基于Tungsten内存管理方式实现的基本数据类型和数据结构
ByteArray
ByteArray作为final类型,提供了以下对byte数组操作的静态工具方法
writeToMemory(): 调用Platform.copyMemory()方法将字节数组写入特定已分配的内存空间getPrefix(): 从byte数组计算得到一个64位的整型用于排序subStringSQL(): 获得子byte数组concat(): 连接多个byte数组
LongArray
由Tungsten内存管理方式实现的长整型数组,其构造参数只有MemoryBlock。支持数据存储在堆内和堆外,提供了get, set等方法。
UTF8String
由Tungsten内存管理方式实现的字符串类型,负责将UTF-8编码的字符串类型编码为Array[Byte],用于字符串的搜索和字符串比较等场景,提供了各种常用的字符串处理功能,包括基本的startsWith、endsWith、toUpperCase等方法。
BytesToBytesMap
由Tungsten内存管理方式实现的字节数组哈希表,只能添加和更新元素。相比HashMap,能够有效降低 JVM对象存储占用的空间和GC开销。被UnsafeHashedRelation使用,用于基于哈希的join。被UnsafeFixedWidthAggregationMap使用,用于基于哈希的聚合
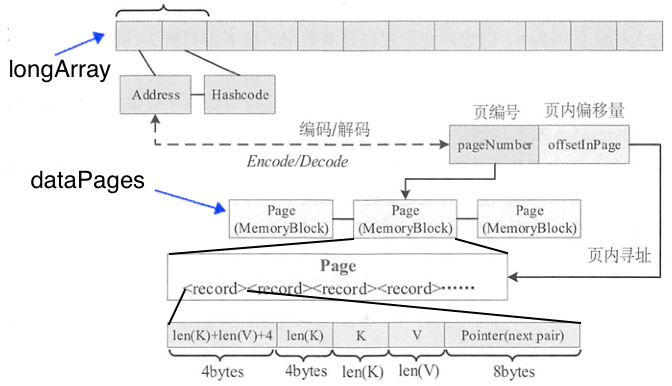
如图所示,成员属性longArray: LongArray负责保存key信息,每个key会占用两个long空间分别存放页号和页内偏移量的编码值fullKeyAddress(可以由TaskMemoryManager解码得到)和key的哈希值,哈希码由key的keyBase, keyOffset, keyLength生成。成员属性dataPages: LinkedList<MemoryBlock>维护着申请到的页表。 每条记录包含占用空间信息,key和value值,最后一部分的指针指向下一个数据,以以应对哈希冲突的情况。
如下代码所示,基本对应着上图所示的查找过程,其中hash由Murmur3_x86_32.hashUnsafeWords(keyBase, keyOffset, keyLength, 42)生成,loc: Location包装查找到的值并返回。使用步长为1的线性探查去处理哈希冲突。
public void safeLookup(Object keyBase, long keyOffset, int keyLength, Location loc, int hash) {
assert(longArray != null);
if (enablePerfMetrics) {
numKeyLookups++;
}
int pos = hash & mask;
int step = 1;
while (true) {
if (enablePerfMetrics) {
numProbes++;
}
if (longArray.get(pos * 2) == 0) {
// This is a new key.
loc.with(pos, hash, false);
return;
} else {
long stored = longArray.get(pos * 2 + 1);
if ((int) (stored) == hash) {
// Full hash code matches. Let's compare the keys for equality.
loc.with(pos, hash, true);
if (loc.getKeyLength() == keyLength) {
final boolean areEqual = ByteArrayMethods.arrayEquals(
keyBase,
keyOffset,
loc.getKeyBase(),
loc.getKeyOffset(),
keyLength
);
if (areEqual) {
return;
}
}
}
}
pos = (pos + step) & mask;
step++;
}
}
数据插入和扩容的逻辑基本与AppendOnlyMap相同,只不过底层使用基于Tungsten内存管理方式实现,这里不再分析。
UnsafeFixedWidthAggregationMap
用于在聚合值宽度固定的情况下执行聚合。主要用法如下,调用getAggregationBufferFromUnsafeRow()根据key得到对应的聚合缓冲区,内部依赖了map: BytesToBytesMap
public UnsafeRow getAggregationBufferFromUnsafeRow(UnsafeRow key, int hash) {
// Probe our map using the serialized key
final BytesToBytesMap.Location loc = map.lookup(
key.getBaseObject(),
key.getBaseOffset(),
key.getSizeInBytes(),
hash);
if (!loc.isDefined()) {
// This is the first time that we've seen this grouping key, so we'll insert a copy of the
// empty aggregation buffer into the map:
boolean putSucceeded = loc.append(
key.getBaseObject(),
key.getBaseOffset(),
key.getSizeInBytes(),
emptyAggregationBuffer,
Platform.BYTE_ARRAY_OFFSET,
emptyAggregationBuffer.length
);
if (!putSucceeded) {
return null;
}
}
// Reset the pointer to point to the value that we just stored or looked up:
currentAggregationBuffer.pointTo(
loc.getValueBase(),
loc.getValueOffset(),
loc.getValueLength()
);
return currentAggregationBuffer;
}
UnsafeExternalSorter
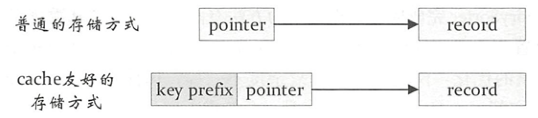
实现了缓存敏感计算。如图所示,常规的做法是每个键值对record中有一个指针指向该record,对两个record 比较时先根据指针定位到实际数据,然后对实际数据进行比较,由于这个操作涉及的是内存的随机访问,缓存本地化(空间局部性)会变得很低。针对该缺陷,缓存友好的存储方式会将key和record指针放在一起,以key为前 缀,避免内存的随机访问。
对于UnsafeExternalSorter来说排序功能主要依赖于UnsafeInMemorySorter,类似于ShuffieExternalSorter和ShuffleInMemorySorter的关系,区别为数据的插入分为两部分, 一部分是调用Platform方法进行真实数据的插入,另一部分是其索引,真实数据插入的地址和其prefix值的插入,当记录只用prefix来比较大小时,真实数据的排序就转换为索引的排序。被UnsafeExternalRowSorter使用,实现了InternalRow的排序,用于SortExec物理计划的排序。被UnsafeKVExternalSorter使用,实现了键值对数据的排序功能,用于HashAggregateExec物理计划中保存溢出聚合缓冲区。
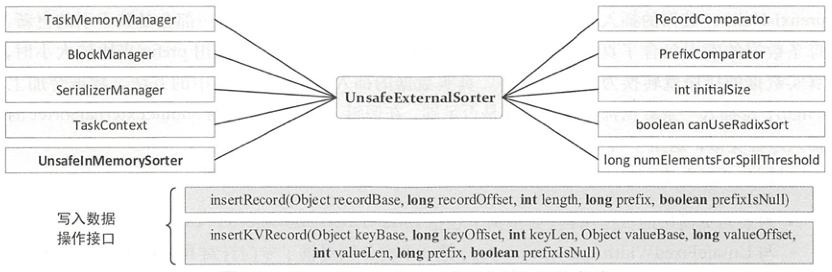
UnsafeExternalSorter中使用TaskMemoryManager和其他属性跟踪当前的内存使用和分配情况,使用链表allocatedPages保存申请到的MemoryBlock,以及使用链表维护数据溢出对象UnsafeSorterSpillWriter。
如下图所示展示了UnsafeExternalSorter的构造参数和写入数据的接口。其中UnsafeInMemorySorter存储数据指针和数据前缀,对两条记录进行排序时,首先判断两条记录指针的prefix是否相等,否则根据数据指针得到的实际数据再进行进一步的比较。 相对于实际数据,pointer和prefix占用的空间都比较小,在比较时遍历较小的数据结构更有利于提高cache命中率(时间局部性)。抽象类RecordComparator用来比较两条记录的大小。抽象类PrefixComparator提供了前缀比较功能,其抽象子类RadixSortSupport定义了基数排序的接口。
REFERENCE
- Spark SQL内核剖析
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/11/20/spark-tungsten-application/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)