简要介绍常用一致性协议。
2PC
Two-Phrase Commit 两阶段提交协议
实现事务原子性
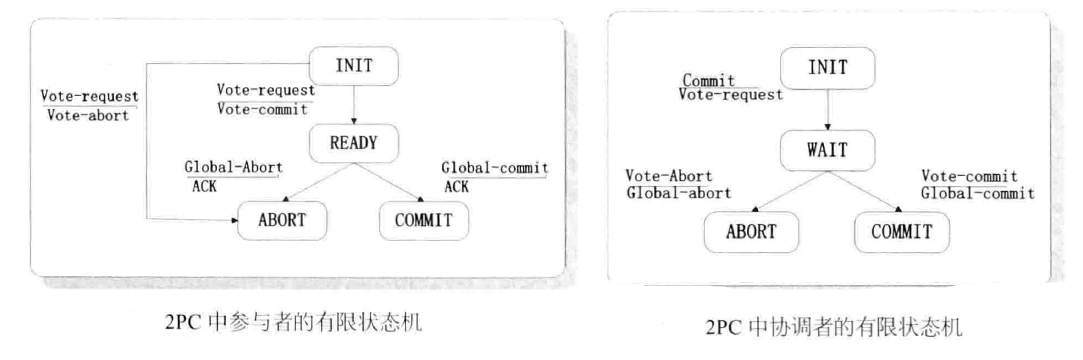
表决阶段
- 协调者
- 向所有参与者发送 VOTE_REQUEST 消息
- 参与者接收到 VOTE_REQUEST 消息后
- 返回 VOTE_COMMIT 告知协调者已做好提交准备
- 否则返回 VOTE_ABORT 消息告知尚无提交事务的可能
提交阶段
- 协调者
- 如果所有参与者都返回 VOTE_COMMIT ,则向所有参与者广播 GLOBAL_COMMIT 消息
- 如果存在 VOTE_ABORT 消息,则向所有参与者广播 GLOBAL_ABORT 消息
- 参与者
- 若接收到 GLOBAL_COMMIT 消息,本地提交
- 若接收到 GLOBAL_ABORT 消息,本地取消事务
阻塞情形
协调者的WAIT,参与者的INIT和READY状态,需要等待对方的反馈信息,进入阻塞态。
- 超时机制:解决协调者的 WAIT 和参与者的 INIT 状态长时间阻塞
- 协调者WAIT:协调者在一定时间内未收齐全部返回消息,可以假定存在崩溃或网络通信故障,广播 GLOBAL——ABORT
- 参与者INIT:参与者一段时间内未收到 VOTE_REQUEST,终止本地事务,发送 VOTE_ABORT
- 参与者互询:解决参与者 READY 状态长时间阻塞
- 参与者READY:询问其他参与者的状态,COMMIT->COMMIT,ABORT->ABORT,INIT->ABORT(超时),READY->继续询问其他参与者
3PC
Three-Phrase Commit 三阶段提交协议
3PC用来解决2PC中长时间阻塞,将提交阶段再细分为:预提交阶段和提交阶段。
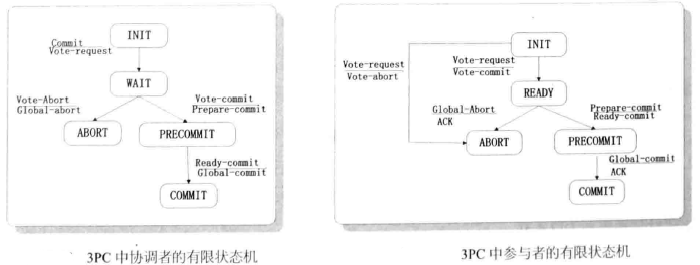
CanCommit
- 协调者
- 向所有参与者发送事务 VOTE_REQUEST 消息
- 进入WAIT状态
- 参与者收到 VOTE_REQUES 消息
- 如果可以执行事务,响应 VOTE_COMMIT ,进入READY状态
- 否则响应 VOTE_ABORT
PreCommit
- 协调者
- 如果所有参与者都返回 VOTE_COMMIT,则广播 PREPARE-COMMIT,进入PRECOMMIT状态
- 如果超时或者接收到 VOTE_ABORT ,则终止事务并发送 GLOBAL-ABORT
- 参与者
- 如果接收到 GLOBAL-ABORT 或者等待超时,则终止事务
- 如果接收到 PREPARE-COMMIT,则进入 PRECOMMIT 状态,执行事务操作,记录Undo和Redo日志,发送 READY-COMMIT
DoCommit
- 协调者
- 如果所有参与者都返回 READY-COMMIT,进入 COMMIT 状态,广播 GLOBAL-COMMIT。收到所有参与者的ACK后,完成事务
- 如果没有收到所有的 READY-COMMIT,则中断事务,广播 ABORT
- 参与者
- 如果收到 GLOBAL-COMMIT,则提交事务
- 如果收到 ABORT,则根据日志回滚
优缺点
降低了阻塞
- 参与者响应 VOTE_REQUEST 请求后,等待第二阶段指令,若等待超时,则自动中断事务
- 参与者响应 PREPARE-COMMIT 请求后,等待第三阶段指令,若等待超时,则自动中断事务
数据不一致
- 如果第三阶段协调者发出了 abort 请求,然后有些参与者没有收到 abort,那么就会自动 commit,造成数据不一致。
Vector Clock
向量时钟
保证分布式环境下生成事件之间偏序关系
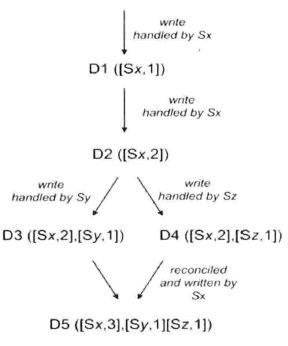
设 $n$ 个独立进程,每个进程 $p_i(1\le i \le n)$ 有初始值为0的整数向量时钟 $VC_i[1,\cdots,n]$ ,每一位表示 $p_i$ 看到其他进程的逻辑时钟,由此来判断事件的先后关系
规则
- 进程 $p_i$ ,产生发送消息,接收消息,内部事件,则 $VC_i[i]=VC_i[i]+1$
- 进程 $p_i$ 发送消息 $m$ 时,消息附带自己的向量时钟,记为 $m.VC$
- 进程 $p_i$ 接收到进程 $p_j$ 的消息 $m$ 时, $\forall VC_i[x]=max(VC_i[x],VC_j[x])$
因果关系
- 事件E先于事件F:$(\forall k:E.VC[k]\le F.VC[k])\ and\ (\exists k:E.VC[k]<F.VC[k])$
- 冲突:在Dynamo中,如果遇到不能判断因果关系的向量时钟,则交由客户端去解决并增加新的时钟
RWN模型
- N:备份的数据量(复制因子)
- W:一次成功的更新操作要求至少有W份数据写入成功
- R:一次成功的读取数据要求至少有R份数据成功读取
如果 $R+W>N$ ,则满足数据一致性协议
例子
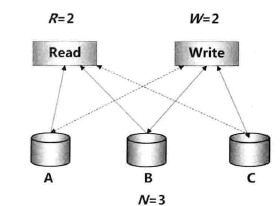
如果 $R+W>N$ ,读与写操作一定存在交集,一定能读到最新的数据。但是,R,W越大,系统延迟越大;改变R,W的值可以调整为读延迟高或者写延迟高。在Dynamo中,应用了RWN和向量时钟保证一致性。
Paxos
副本状态机
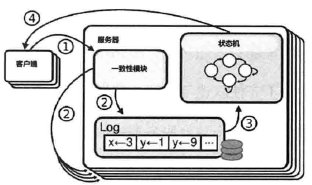
- 集群中每台服务器保存Log副本和内部状态机
- Log顺序记录客户端的操作指令,Log内的指令会提交到状态机上
- 一致性模块保证Log副本数据的一致性,从而所有服务器(及时发生故障)都能以同样的顺序执行同样的指令,最终的状态也是一致的
拜占庭错误
- 非拜占庭错误:出现故障(不响应)但不会伪造信息的情况称为非拜占庭错误(non-byzantine fault)
- 拜占庭错误:伪造信息恶意响应的情况称为拜占庭错误(Byzantine Fault),对应节点为拜占庭节点
角色
- 倡议者(Proposer):提出提议(数据操作命令)以投票
- 接受者(Acceptor):对倡议者的提议进行表决,选出唯一确定的
- 学习者(Learner):无投票权
单个进程可以同时承担多种角色
协议内容
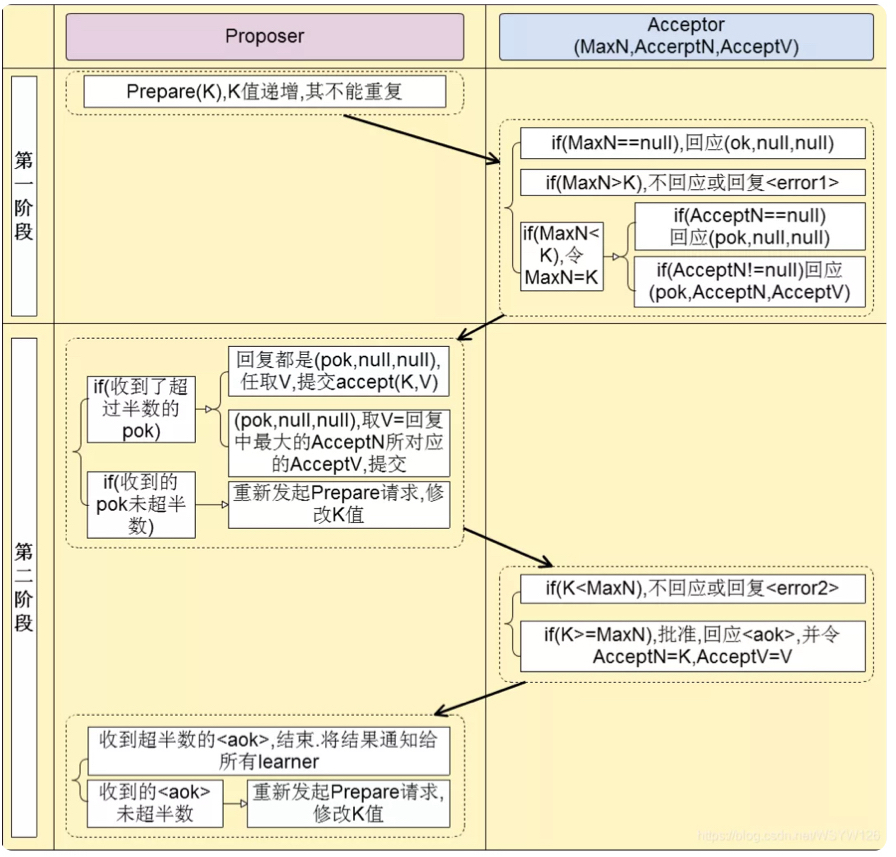
- 提出提议(第一阶段)
- 倡议者准备提议n,向半数以上的接受者发送Prepare(n)请求
- 接受者接收到Prepare(n)请求后,不再响应小于n的提议,并且对本次请求响应
- 接受者若响应过Accept请求 ,且响应编号小于n的最大提议(提议编号,提议值)
- 接收提议(第二阶段)
- 倡议者接收到半数以上响应,向响应的接受者发送Accept(n,v),否则重新发起Prepare(n)请求
- 倡议者将收到的接受者响应中,编号最大的提议值作为本次提议值,否则可以为任意值
- 接受者接收Accept(n)请求,除非收到编号更大的Prepare请求*
- 学习者
- 接收者在接收Accept请求后,通知所有学习者,触发大量网络通信
- 学习者中选出若干代表,用于接收 接受者的通知,再通知其他学习者
Raft
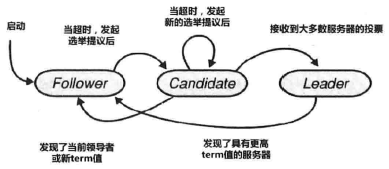
服务器状态
- Leader:集群中唯一,负责响应客户端请求,向Follower同步日志
- Follower:被动接收RPC消息,在Leader告之日志可以提交之后,提交日志
- Candidate:Follower->Leader中间状态
时间序列
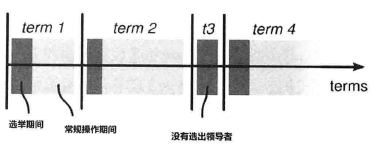
- 将整个系统执行时间划分为不同时间间隔的时间片构成的序列,每个时间片由Term+递增数字标识
- 每个term以选举期间(election) 开始,选举出来的服务器会在term剩下的时间作为leader
选举
使用心跳机制触发leader选举。leader通过周期心跳维持领导者地位。若Follower在选举超时时间内未收到心跳信息,则引发选举
Follower增加Term编号,转入Candidate状态,向其他服务器发送 RequestVote RPC,会出现以下情况
- 赢得选举,向其他服务器发送心跳,成为Leader。投票者只能投给一个相同Term的服务器
- 接收到其他服务器成为Leader的RPC。若对方的Term编号大于等于自身的,则承认,否则维持Candidate状态
- 超时,每个Candidate随机超时时间后,增加Term编号,进入下一个选举过程。防止选票分流(过多Candidate)
Log同步
- Leader接收客户端请求,并在Log尾部追加内容,向集群发送 AppendEntries RPC
- 当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机(提交)并向客户端返回执行结果
- 某些Followers可能没有成功的复制日志,Leader会无限的重试 AppendEntries RPC直到所有的Followers最终存储了所有的日志条目
日志
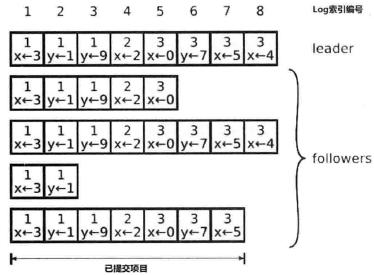
日志包含以下部分
- 操作指令
- Term编号
- Log全局索引
一致性保证
- 如果不同日志中的两个条目有着相同的索引和term编号,则它们所存储的命令是相同的
- Leader在一个term内在给定的一个log索引最多创建一条日志条目,同时该条目在日志中的位置也从来不会改变
- 如果不同日志中的两个条目有着相同的索引和term编号,则它们之前的所有条目都是完全一样的
- AppendEntries的一致性检查。当发送一个 AppendEntries RPC时,Leader会把新日志条目紧接着之前的条目的log index和term都包含在里面。如果Follower没有在它的日志中找到log index和term都相同的日志,它就会拒绝新的日志条目
不一致与安全性
在leader提交操作期间,Follower失效没能同步日志,在Follower被选为Leader时,就可能产生日志不一致的情况。Leader会从后往前试,每次AppendEntries失败后尝试前一个日志条目,直到成功找到每个Follower的日志一致位点,然后向后逐条覆盖Followers在该位置之后的条目。
有以下两点安全性要求
- 拥有最新的已提交的log entry的Follower才有资格成为Leader
- Candidate在发送RequestVote RPC时,要带上自己的最后一条日志的term和log index,比较顺序为term、index,若本地更新则拒绝投票
- 落后的Follower不会被选举为Leader
- 新leader只有提交过当前Term的操作,才能算真正提交
- Leader只能推进commit index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index 小于 commit index的日志被间接提交)
- 已提交日志不会被覆盖
如下图示的一个例子
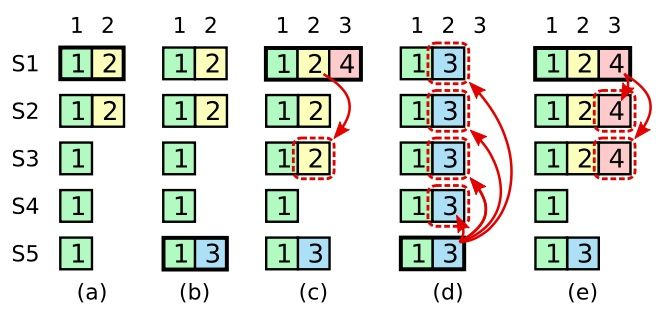
- 阶段a,term=2,S1是Leader。S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2
- 阶段b,term=3,S5为新的Leader。S5写入了日志(3, 2)
- 阶段c,term=4,S1为新的Leader。S1写入日志(3, 4),同步日志(2, 2)同步到了S3,此时由于该日志已经被同步到了多数节点(S1, S2, S3),所以日志(2,2)可以被提交了
- 阶段d,term=5,S5为新的Leader( S5的最新的日志为(3, 2),比大多数节点(如S2/S3/S4的日志)都新)。S5会将自己的日志覆盖到Followers,于是S2、S3中已经被提交的日志(2, 2)被截断了
增加安全性第二条限制之后。阶段c中,即使日志(2, 2)已经被大多数节点(S1、S2、S3)确认了,但是它不能被提交,因为它是来自之前term(2)的日志,直到S1在当前term(4)产生的日志(4, 4)被大多数Followers确认,S1才能可提交日志(4, 4)这条日志及其之前的日志,如阶段e所示。此时即使S1再下线,重新选主时S5不可能成为Leader,因为它没有包含大多数节点已经拥有的日志(4, 4)
REFERENCE
- 大数据日知录
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/05/bigData-consistency-protocol/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)