Hive是一个建立在Hapoop集群之上的数据仓库,依赖于HDFS的数据存储,依赖于MapReduce完成查询操作
数据仓库与数据库的区别
- 数据仓库:为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合
- 数据库:传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易
由以上定义可以看出数据库的应用主要是OLTP(On-Line Transaction Processing)。数据仓库系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,并且提供直观易懂的查询结果,为了查询的高效性。
Hive
由于MapReduce编程模型具有相对底层需要开发者写代码,难以重用和维护的缺点,所以出现了Hive,建立在Hapoop集群之上的数据仓库,支持类似SQL的声明式语言HiveQL,底层编译HiveQL为MapReduce作业在Hadoop集群上执行并返回运行结果。
数据模型
Table
Hive中的表类似关系型数据库中的表。表以目录的形式存储在HDFS上,表中数据被序列化并存储在对应目录下的文件中,用户可以将表与数据的序列化格式相关联。Hive提供了内置序列化格式并且实现了压缩和惰性反序列化功能。用户可自定义格式,但需要用Java语言实现序列化和反序列化方法(SerDe)。每个表的序列化格式存储在system catalog(Metastore)中,并由Hive在查询编译和执行期间自动使用。
Partition
每个表可以具有一个或多个分区,分区决定了表内的子目录分布。如果表T的数据存储在/wh/T中,T由其列ds 和 ctry 分区,那么一个ds字段的值为20090101并且ctry字段的值为US的数据将会存储在/wh/T/ds=20090101/ctry=US目录下的文件中。
Buckets
每个分区中的数据又可以根据表中某列的哈希值划分为多个Bucket。每个Bucket都作为文件存储在分区目录下。
查询语言
数据类型
- 基本类型
- Integers: bigint, int, smallint, tinyint
- Float: float, double
- String
- 集合:arrays and maps
- 复合类型:以上类型的嵌套
HiveQL
HiveQL支持DDL语句来创建具有序列化类型、分区和Buckets的表。用户可以从外部源加载数据,并分别通过load和insert(DML语句)将数据插入到Hive表中。但是目前HiveQL不支持更新和删除现有表中的行。HiveQL支持多表插入,用户可以使用单个HiveQL语句对同一输入数据执行多个查询,Hive通过共享输入数据来优化这些查询。
架构
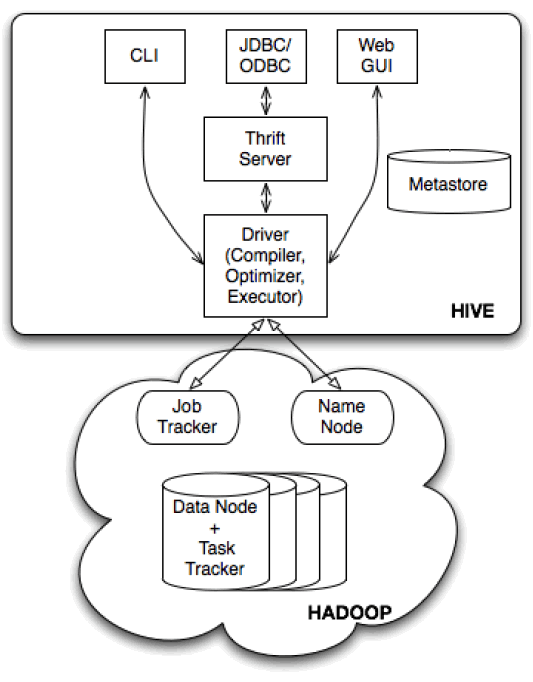
- 外部接口
- 命令行接口
- web UI
- 编程接口:ODBC,JDBC
- Thrift Server:暴露了一个简单的client API去执行HiveQL,允许远程客户端使用多种编程语言提交请求,取回结果
- Metastore:就是system catalog
- Driver:在编译,优化和执行期间管理HiveQL语句的生命周期。在从thrift服务器或其他接口接收HiveQL语句时,它会创建一个会话句柄,稍后用于跟踪执行时间,输出行数等统计信息
- Compiler:将HiveQL语句转换为由MapReduce作业的DAG组成的计划
- Optimizer:优化逻辑计划
- Execution Engine:以拓扑顺序将各个MapReduce作业从DAG提交到执行引擎
Metastore
Metastore中存储表的元数据。该元数据在表创建期间指定,并且每次在HiveQL中引用该表时都会重新使用。Metastore包含以下对象:
- Database,即表的命名空间。数据库default用于没有提供数据库名称时使用
- Table:还可以包含任何用户提供的键和值数据,可用于存储将来的表统计信息
- 列及其类型
- 所有者
- 存储:表数据在文件系统中的位置,数据格式和bucket信息
- SerDe:序列化器和反序列化器方法的实现类,以及该实现所需的任何支持信息
Metastore的存储系统应该适用于随机访问和更新在线事务。HDFS显然不满足,所以Metastore应该存储在传统的关系型数据库或者本地文件系统中。
Compiler
Driver使用Compiler编译HiveQL字符串,该字符串可以是DDL,DML或查询语句。Compiler将字符串转换为计划,包含DDL语句中的元数据操作,以及LOAD语句中的HDFS操作。对于插入和查询语句,plan由MapReduce作业的DAG组成。
- Parser将查询字符串转化为抽象语法树。
- Semantic Analyzer(语义分析器)将解析树转换为基于块的内部查询表示。从Metastore中检索输入表的模式信息,验证列名称,扩展select*并进行类型检查和添加隐式类型转换。
- Logical plan Generator将内部查询表示转换为逻辑计划,逻辑计划由逻辑运算符树组成。
- Optimizer多次遍历逻辑计划,重写逻辑查询计划。
- Physcial Plan Generator:将逻辑计划转换为由MapReduce作业组成的物理计划。逻辑计划中的标记运算符(repartition和union all)都将转化为一个MapReduce作业,标记之间的逻辑计划的部分由MapReduce作业的Mapper和Reducer完成。
REFERENCE
[1] THUSOO A, SARMA J S, JAIN N, 等. Hive: a warehousing solution over a map-reduce framework[J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1626–1629.
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/03/10/hive/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)