有父partition
- 若结点失效,只需计算丢失的父partition,由于父partition只对应一个子partition,所以重算利用率是100%
- 宽依赖:父RDD的每个partition被多个子RDD的partition依赖
- 运算时,需要在结点间shuffle依赖的父partition
- 若结点失效,需要计算所有依赖的父partition,由于父partition对应多个子partition,只因为其中一个子partition而计算父partition,重算利用率低,极端情况下可能父RDD分区都要进行重新计算
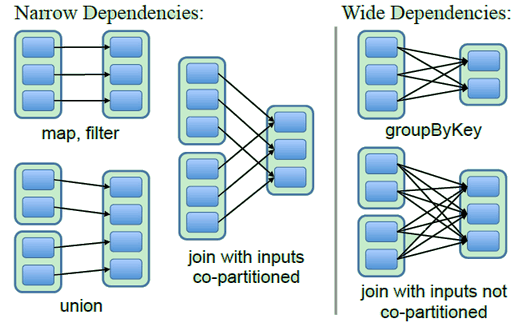
需要注意的是,在join操作中,如果两个RDD都用了相同的分区策略,即相同key对应的元素都在同一个分区,这时候join操作就是两个窄依赖,否则就是两个宽依赖
分区
对于一个RDD而言,分区的多少涉及对这个RDD进行并行计算的粒度,每一个RDD分区的计算操作都在一个单独的任务中被执行。非键值对RDD的partitioner属性为None。对于键值对类型的RDD,Spark提供了HashPatitioner和RangePatitioner,partitioner函数既决定了RDD本身的分区数量,也可作为其父RDD Shuffle输出中每个分区进行切割的依。每一个RDD在其内部维护了独立的ID号,同时对于RDD内的每一个分区也有一个独立的索引号,因此通过ID号+索引号就能全局唯一地确定这个分区。分区是一个逻辑上的概念,实际上调度的是与之一一对应的数据块。
持久化
当我们以默认或*基于内存的持久化方式缓存RDD时,RDD中的每一个分区所对应的数据块由内存缓存管理。内存缓存在其内部维护了一个以数据块名称为键,块内容为值的哈希表。默认JVM内存的60%可被内存缓存用来存储块内容(spark.storage.memoryFraction)。在磁盘缓存中,一个数据块对应着文件系统中的一个文件,文件名和块名称的映射关系是通过哈希算法计算所得的。
| Storage Level | Meaning |
|---|---|
MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认等级 |
MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用 |
MEMORY_ONLY_SER(Java and Scala) | 使用序列化的Java对象格式。其余同MEMORY_ONLY |
MEMORY_AND_DISK_SER(Java and Scala) | 使用序列化的Java对象格式。其余同MEMORY_AND_DISK |
DISK_ONLY | 使用序列化的Java对象格式,将数据全部写入磁盘文件中 |
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 同上述级别,但会将每个partition复制一份放在别的结点上 |
实现方式
RDD 这个抽象数据类型中包含这些数据域,partition 集合,依赖的父RDD(指针),元数据:分区规则和数据物理位置,可以通过以下方法获得
| Operation | Meaning |
|---|---|
partitions()` | Return a list of Partition objects |
preferredLocations(p) | List nodes where partition p can be accessed faster due to data locality |
dependencies() | Return a list of dependencies |
iterator(p, parentIters) | Compute the elements of partition p given iterators for its parent partitions |
partitioner() | Return metadata specifying whether the RDD is hash/range partitioned |
以下例子展现了,算子对 RDD 中数据域的影响
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val cachedErrs = errs.cache()
val ones = cachedErrs.map(_ => 1)
val count = ones.reduce(_+_)
filePartitions为HDFS的block IDPreferredLocations为block的物理位置iterator为打开读取block数据的流
cachedErrsiterator为寻找结点内存中的errs计算后的partition- 为防止结点失效,
PreferredLocations会更新
onesPartitions,PreferredLocations不变iterator为对cachedErrs的partition中元素应用_ => 1
RDD算子
RDD算子需要用户传入一个closure。所谓closure是scala里面的概念,指可以引用外部对象的函数。当master向worker发送task时,closure被表示成Java对象,如果内部存在外部引用对象,则将其作为closure的数据域。将closure序列化,通过网络传输给指定worker执行
transformation:惰性计算,只是记录信息action:触发计算,并返回计算值或者写入外部存储中
共享变量
如果closure中引用了外部对象,则会将其复制给每个closure对象,造成大量浪费。外部对象对于每个worker都是独立的变量。
Broadcast变量
只把变量复制给worker一次,而不是复制给每个closure。Broadcast变量的生存周期由spark的GC控制
实现
对于Broadcast变量b,值为v
- 将
v保存在共享的文件系统中 b中保存了v的地址(序列化后传递的数据)- 结点请求
b的值时,即调用b.value,首先在本地内存中查找,如果没有再根据路径从文件系统中读取
Accumulator变量
所有worker对Accumulator变量的改变,将会同步到master,但是只能做加法运算。
实现
- Accumulator变量包含ID和零值(序列化后传递的数据)
- 在worker中,Accumulator变量作为thread-local变量存在于每个task线程中,初值为零值
- worker等待所有task执行完毕后,发送结果给master,master只接受一次
任务调度
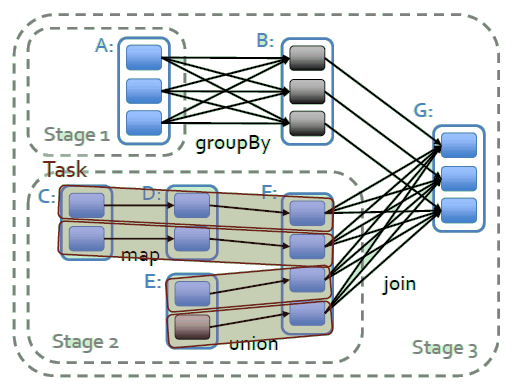
这是RDD世系图(lineage),是一个 DAG,包含一组 trasformation 和一个 action,组成了一个 job。下面说明世系图中最重要的三个概念
- job:由action算子生成的调度阶段
- stage:job的子集,尽可能多保存同一条流水线上的窄依赖transformation。即边界为shuffle运算和持久化
- task:stage的子集,每个partation的计算任务
master通过延时调度,不断向worker发送task,计算stage中未处理的partition。如果需要处理的partition存在于某个worker的内存中,或者partition的 preferred locations 为该worker,master便会发送这个task给该worker。
REFERENCE
[1] ZAHARIA M, CHOWDHURY M, FRANKLIN M J, 等. Spark: Cluster computing with working sets.[J]. HotCloud, 2010, 10(10–10): 95.
[2] ZAHARIA M, CHOWDHURY M, DAS T, 等. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//Presented as part of the 9th Symposium on Networked Systems Design and Implementation (12). 2012: 15–28.
[3] 夏俊鸾, 刘旭晖, 邵赛赛, 等. Spark大数据处理技术[M]. 电子工业出版社, 2014.
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/01/28/spark-rdd/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)