大数据系统中,一般采用同一数据多个副本保证可用性,这就带来了数据一致性问题。
原则
CAP
- 强一致性(consistency):对数据的操作在同一数据多副本与单副本的情况下一样
- 可用性(availability):读写在限定延时内完成
- 分区容忍性(partition tolerance):网络分区,分区间机器无法通信的情况下仍能继续工作
对于大规模分布式系统,只能实现其中两个。传统关系型数据库一般CA,NoSQL关注AP
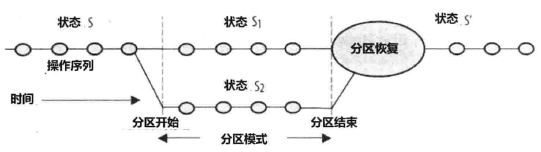
由于网络分区是小概率事件,在未产生网络分区的情况,应保证AC。发生网络分区时,系统可以识别出来并且进入分区模式,可能限制某些系统操作,最后网络分区解决后,恢复数据的一致性或弥补错误。
ACID
关系型数据库的采纳原则
- 原子性(Atomicity):事务的原子性,要么全部执行,要么完全不执行
- 一致性(Consistency):操作一致性
- 独立性(Isolation):允许事务的并行对数据读写。事务的执行互不影响
- 持久性(Durability):事务运行成功后,对系统的更新是永久的
BASE
牺牲一致性获得高可用,一般NoSQL和大数据系统采用
- 基本可用(Basically Available):系统绝大数时间可用,允许偶尔失败
- 柔性状态(Soft State):数据状态不要求在任意时刻完全同步
- 最终一致性(Eventual Consistency):弱一致性。给定时间窗口内数据达到一致状态
关系
未来将发展为全局BASE,局部ACID。当网络分区出现,分区内部保持ACID,问题解决后有助于恢复一致性。
ACID强调数据一致性,BASE强调可用性
幂等性
调用方反复执行统一操作与只正确执行一次操作效果相同
一致性模型
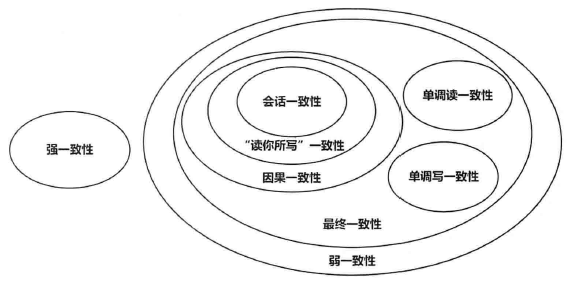
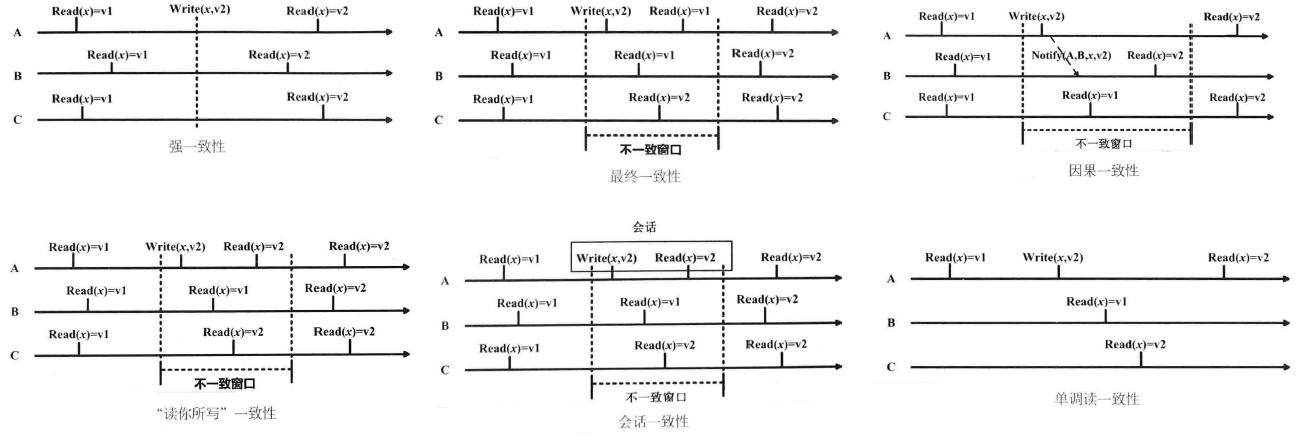
- 强一致性:对某个数据更新后,后续观察者应感知这次变化并以此为基础读写
- 弱一致性
- 最终一致性:需要时间段才能达到强一致性的性质(数据的副本同步需要时间)
- 因果一致性:具有依赖关系的进程才能保持一致性
- 读写一致性:自己保持一致性
- 会话一致性:在一个会话内保持一致性(如数据库连接),会话故障终止会导致非一致性
- 单调读一致性:读取的数据的版本在时间上只能变新
- 单调写一致性:保证多次写操作的序列化,写操作一致
多副本更新策略
同时更新
使用一致性协议预处理,不然并发情形下无法判断更新的先后顺序。请求延迟会增加。
主从式更新
主副本通知从副本更新,从副本的更新顺序由主副本决定
同步
- 写操作:主副本等待所有从副本更新完成后确认更新完成操作,确保数据强一致性,较大请求延时
- 读操作:所有读操作都要通过主副本来响应,确保数据强一致性,较大请求延时
异步
- 写操作:主副本在通知从副本前确认更新完成操作。若未通知就崩溃会出现数据不一致问题,通过日志记录解决。
- 读操作:任意一个副本都可以响应读请求,降低延迟,牺牲一致性
混合
- 写操作:主副本同步更新部分从副本后确认更新完成
- 读操作:RWN协议
任意结点更新
由任意结点通知其他副本更新
- 同步
- 异步
REFERENCE
- 大数据日知录
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/05/bigData-consistency/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)