大数据背景下,传统纵向拓展的方式即增加机器的配置已经无法满足数据量的需要,因此主流大数据系统基本采用横向拓展即增加机器数量,对数据的分片与路由显得尤为重要。
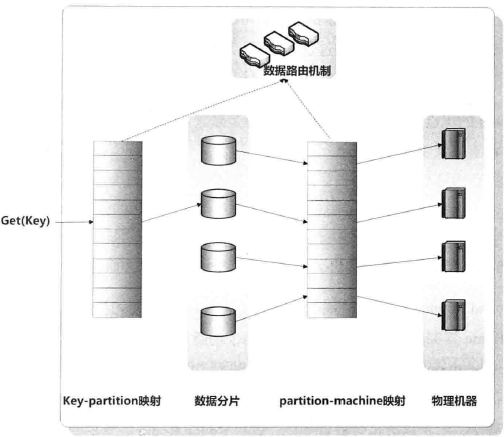
分片模型
key-partition映射:数据记录映射到分片空间,多对一partition-machine映射:分片映射到物理机器,多对一
做数据路由时,首先根据key-partition找到对应的分片,再根据partition-machine找到对应的机器。
哈希分片
有利于点查询。
Round Robin
H(key)=hash(key) mod K
直接将数据映射到物理机,缺乏灵活性
- 物理机的拓展,需要改变映射函数
- 物理机的拓展,会破坏原有映射关系
Virtual Buckets
- 哈希函数,数据记录和bucket的映射
- 表格记录,bucket和物理机的映射
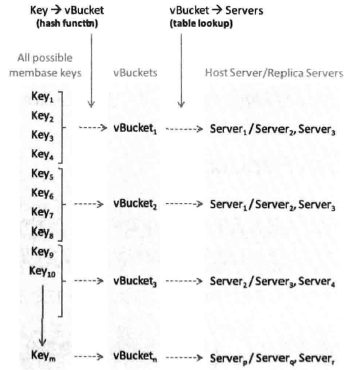
虚拟桶对应分片空间,新机器加入只需修改partition-machine就能完成拓展。
一致性哈希
分布式哈希(DHT)是哈希表的拓展,考虑多机分布环境,在每台机器负载部分数据的存储情形下,通过哈希方式对数据进行增删改查。
一致性哈希是DHT的一种实现方式,下面介绍Chord系统中提出的一致性哈希算法。将哈希空间切分,每个物理结点保存一定范围的数据记录。如图所示,N14保存6~14(哈希值)的数据,N20保存15~20的数据。
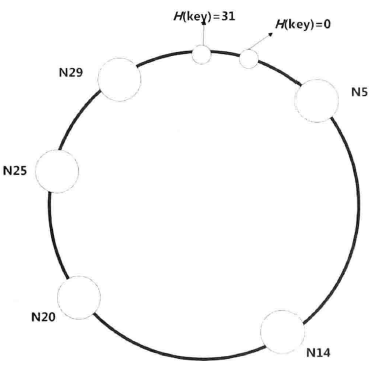
路由算法
- 机器接收到查找请求,先在本地查找,不存在则发送到下一台机器查找
- 每个机器保存路由表(哈希空间的二进制比特位长度大小的路由表)来加快查找速度,找到小于查找key的最大编号结点。
- 如下图所示为N14结点上的路由表,若查找的key=27,则应该发送到N25结点上(14+8<27<14+16)。N25会查找它的路由表发送到N29上,并返回查找值。

新结点加入
在不考虑并发的情况下,
- 新结点 $N_{new}$ 加入,与当前网络中任意结点 $N_x$ 建立联系。
- 由其哈希值 $new$ 通过路由算法找到其后继结点 $N_s$,因为 $N_{new}$ 需要存储的数据目前存储在 $N_s$ 上
- 周期性检查改变结点上的路由表
- 将 $N_s$ 上的部分数据迁移到 $N_{new}$ 上
旧结点离开
- 正常离开,将数据迁移到后继结点上,周期性检查更新路由表
- 异常离开,会导致数据丢失,通过副本的方式解决
虚拟结点
将高性能的机器虚拟成若干虚拟结点,使整体机器在环状结构中分布均匀(新加入时),同时考虑到机器的异质性。
Range Partition
主键排序,主键空间划分为多个分片,每个分片映射到一台物理机上。有利于范围查询
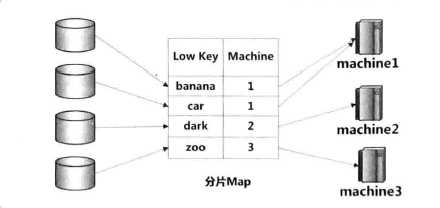
分片映射表一般采用LSM树
REFERENCE
- 大数据日知录
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/05/bigData-split/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)