MapReduce编程模型实现了并行化,高容错的方式来处理大规模计算
MapReduce模型
在函数式编程语言中,map函数根据传入的函数对指定序列做映射,以参数序列中的每一个元素调用参数函数,返回包含每次参数函数返回值的新序列。reduce函数对序列中元素进行合并,用参数函数先对集合中的第1、2个元素进行操作,得到的结果再与第三个数据用参数函数运算,最后得到一个结果。
MapReduce模型受Lisp等函数式编程语言中的map和reduce方法启发。对数据中的每一条记录应用map操作,计算得到中间值key/value集合,然后对相同key的所有value应用reduce操作进行归并,就能得到最终结果。
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
上面的伪代码是对一个大文档集合进行词频统计。map函数输出文档中的每个词和这个词的出现次数的中间key/value集合。reduce函数把相同key的所有value都累加起来。这样就实现了一个符合MapReduce模型的词频统计。具体流程如下图所示。
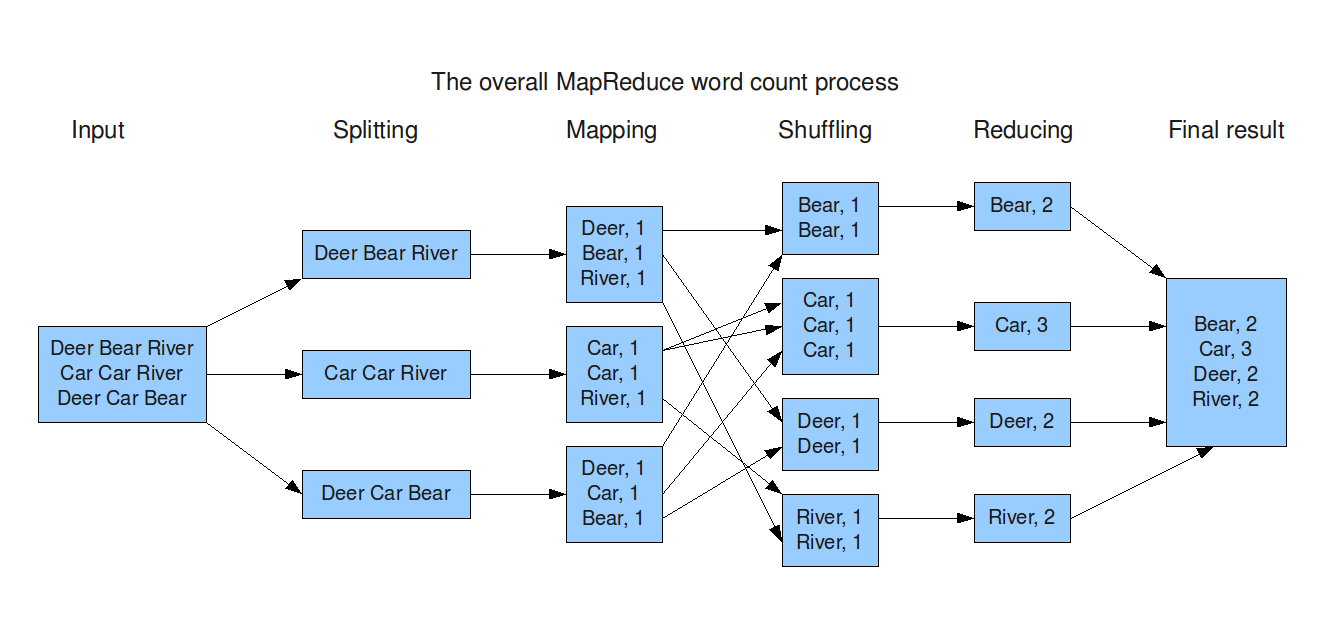
编程模型
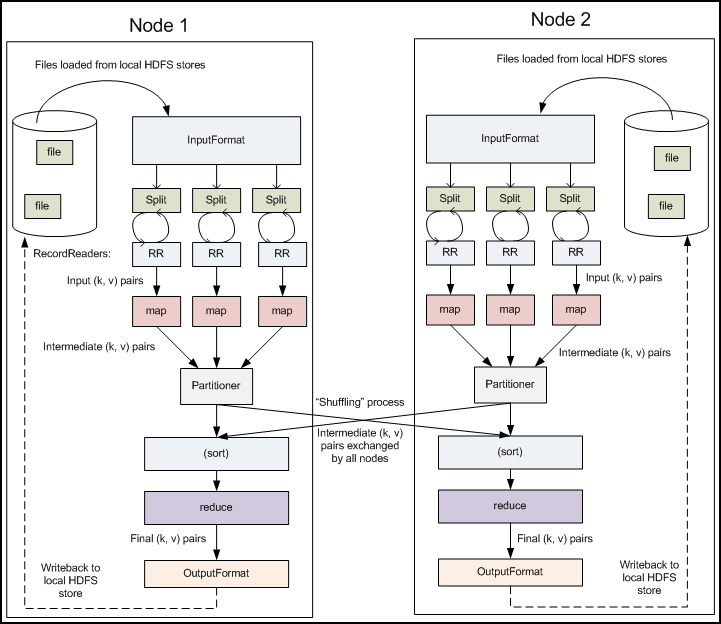
InputFormat:定义数据文件如何分割和读取,不同的子类会有不同分割和读取行为。- 选择文件或其他对象作为数据输入
- 构造
InputSplits, 对输入数据进行可序列化的逻辑切片 RecordReader工厂,将InputSplits转化为RecordReader
InputSplits:定义了输入到单个Map任务的输入数据- 可序列化:为了进程间通信
- 逻辑分片:在逻辑上对输入数据进行分片,并不会在磁盘上将其切分成分片进行存储。
lnputSplit只记录了分片的元数据信息,比如起始位置、长度以及所在的节点列表等
RecordReader:定义了将InputSplits的输入数据记录转化为一个键值对的详细方法。键值对会直接交给map函数处理Mapper:定义了具体的map函数- 每一个
Mapper类的实例都会生成一个Java进程 - 含有初始化和清理方法
- 每一个
Combiner:map端进行键值对的聚合- 合并过程类似
reduce,减少shuffle时候的数据通信开销
- 合并过程类似
Partitioner:对Mapper产生的中间键值对进行分片- 将同一分组的数据交给同一个
Reducer处理,影响Reducer的负载均衡 numReduceTask(分区数)值要大于1,否则不会执行
- 将同一分组的数据交给同一个
Shuffle:根据分区将中间键值对传递到指定reduce结点Sort:对所有传递到reduce结点上的键值对排序Reducer:定义了具体的reduce方法- 每一个
Reducer类的实例都会生成一个Java进程 - 含有初始化和清理方法
- 每一个
OutputFormat:描述输出数据的格式。- 每一个
Reducer的输出键值对将写入到同一个输出目录,文件名是part-nnnnn,对应着partition id
- 每一个
RecordWriter:将输出键值对写入到文件中
Shuffle过程
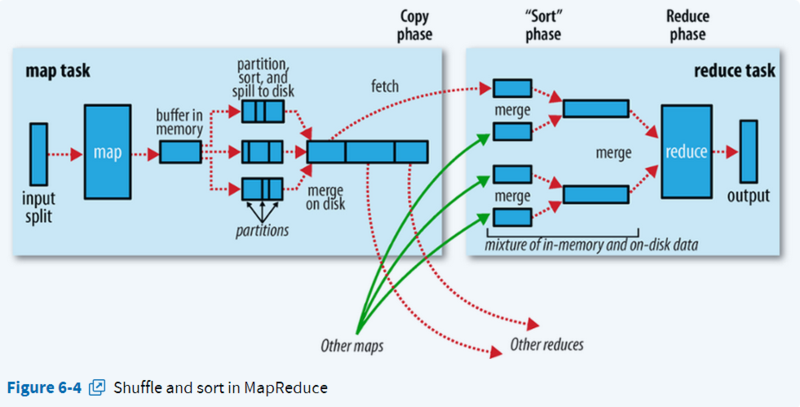
Shuffle按照partition、key对中间结果进行排序合并,输出给reduce线程。
Map端
- 写入缓存区
- 每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区的大小为100MB, 可通过
mapreduce.task.io.sort.mb属性来调整
- 每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区的大小为100MB, 可通过
- 溢出
- 一且缓冲内容达到阈值(
mapreduce.map.sort.spill.percent,默认为0.80), 一个后台线程便开始把内容溢出(spill)到磁盘。在溢出写到磁盘过程中,map输出继续写到缓冲区,但如果在此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成 - 线程通过新建溢出文件(spill file)的方式将内容spill到磁盘
- 在写磁盘之前,线程首先把数据划分成相应的分区。在每个分区中,后台线程按键进行内存中排序,然后执行
combiner
- 一且缓冲内容达到阈值(
- Merge溢出文件
- 如果至少存在3个溢出文件(
mapreduce.map.combine.minspills)时,则combiner就会在输出文件写到磁盘之前再次运行 - 如果溢出文件太多,可能会执行多次多路归并排序,每次最多能合并的文件数默认为10(
min.num.spills.for.combine)
- 如果至少存在3个溢出文件(
Reduce端
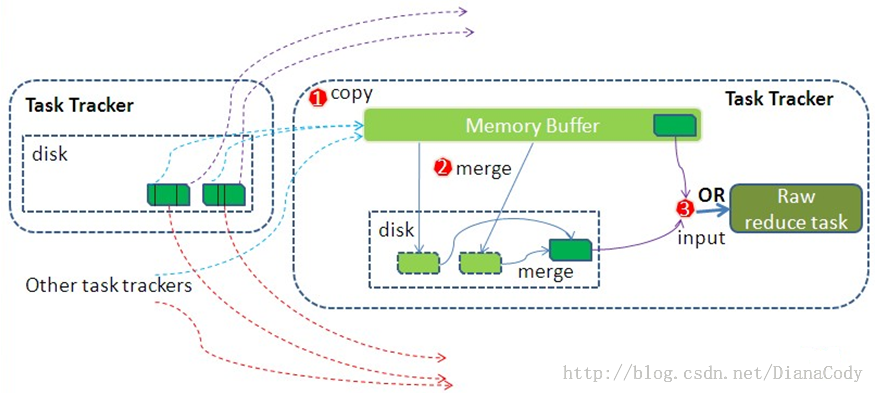
- 拉取数据
- 默认情况下,当整个MapReduce作业的所有已执行完成的Map Task任务数超过Map Task总数的5%后,JobTracker便会开始调度执行Reduce Task任务
- Reduce进程启动一些数据拉取线程,通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件
- 拉取的数据会首先保存的内存缓冲区中,当内冲缓冲区的使用率达到一定阀值后,则写到磁盘上
- merge
- 拉取数据时,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge
- 当内存缓存区的使用率达到一定阀值后,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。
combiner将在缓冲区中的数据合并写入磁盘之前运行 - 当属于所有map数据都拉取完成时,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge。最终Reduce shuffle过程会输出一个整体有序的数据块。
架构
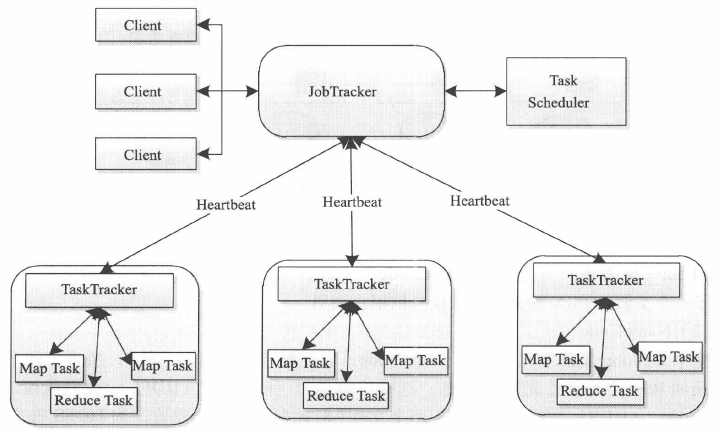
如图所示,为MR1的调度模块,在MR2中换成了YARN
Client
用户编写的MapReduce程序通过Client提交到JobTracker端。一个完整的mapreduce过程称为一个Job,每个Job在执行时会被分解成若干MapTask和ReduceTask。一个MapReduce程序中可能包含多个Job。
JobTracker
JobTracker负责资源监控和作业调度,相当于master结点。JobTracker监控所有TaskTracker与Task的健康状况,一旦发现失败情况后,其会将相应的Task转移到其他TaskTracker结点重新执行。同时,JobTracker会跟踪Task的执行进度、资源使用量等信息,并将这些信息传递给任务调度器,调度器会在资源出现空闲时,选择合适的Task使用这些资源。Yarn就是一种任务调度器。
TaskTracker
TaskTracker管理结点上运行的Task(MapTask或ReduceTask),相当于slave结点。TaskTracker会周期性地通过心跳将本节点上资源的使用情况和任务的运行进度汇报给JobTracker, 同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。
TaskTracker使用slot等量划分本节点上的资源量。slot代表计算资源(CPU 、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器将各个TaskTracker上的空闲slot分配给Task使用。slot分为Mapslot和Reduceslot,分别供MapTask和ReduceTask使用。TaskTracker通过slot数目限定Task的并发度。
MapTask
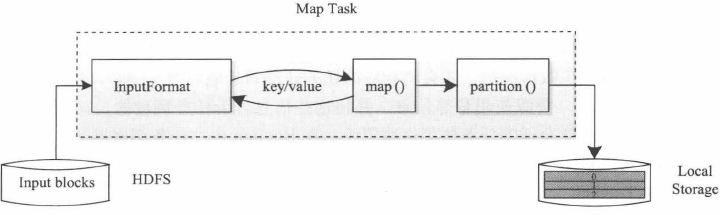
如图所示,输入数据由InputFormat进行处理,先进行逻辑分片InputSplits,再转化为键值RecordReader。接着,依次调用用户自定义的map()函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据经过Combiner聚合再由Partitioner被分成若干个分区。每个分区将被一个ReduceTask处理。
ReduceTask
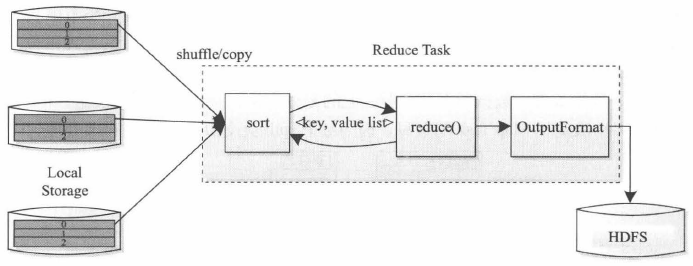
如图所示,首先从远程节点上读取MapTask中间结果(Shuffle);按照key对中间键值对进行排序(Sort);调用用户自定义的reduce()函数处理,并将最终结果存储。
本地存储
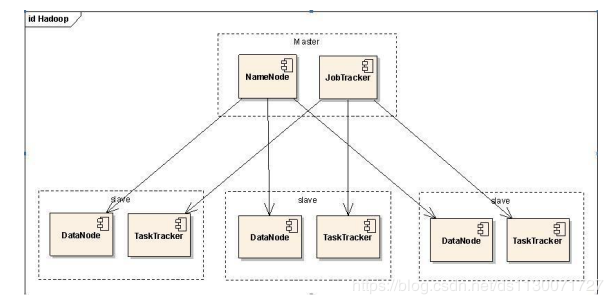
如图所示,每个MapTask的输入数据会尽量选择本地数据
推测执行
对快要完成的task且执行比预期缓慢,启动备份执行。当备份执行或者task完成,标记为完成,防止落后者出现。
REFERENCE
[1] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107–113.
[2] MapReduce Tutorial. [3] 董西成. Hadoop技术内幕[M]. 机械工业出版社, 2013.
[4] WHITE T. Hadoop权威指南(中文版)[M]. 周傲英, 译, 曾大聃, 译. 清华大学出版社, 2010.
[5] MapReduce之Shuffle过程详述
[6] MapReduce shuffle过程详解
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/02/27/mapreduce/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)