物理计划阶段,Spark SQL 根据逻辑算子树得到物理算子树。与逻辑计划的平台无关性不同,物理计划是与底层平台紧密相关的
物理计划流程
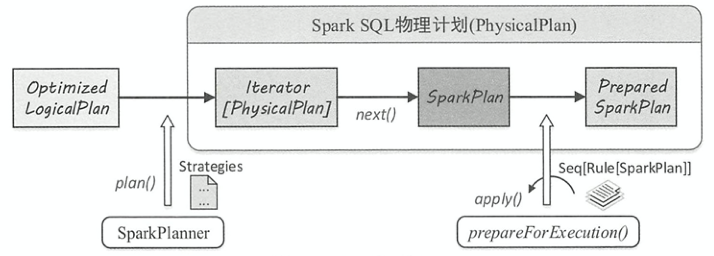
- 由
SparkPlanner将各种物理计划策略Strategy作用于对应的LogicalPlan节点上,生成SparkPlan列表。 - 直接调用
next()获取第一个计划 - 提交前进行准备工作,进行一些分区排序方面的处理,确保
SparkPlan各节点能够正确执行,这一步通过prepareForExecution()方法调用若干规则进行转换。
SparkPlan
在物理算子树中,叶结点类型的SparkPlan结点负责创建RDD,每个分支结点类型的SparkPlan结点等价于在 RDD上进行一次Transformation,即通过调用execute()函数转换成新的RDD,最终执行collect()操作触发计算,返回结果给用户。SparkPlan的继承体系如下图所示
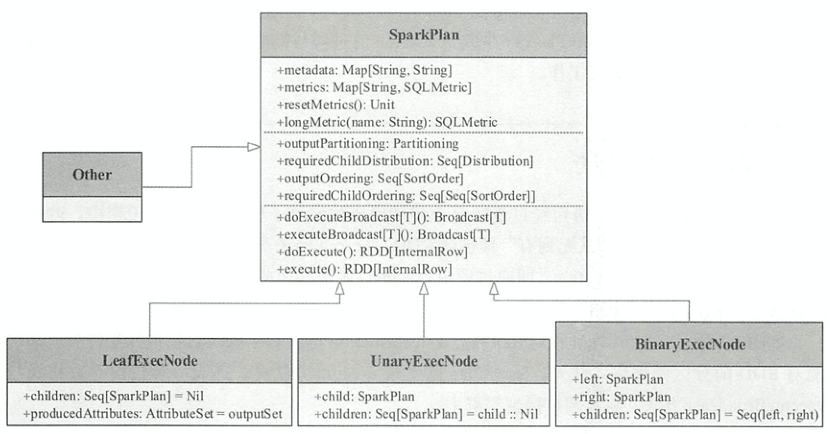
LeafExecNode
没有子结点的物理执行计划。如下图所示的继承关系LeafExecNode,负责对初始RDD的创建
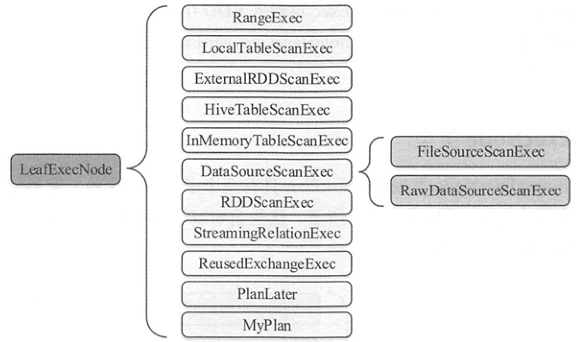
RangeExec: 利用SparkContext.parallelize()方法生成给定范围的RDDHiveTableScanExec: 根据Hive数据表存储的HDFS信息直接生成HadoopRDDFileSourceScanExec: 根据数据表所在的源文件生成FileScanRDD
UnaryExecNode
只有一个子结点的物理执行计划。UnaryExecNode结点的作用主要是对 RDD 进行转换操作
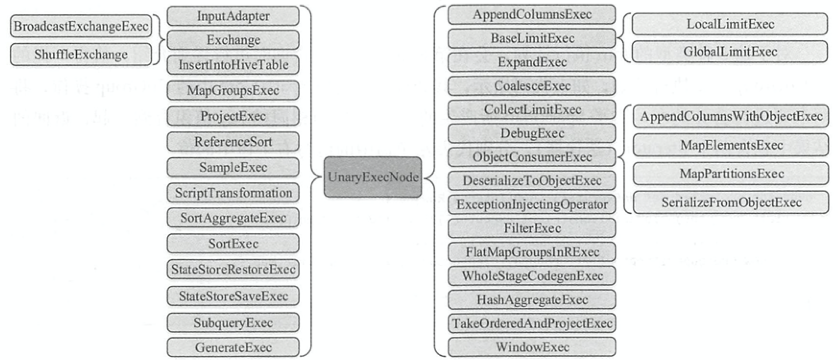
ProjectExec: 对子节点产生的 RDD 进行列剪裁FilterExec: 分别对子节点产生的 RDD 进行 行过滤Exchange: 负责对数据进行重分区SampleExec: 对输入 RDD 中的数据进行采样SortExec: 按照一 定条件对输入 RDD 中数据进行排序WholeStageCodegenExec: 将生成的代码 整合成单个 Java 函数
BinaryExecNode
有两个子结点的物理执行计划。除CoGroupExec外都是不同类型的 Join 执行计划。
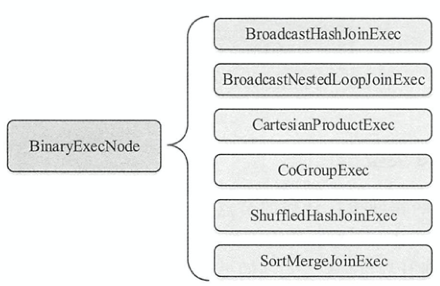
CoGroupExec算子将两个要进行合并的左、右子SparkPlan所产生的 RDD ,按照相同的 key 值组合到一起,返回的左右子树key对应值的聚合结果
其他
Metadata&Metrics
在某些SparkPlan的子类中使用Map[String, String]类型的变量metadata来存储元数据信息。一 般情况下,元数据主要用于描述数据源的 一 些基本信息,例如数据文件的格式、存储路径等。目前只有FileSourceScanExec和RowDataSourceScanExec两种叶结点物理计划对其进行了重载实现。
在SparkPlan的子类重载Map[String, SQLMetric]类型的变量metrics来存储指标信息。在 Spark 执行过程中,metrics能够记录各种信息,为应用的诊断和优化提供基础。
分区
SparkPlan.requiredChildDistribution()规定了当前SparkPlan所需的数据分布列表。在SparkPlan分区体系实现中,如下图所示,特质Partitioning表示对数据进行分区的操作,特质 Distribution 则表示数据的分布。Partitioning.satisfies()方法需要传入特质Distribution,判断Partitioning操作是否能满足所需的数据分布Distribution,即是否需要对数据进行重分区
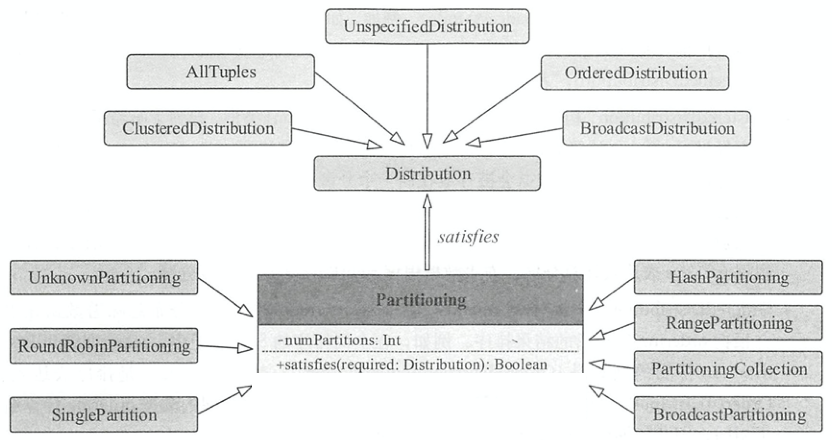
Distribution
定义了查询执行时,同一个表达式下的不同数据元组在集群节点上的分布情况。节点间分区信息,即数据元组在集群不同的物理节点上是如何分区的,可以用来判断聚合算子是否进行局部计算避免全局操作。分区数据内排序信息。有以下5种实现,实现了requiredNumPartitions属性和createPartitioning()方法
UnspecifiedDistribution: 未指定分布,无需确定数据元组之间的位置关系。调用createPartitioning()方法将抛出异常AllTuples: 只有一个分区,所有的数据元组存放在一起。调用createPartitioning()方法将返回构造的SinglePartitionBroadcastDistribution: 广播分布,数据会被广播到所有节点上。构造参数为广播模式,原始数据IdentityBroadcastMode或HashedRelation对象HashedRelationBroadcastMode。调用createPartitioning()方法将返回构造的BroadcastPartitioningClusteredDistribution: 传入一组表达式Seq[Expression],起到了哈希函数的效果。调用createPartitioning()方法将返回构造的HashPartitioning,相同 value 的数据元组会被存放在一起HashClusteredDistribution: 传入一组表达式Seq[Expression],起到了哈希函数的效果。调用createPartitioning()方法将返回构造的HashPartitioning,相同哈希值的数据元组会被存放在一起OrderedDistribution: 传入一组排序表达式Seq[SortOrder],数据元组会根据表达式计算后的结果排序。调用createPartitioning()方法将返回构造的RangePartitioning
Partitioning
定义了一个物理算子输出数据的分区方式。satisfies()方法会检查当前的 Partitioning 操作能否得到所需的数据分布Distribution 。 当不满足时,一般需要进行repartition()操作,对数据进行重新组织。如下图所示的继承关系

Sort
SparkPlan.requiredChildOrdering() 规定了当前 SparkPlan所需的数据排序方式列表。
outputOrdering:Seq[SortOrder]类型,指定每个partition内的顺序requiredChildOrdering:Seq[Seq[SortOrder]]类型,指定每个子结点partition内的顺序
在FileSourceScanExec中,只有获取到bucket信息,才会构建HashPartitioning。只有获取到sortColumns(即数据源中用于排序的列),才会构造SortOrder
override lazy val (outputPartitioning, outputOrdering): (Partitioning, Seq[SortOrder]) = {
if (bucketedScan) {
val spec = relation.bucketSpec.get
val bucketColumns = spec.bucketColumnNames.flatMap(n => toAttribute(n))
val partitioning = HashPartitioning(bucketColumns, spec.numBuckets)
val sortColumns =
spec.sortColumnNames.map(x => toAttribute(x)).takeWhile(x => x.isDefined).map(_.get)
val sortOrder = if (sortColumns.nonEmpty) {
val files = selectedPartitions.flatMap(partition => partition.files)
val bucketToFilesGrouping =
files.map(_.getPath.getName).groupBy(file => BucketingUtils.getBucketId(file))
val singleFilePartitions = bucketToFilesGrouping.forall(p => p._2.length <= 1)
if (singleFilePartitions) {
sortColumns.map(attribute => SortOrder(attribute, Ascending))
} else {
Nil
}
} else {
Nil
}
(partitioning, sortOrder)
} else {
(UnknownPartitioning(0), Nil)
}
}
Strategy
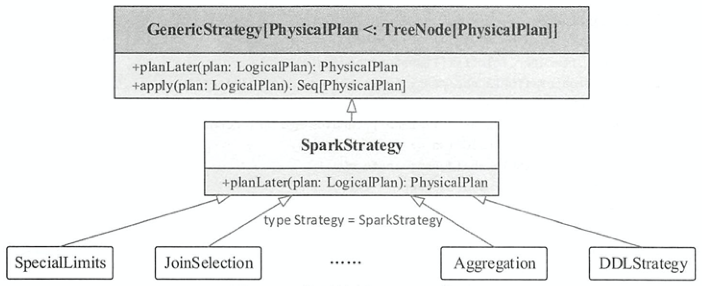
所有的策略都继承自GenericStrategy类,其中定义了planLater()产生PlanLater包装逻辑计划为占位符,定义了apply()方法将传入的LogicalPlan转换为SparkPlan的列表,如果当前的执行策略无法应用于该 LogicalPlan节点,则返回空列表。SparkStrategy继承自GenericStrategy类,实现了planLater()方法,各种具体的Strategy继承自SparkStrategy实现了apply()方法。
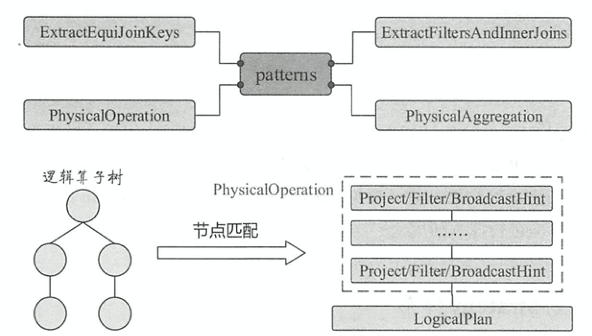
Pattern
如下图所示,展示了Strategy的apply()方法中的多对一的映射模式。如果对应的LogicalPlan时,就会递归查找子节点,若子节点也是对应类型,则收集该子结点,直到碰到其他类型的LogicalPlan节点为止,最后生成映射的物理计划
ExtractEquiJoinKeys: 针对具有相等条件的Join操作的算子集合,提取出其中的Join条件、左子节点和右子节点等信息ExtractFiltersAndinnerJoins: 收集Inner类型Join操作中的过滤条件PhysicalAggregation: 针对聚合操作,提取出聚合算子中的各个部分,并对一些表达式进行初步的转换PhysicalOperation: 匹配逻辑算子树中的Project和Filter等节点,返回投影列、过滤条件集合和子节点
物理计划生成
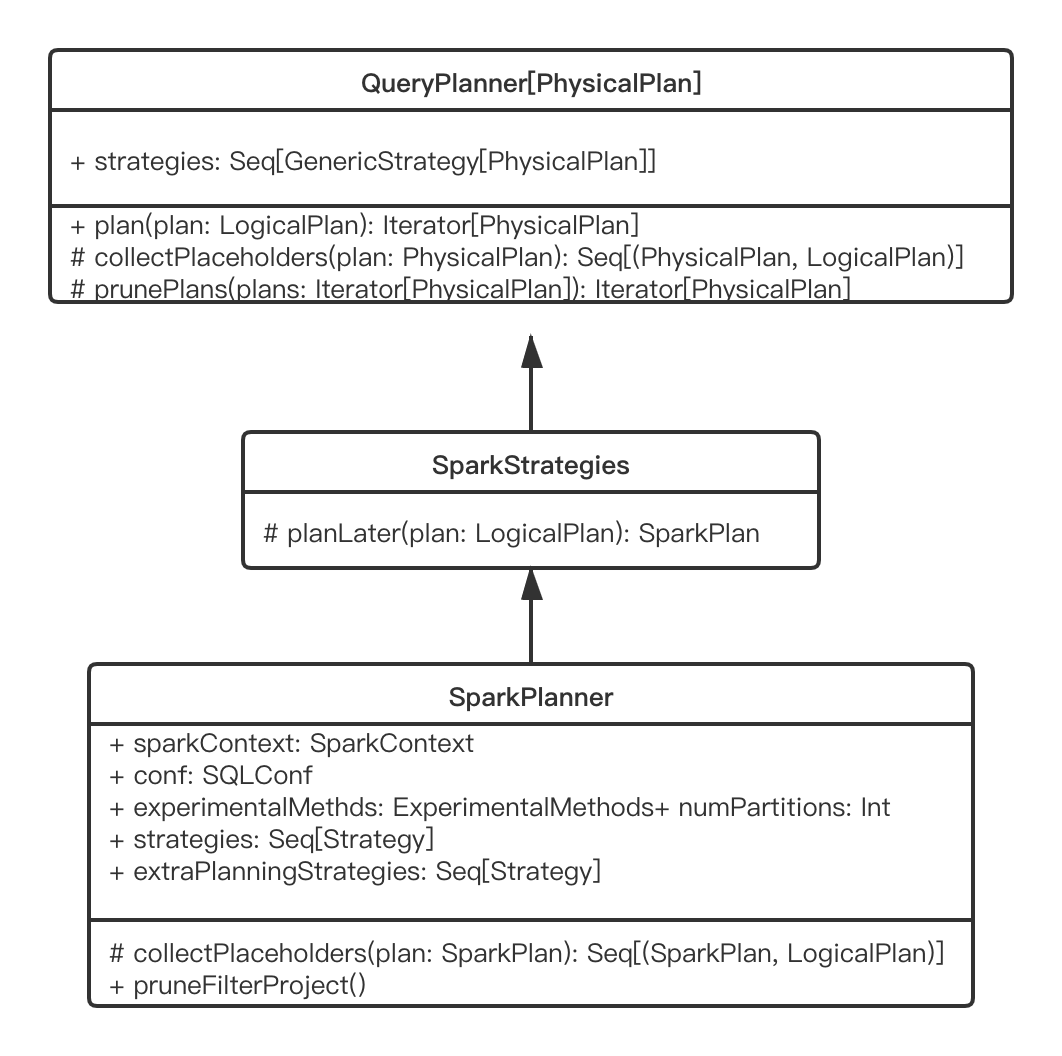
如图所示,SparkPlanner的继承关系。生成物理计划的策略保存在Strategies属性下。plan()方法是生成物理计划的入口,将strategies依次应用到LogicalPlan,生成物理计划候选集合。对于PlanLater类型的 SparkPlan,其doExecute()方法没有实现,表示不支持执行,所起到的作用仅仅是占位作用。SparkPlanner会取出所有的PlanLater算子,递归调用plan()方法进行替换。之后,调用prunePlans()方法对物理计划列表进行过滤,去掉一些不够高效的物理计划 。在生成SparkPlan列表后,调用prepareForExecution()根据需要插入shuffle操作和格式转换以适应Spark执行,主要工作是检查是否有不匹配的partition类型,如果不兼容就增加一个Exchange节点,用来重新分区,这样就最终生成了execute plan
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = {
// Obviously a lot to do here still...
// Collect physical plan candidates.
val candidates = strategies.iterator.flatMap(_(plan))
// The candidates may contain placeholders marked as [[planLater]],
// so try to replace them by their child plans.
val plans = candidates.flatMap { candidate =>
val placeholders = collectPlaceholders(candidate)
if (placeholders.isEmpty) {
// Take the candidate as is because it does not contain placeholders.
Iterator(candidate)
} else {
// Plan the logical plan marked as [[planLater]] and replace the placeholders.
placeholders.iterator.foldLeft(Iterator(candidate)) {
// placeholder: PlanLater(logicalPlan)
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) =>
// Plan the logical plan for the placeholder.
val childPlans = this.plan(logicalPlan)
candidatesWithPlaceholders.flatMap { candidateWithPlaceholders =>
childPlans.map { childPlan =>
// Replace the placeholder by the child plan
candidateWithPlaceholders.transformUp {
case p if p.eq(placeholder) => childPlan
}
}
}
}
}
}
val pruned = prunePlans(plans)
assert(pruned.hasNext, s"No plan for $plan")
pruned
}
按照前一章所述的逻辑优化过程,现在继续对SELECT NAME FROM STUDENT WHERE AGE > 18 ORDER BY ID DESC的物理计划生成过程做分析。如下所示是生成的物理计划
// prepareForExecution前
Project [NAME#11]
+- Sort [ID#10 DESC NULLS LAST], true, 0
+- Project [NAME#11, ID#10]
+- Filter (isnotnull(AGE#12) && (cast(AGE#12 as int) > 18))
+- FileScan csv [ID#10,NAME#11,AGE#12] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/Users/wzx/Documents/tmp/spark_tmp/STUDENT.csv], PartitionFilters: [], PushedFilters: [IsNotNull(AGE)], ReadSchema: struct<ID:string,NAME:string,AGE:string>
// prepareForExecution后
*(2) Project [NAME#11]
+- *(2) Sort [ID#10 DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(ID#10 DESC NULLS LAST, 200)
+- *(1) Project [NAME#11, ID#10]
+- *(1) Filter (isnotnull(AGE#12) && (cast(AGE#12 as int) > 18))
+- *(1) FileScan csv [ID#10,NAME#11,AGE#12] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/Users/wzx/Documents/tmp/spark_tmp/STUDENT.csv], PartitionFilters: [], PushedFilters: [IsNotNull(AGE)], ReadSchema: struct<ID:string,NAME:string,AGE:string>
REFERENCE
- Spark SQL内核剖析
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/11/08/spark-sql-physical-plan/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)