介绍用于block的标识信息,数据信息,元数据和锁管理
标识信息
BlockManagerId
每个BlockManager的唯一标识,通过以下属性来区分
host: 主机域名或IPport:BlockManager中的BlockTransferService对外服务的端口executorId: 如果实例是Driver,那么ID为Driver,否则由Master负责给各个Executor分配,ID格式为app-日期格式字符串-数字。topologyInfo: 拓扑信息
BlockId
每个block的唯一标识,案例类,只有name属性和以下方法
sealed abstract class BlockId {
def name: String
def asRDDId: Option[RDDBlockId] = if (isRDD) Some(asInstanceOf[RDDBlockId]) else None
def isRDD: Boolean = isInstanceOf[RDDBlockId]
def isShuffle: Boolean = isInstanceOf[ShuffleBlockId]
def isBroadcast: Boolean = isInstanceOf[BroadcastBlockId]
override def toString: String = name
}
有许多子类如RDDBlockId、ShuffleBlockId、BroadcastBlockId等,定义都类似如下所示
case class RDDBlockId(rddId: Int, splitIndex: Int) extends BlockId {
override def name: String = "rdd_" + rddId + "_" + splitIndex
}
数据信息
BlockResult
用于封装从本地的BlockManager中获取的Block数据的迭代器。包含以下成员变量
data: block数据及block度量数据。readMethod: 读取Block的方法。readMethod采用枚举类型DataReadMethod提供的Memory、Disk、Hadoop、Network四个枚举值。bytes: 读取的Block的字节长度。
BlockData
这是一个接口,定义了block的存储方式以及提供不同方式去读取底层的block数据
有三个实现类
DiskBlockData: 用于将磁盘中的block文件(File对象)转换为指定的流,ByteBuffer或者ChunkedByteBuffer(不连续的小chunk)EncryptedBlockData: 相对于DiskBlockData做了一层解密ByteBufferBlockData: 维护了在内存中的block,对ChunkedByteBuffer的一个封装
ManagedBuffer
这是一个接口,提供一个不可变的数据视图。 有以下实现类
FileSegmentManagedBuffer: 维护了文件中某一段的数据BlockManagerManagedBuffer: 包装了从BlockManager获得的BlockData实例EncryptedManagedBuffer:EncryptedBlockData的代理类,几乎将所有请求都委托给了EncryptedBlockDataNioManagedBuffer: 维护了 NIO ByteBuffer 的数据NettyManagedBuffer: 维护了 Netty ByteBuffer 的数据
元数据
BlockInfo
block的元数据信息。包含以下重要成员变量
level: 存储级别,即StorageLevel。classTag: 块类型。用于选择序列化器。tellMaster: block状态改变是否需要告知Master。广播block是false,大多数block是true。size: block的大小。readerCount: block被锁定读取的次数。writerTask: 任务尝试在对block进行写操作前,首先必须获得对应BlockInfo的写锁。用于保存任务attempt的ID(每个任务在实际执行时,会多次尝试,每次尝试都会分配一个ID)。
BlockStatus
用于封装block的状态信息,案例类。包含以下成员变量
storageLevel:存储级别。memSize: block占用的内存大小。diskSize: block占用的磁盘大小。isCached: 是否存储到存储体系中,即memSize与diskSize的大小之和是否大于0。
BlockInfoManager
对BlockInfo和block的锁资源进行管理,采用了共享锁与排他锁,其中读锁是共享锁,写锁是排他锁。主要有以下重要成员属性
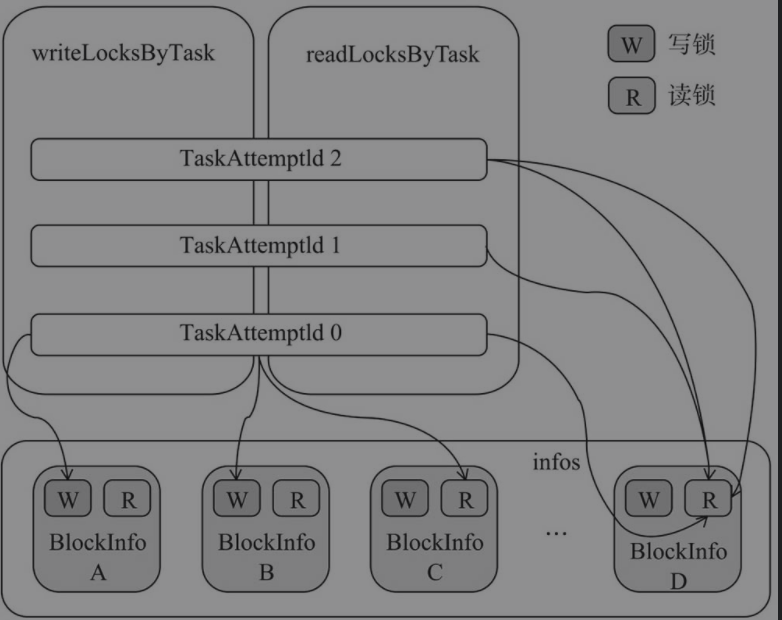
TaskAttemptId: 任务attempt的IDinfos:BlockId和BlockInfo的映射关系writeLocksByTask: 任务attempt的ID和获得写锁的BlockId的对应关系,类型为mutable.HashMap[TaskAttemptId, mutable.Set[BlockId]] with mutable.MultiMap[TaskAttemptId, BlockId],是一对多的关系。MutiMap特质提供了一种便捷方式去处理一对多的MapreadLocksByTask: 任务attempt的ID和获得读锁的BlockId的对应关系。类型为mutable.HashMap[TaskAttemptId, ConcurrentHashMultiset[BlockId]],ConcurrentHashMultiset可以允许插入重复的元素并保留计数,所以每个任务可以多次获得同一个block的读锁,读锁是可重入的
如下图所示展示读锁和写锁的管理过程,同一个任务不能同时获取到同一个block的读锁和写锁。
下面是一些重要方法
registerTask(): 注册TaskAttemptId,这个方法必须在调用此类的其他方法前调用def registerTask(taskAttemptId: TaskAttemptId): Unit = synchronized { require(!readLocksByTask.contains(taskAttemptId), s"Task attempt $taskAttemptId is already registered") readLocksByTask(taskAttemptId) = ConcurrentHashMultiset.create() }currentTaskAttemptId(): 获取TaskContext中正在执行任务的TaskAttemptId,若没有返回BlockInfo.NON_TASK_WRITERlockForReading(): 获得block的读锁并返回元信息- 使用
synchronized保证并发安全 - 在
infos中由BlockId获取BlockInfo,判断是否有其他任务已经获取了写锁 - 如果没有就在
readLocksByTask增加记录并返回BlockInfo - 如果有且允许阻塞(
blocking=true),则循环等待其他任务释放写锁,当前线程可能出现饥饿一直等待下去
def lockForReading( blockId: BlockId, blocking: Boolean = true): Option[BlockInfo] = synchronized { logTrace(s"Task $currentTaskAttemptId trying to acquire read lock for $blockId") do { infos.get(blockId) match { case None => return None case Some(info) => if (info.writerTask == BlockInfo.NO_WRITER) { info.readerCount += 1 readLocksByTask(currentTaskAttemptId).add(blockId) logTrace(s"Task $currentTaskAttemptId acquired read lock for $blockId") return Some(info) } } if (blocking) { wait() } } while (blocking) None }- 使用
lockForWriting(): 获得block的写锁并返回元信息- 使用
synchronized保证并发安全 - 在
infos中由BlockId获取BlockInfo,判断是否有其他任务已经获取了写锁或者读锁 - 如果没有就在
writeLocksByTask增加记录并返回BlockInfo - 如果有且允许阻塞(
blocking=true),则循环等待其他任务释放写锁,当前线程可能出现饥饿一直等待下去
def lockForWriting( blockId: BlockId, blocking: Boolean = true): Option[BlockInfo] = synchronized { logTrace(s"Task $currentTaskAttemptId trying to acquire write lock for $blockId") do { infos.get(blockId) match { case None => return None case Some(info) => if (info.writerTask == BlockInfo.NO_WRITER && info.readerCount == 0) { info.writerTask = currentTaskAttemptId writeLocksByTask.addBinding(currentTaskAttemptId, blockId) logTrace(s"Task $currentTaskAttemptId acquired write lock for $blockId") return Some(info) } } if (blocking) { wait() } } while (blocking) None }- 使用
unlock(): 释放block的读锁和写锁。一般lock()和unlock()是成对使用的,所以是释放当前任务获得的读锁和写锁- 由
BlockId获得BlockInfo - 如果当前任务获得了block的写锁,则释放当前block的写锁
- 否则,释放一次当前任务获得的读锁
- 通知其他等待锁的线程
def unlock(blockId: BlockId, taskAttemptId: Option[TaskAttemptId] = None): Unit = synchronized { val taskId = taskAttemptId.getOrElse(currentTaskAttemptId) logTrace(s"Task $taskId releasing lock for $blockId") val info = get(blockId).getOrElse { throw new IllegalStateException(s"Block $blockId not found") } if (info.writerTask != BlockInfo.NO_WRITER) { info.writerTask = BlockInfo.NO_WRITER writeLocksByTask.removeBinding(taskId, blockId) } else { assert(info.readerCount > 0, s"Block $blockId is not locked for reading") info.readerCount -= 1 val countsForTask = readLocksByTask(taskId) val newPinCountForTask: Int = countsForTask.remove(blockId, 1) - 1 assert(newPinCountForTask >= 0, s"Task $taskId release lock on block $blockId more times than it acquired it") } notifyAll() }- 由
downgradeLock(): 写锁降级为读锁def downgradeLock(blockId: BlockId): Unit = synchronized { logTrace(s"Task $currentTaskAttemptId downgrading write lock for $blockId") val info = get(blockId).get require(info.writerTask == currentTaskAttemptId, s"Task $currentTaskAttemptId tried to downgrade a write lock that it does not hold on" + s" block $blockId") unlock(blockId) val lockOutcome = lockForReading(blockId, blocking = false) assert(lockOutcome.isDefined) }lockNewBlockForWriting(): 写新block时尝试获得写锁- 尝试获得block的读锁
- 如果能够获得,说明block已存在,就没必要再获得写锁
- 如果不能获得,则在
infos放入新的映射关系并获得写锁
def lockNewBlockForWriting( blockId: BlockId, newBlockInfo: BlockInfo): Boolean = synchronized { logTrace(s"Task $currentTaskAttemptId trying to put $blockId") lockForReading(blockId) match { case Some(info) => // Block already exists. This could happen if another thread races with us to compute // the same block. In this case, just keep the read lock and return. false case None => // Block does not yet exist or is removed, so we are free to acquire the write lock infos(blockId) = newBlockInfo lockForWriting(blockId) true } }releaseAllLocksForTask(): 释放任务的持有的所有锁并通知等待锁的线程def releaseAllLocksForTask(taskAttemptId: TaskAttemptId): Seq[BlockId] = synchronized { val blocksWithReleasedLocks = mutable.ArrayBuffer[BlockId]() val readLocks = readLocksByTask.remove(taskAttemptId).getOrElse(ImmutableMultiset.of[BlockId]()) val writeLocks = writeLocksByTask.remove(taskAttemptId).getOrElse(Seq.empty) for (blockId <- writeLocks) { infos.get(blockId).foreach { info => assert(info.writerTask == taskAttemptId) info.writerTask = BlockInfo.NO_WRITER } blocksWithReleasedLocks += blockId } readLocks.entrySet().iterator().asScala.foreach { entry => val blockId = entry.getElement val lockCount = entry.getCount blocksWithReleasedLocks += blockId get(blockId).foreach { info => info.readerCount -= lockCount assert(info.readerCount >= 0) } } notifyAll() blocksWithReleasedLocks }assertBlockIsLockedForWriting(): 断言当前Task是否持有块的写锁get(): 不获取任何锁的情况下,获得block的元信息。这个方法只暴露给BlockManager.getStatus()removeBlock(): 删除block并释放读锁和写锁。只有持有写锁的任务才能调用这个方法def removeBlock(blockId: BlockId): Unit = synchronized { logTrace(s"Task $currentTaskAttemptId trying to remove block $blockId") infos.get(blockId) match { case Some(blockInfo) => if (blockInfo.writerTask != currentTaskAttemptId) { throw new IllegalStateException( s"Task $currentTaskAttemptId called remove() on block $blockId without a write lock") } else { infos.remove(blockId) blockInfo.readerCount = 0 blockInfo.writerTask = BlockInfo.NO_WRITER writeLocksByTask.removeBinding(currentTaskAttemptId, blockId) } case None => throw new IllegalArgumentException( s"Task $currentTaskAttemptId called remove() on non-existent block $blockId") } notifyAll() }
REFERENCE
- Spark内核设计的艺术:架构设计与实现
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/08/store-blockInfo/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)