介绍大数据中的常用压缩和哈希算法
LZSS
LZ77是一种动态词典编码,用字典中的号码代替文本中的词的无损压缩形式。静态词典编码技术,编码器需要事先构造词典;而动态词典编码技术,编码器从被压缩文本中自动导出词典。
LZSS压缩算法使用滑动窗口和前向缓冲区。滑动窗口包含已处理的若干源字符,前向缓冲区包含输入数据流中要处理的所有后续字符。
前向缓冲区开始字符串和滑动窗口中的字符串进行最长匹配,保存滑动窗口中子串的哈希用于匹配
如果没有匹配,则前向缓冲区输出第一个字符并移入滑动窗口
如果找到匹配并且大于最小匹配长度,则将匹配字符串作为
<匹配字符串起始位置差值,长度>输出并全部移入滑动窗口
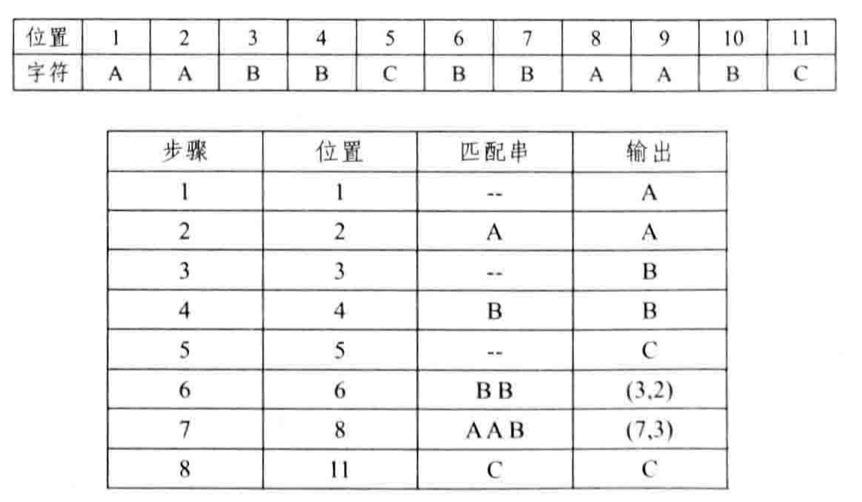
如下图所示,一个实例压缩过程。假设滑动窗口大小为10,最小匹配长度为2
Snappy
Google开源出的高效数据压缩与解压缩算法,在合理的压缩率基础上追求尽可能块的压缩和解压缩。基本遵循LZSS的压缩和解码方案。设定最小匹配长度为4,哈希表的子串长度固定为4,滑动窗口每次移动的长度为4。此外在压缩数据时分割为32KB大小的数据块分别压缩,这样两个字节即可表示匹配字符串的相对位置
Cuckoo Hashing
有效解决哈希冲突。使用两个哈希函数以解决哈希冲突的问题,优化方法可以是使用多个哈希函数,对桶进行开拉链。下面是插入的伪代码
# H1 H2 为两个不同的哈希函数
# T1 T2 对应存放哈希值的数组
insert(x)
# 已存在x
if T1[H1[x]] == x || T2[H2[x]] == x:
return
# 最大循环次数
while i < maxLoop:
# 放入第一个哈希桶中,如果有则将里面的元素挤出
if T1[H1[x]] == NULL:
T1[H1[x]] = x
return
x <--> T1[H1[x]] # 交换
# 第一个桶中被挤出的元素放入第二个哈希桶中,如果有则将里面的元素挤出
if T2[H2[x]] == NULL:
T2[H2[x]] = x
return
x <--> T2[H2[x]] # 交换
i++
# 找不到桶,则增加桶数量,重新插入
rehash()
insert(x)
REFERENCE
- 大数据日知录
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/06/bigData-alg/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)