简述Spark SQL中对SQL语句的解析原理
ANTLR
ANTLR(Another Tool for Language Recognition)是,基于LL(*)解析方式,使用自上而下的递归下降分析方法的语法生成工具。ANTLR通过自身的DSL语法描述来构造词法分析器、语法分析器和树状分析器等各个模块。
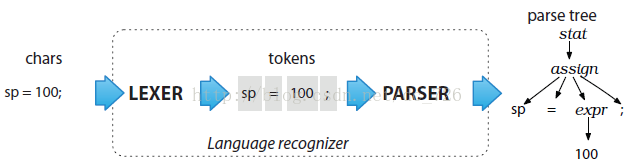
如下图所示,ANTLR是用来解析语言的程序,本身包含两个部分: 词法分析器(lexer)和语法分析器(parser)。词法分析阶段主要解决的关键词以及各种标识符,例如 INT、ID 等,语法分析主要是基于词法分析的结果,构造一颗语法分析树
语法
下面以带括号的四则计算器为例分析ANTLR4的语法
// 定义语法解析的名字,与文件名相同
grammar Calculator ;
// 其他配置, 如options, actions
/**
* 解析规则定义, 一般以小写下划线形式命名
*/
// line解析规则表示只解析文件结束符之前的部分
line : expr EOF ;
// # 表示产生式标签名,在解析树中显示
// 四个标签的先后顺序体现了四则运算的优先级
expr : '(' expr ')' # parenExpr
| expr ('*'|'/') expr # multOrDiv
| expr ('+' | '-') expr # addOrSubtract
| FLOAT # float ;
/**
* token定义, 一般以大写字符命名
*/
// 跳过\t \n \r
WS : [ \t\n\r]+ -> skip ;
// 定义了浮点数的解析规则
FLOAT : DIGIT+ '.' DIGIT* EXPONENT?
| '.' DIGIT+ EXPONENT?
| DIGIT+ EXPONENT? ;
// fragment表示这是个词片段,不会生成对应的Token
// [0-9]
fragment DIGIT : '0'..'9' ;
// 科学计数法的指数位, 正则表达式写法
fragment EXPONENT : ('e'|'E') ('+'|'-')? DIGIT+ ;
表达式(1.25e10 + 1.24e-10) * 5.1 / 10解析出来的抽象语法树如下所示

将上述代码保存为Calculator.g4,利用ANTLR4组件即可生成相应的Java代码,有以下两种遍历模式
Listener
观察者模式,通过结点监听,触发处理方法
- 不需要显示定义遍历语法树的顺序,实现简单
- 动作代码与文法产生式解耦,利于文法产生式的重用
- 没有返回值,需要使用map、栈等结构在节点间传值
- 缺点不能显示控制遍历语法树的顺序
下面代码展示了先序遍历抽象语法树,并且只打印AddOrSubtract和Float结点
import gen.CalculatorBaseListener;
import gen.CalculatorLexer;
import gen.CalculatorParser;
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class CalculatorListener extends CalculatorBaseListener {
@Override
public void enterAddOrSubtract(CalculatorParser.AddOrSubtractContext ctx) {
System.out.println(ctx.expr(0).getText() + ctx.getChild(1).getText() + ctx.expr(1).getText());
}
@Override
public void enterFloat(CalculatorParser.FloatContext ctx) {
System.out.println(Float.parseFloat(ctx.getText()));
}
/**
* 1.25e10+1.24e-10
* 1.24999997E10
* 1.24E-10
* 5.1
* 10.0
*/
public static void main(String[] args) {
String query = "(1.25e10 + 1.24e-10) * 5.1 / 10";
CalculatorLexer lexer = new CalculatorLexer(new ANTLRInputStream(query));
CalculatorParser parser = new CalculatorParser(new CommonTokenStream(lexer));
ParseTreeWalker walker = new ParseTreeWalker();
CalculatorListener listener = new CalculatorListener();
walker.walk(listener, parser.expr());
}
}
Visitor
访问者模式,主动遍历各个树节点
- 可以显示定义遍历语法树的顺序,直接对tree操作
- 动作代码与文法产生式解耦,利于文法产生式的重用
- visitor方法可以直接返回值,返回值的类型必须一致,不需要使用map这种节点间传值方式,效率高
下面代码展示了后序遍历抽象语法树,并且只打印AddOrSubtract和Float结点
import gen.CalculatorBaseVisitor;
import gen.CalculatorLexer;
import gen.CalculatorParser;
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
// visitxx()方法的默认实现时调用visitChildren()方法, visitChildren()方法里调用了所有子结点的accept()方法相当于向下递归调用了
public class CalculatorVisitor extends CalculatorBaseVisitor<Float> {
@Override
public Float visitAddOrSubtract(CalculatorParser.AddOrSubtractContext ctx) {
// accept()内部调用了访问者的visitxxx()方法,所以此处是递归用法
float leftNum = ctx.expr(0).accept(this);
float rightNum = ctx.expr(1).accept(this);
System.out.println(leftNum + ctx.getChild(1).getText() + rightNum);
return 0f;
}
@Override
public Float visitFloat(CalculatorParser.FloatContext ctx) {
System.out.println(Float.parseFloat(ctx.getText()));
return Float.parseFloat(ctx.getText());
}
/**
* 1.24999997E10
* 1.24E-10
* 1.24999997E10+1.24E-10
* 5.1
* 10.0
*/
public static void main(String[] args) {
String query = "(1.25e10 + 1.24e-10) * 5.1 / 10";
CalculatorLexer lexer = new CalculatorLexer(new ANTLRInputStream(query));
CalculatorParser parser = new CalculatorParser(new CommonTokenStream(lexer));
CalculatorVisitor visitor = new CalculatorVisitor();
visitor.visit(parser.expr());
}
}
SqlBase
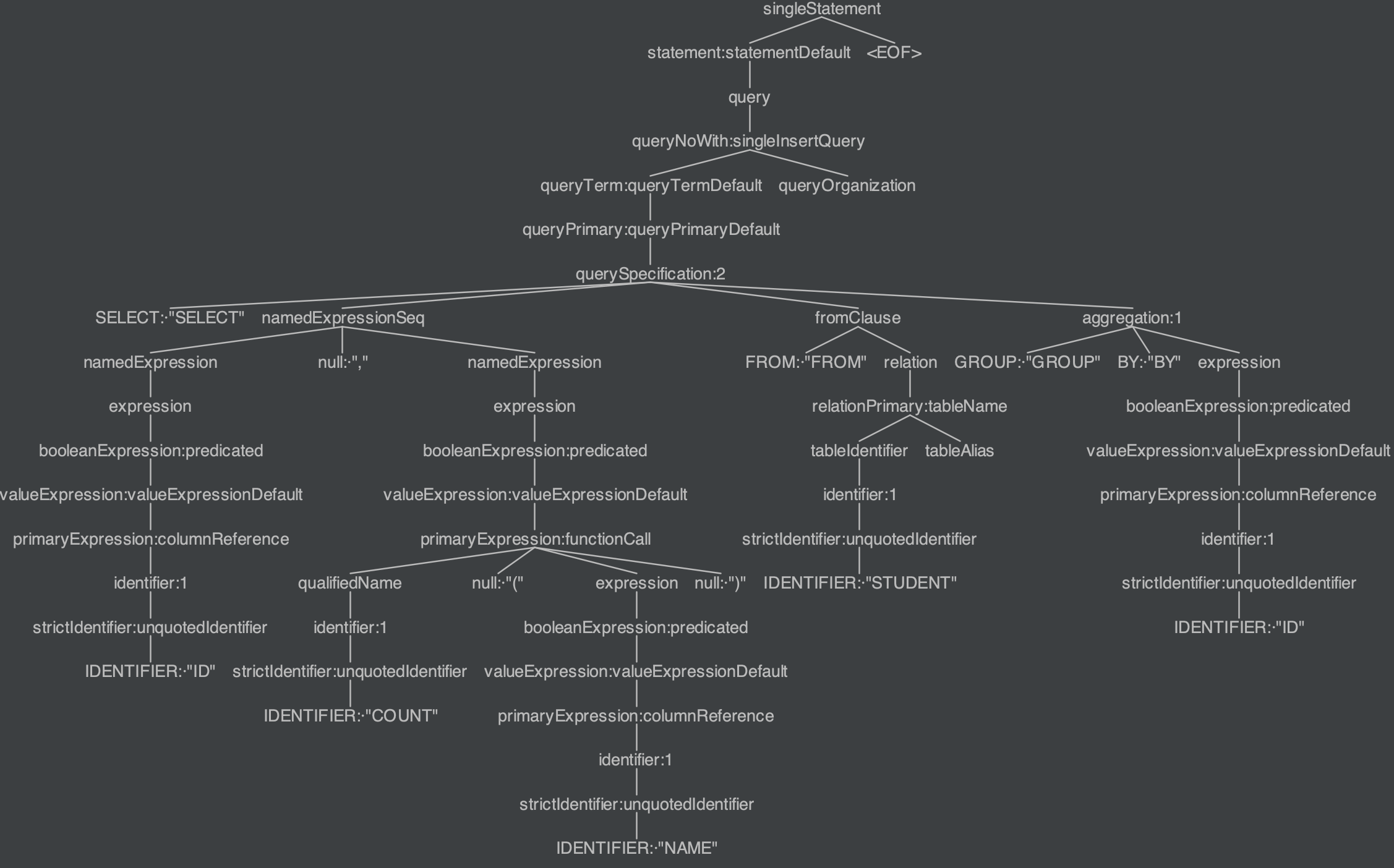
在Catalyst中,SQL语句经过解析,生成的抽象语法树节点都以Context结尾来命名。如下图所示,这里我们直接使用SqlBase.g4解析一条SQL语句SELECT ID, COUNT(NAME) FROM STUDENT GROUP BY ID,对于SqlBase.g4来说只能识别大写的标识符。
REFERENCE
- Antlr4 简介——icejoywoo
- Spark SQL内核剖析
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/10/20/spark-parser/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)