对比DataFrame, DataSet和RDD
RDD
- 存储的是Java对象,类型转化安全
- 存储的是Java对象,在传输过程中需要进行序列化和反序列化,默认的序列化速度慢
- 存储的是Java对象,可能会有频繁的GC
- 对于结构化和非结构化的数据都可以处理
适用场景
- 对数据集进行底层的转换,执行和控制
- 数据是非结构化的,比如流媒体和流文本
- 使用函数式编程操作数据而不是SQL
- 在按名称或列处理或访问数据属性时,不考虑schema信息
- 放弃DataFrame和Dataset中针对格式化和半格式化数据集进行的优化
DataFrame
和RDD一样,DataFrame是一个不可变的分布式数据集。如下图所示,数据都被组织到有名字的列中,就像关系型数据库中的表一样
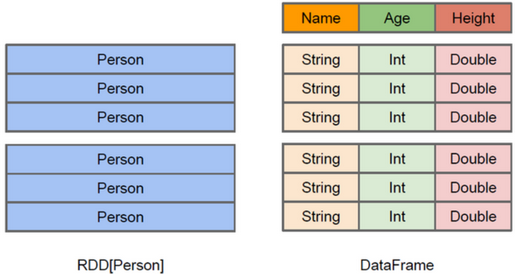
DataFrame比RDD多了schema信息// +----+---+-----------+ // |name|age| phone| // +----+---+-----------+ // |ming| 20|15552211521| // |hong| 19|13287994007| // | zhi| 21|15552211523| // +----+---+-----------+ val schema = StructType(List( StructField("name", StringType, nullable = true), StructField("age", IntegerType, nullable = true), StructField("phone", LongType, nullable = true) )) val dataList = Seq[Row]( Row("ming", 20, 15552211521L), Row("hong", 19, 13287994007L), Row("zhi", 21, 15552211523L)) spark.createDataFrame(dataList.asJava, schema).show()type DataFrame = Dataset[Row],由于Row是一个通用的无类型的JVM对象,所以类型不安全提供了比RDD更丰富的算子,基于Catalyst优化器构建支持执行计划的优化,相对于Dataset来说更快,适合交互分析
数据序列化到堆外内存,不受JVM管理,不会有频繁的GC
数据序列化到堆外内存,无须序列化和反序列化,直接根据schema操作二进制运算,所以也丢失了类型信息
DataSet
Dataset是强类型JVM对象(样例类)集合,通过自定义的样例类来指定schema信息,可通过关系操作进行并行转换
静态类型和运行时类型安全。如下图所示
对于SQL语句来说,只有当运行时才能知道语法错误
// selected语法错误, 编译阶段没有提示 spark.sql("selected name from student")对于DataFrame来说,编译阶段可以发现语法错误,但是不能检查参数类型匹配
val studentDF = spark.read.format("csv") .option("header", "true") .load("/Users/wzx/Documents/tmp/spark_tmp/STUDENT.csv") // selected方法编译报错 studentDF.selected("NAME") // 不存在的字段NAMED没有检查出来 studentDF.select("NAMED")对于Dataset来说,任何不匹配的参数类型都会在编译阶段发现,所以是类型安全
import spark.implicits._ case class People(ID: Int, NAME: String, AGE: Int) val studentDS = spark.read.format("csv") .option("header", "true") .load("/Users/wzx/Documents/tmp/spark_tmp/STUDENT.csv") .as[People] // selected方法编译报错 studentDS.selected("NAME") // 不存在的NAMED字段编译报错 studentDS.map(student=>student.NAMED)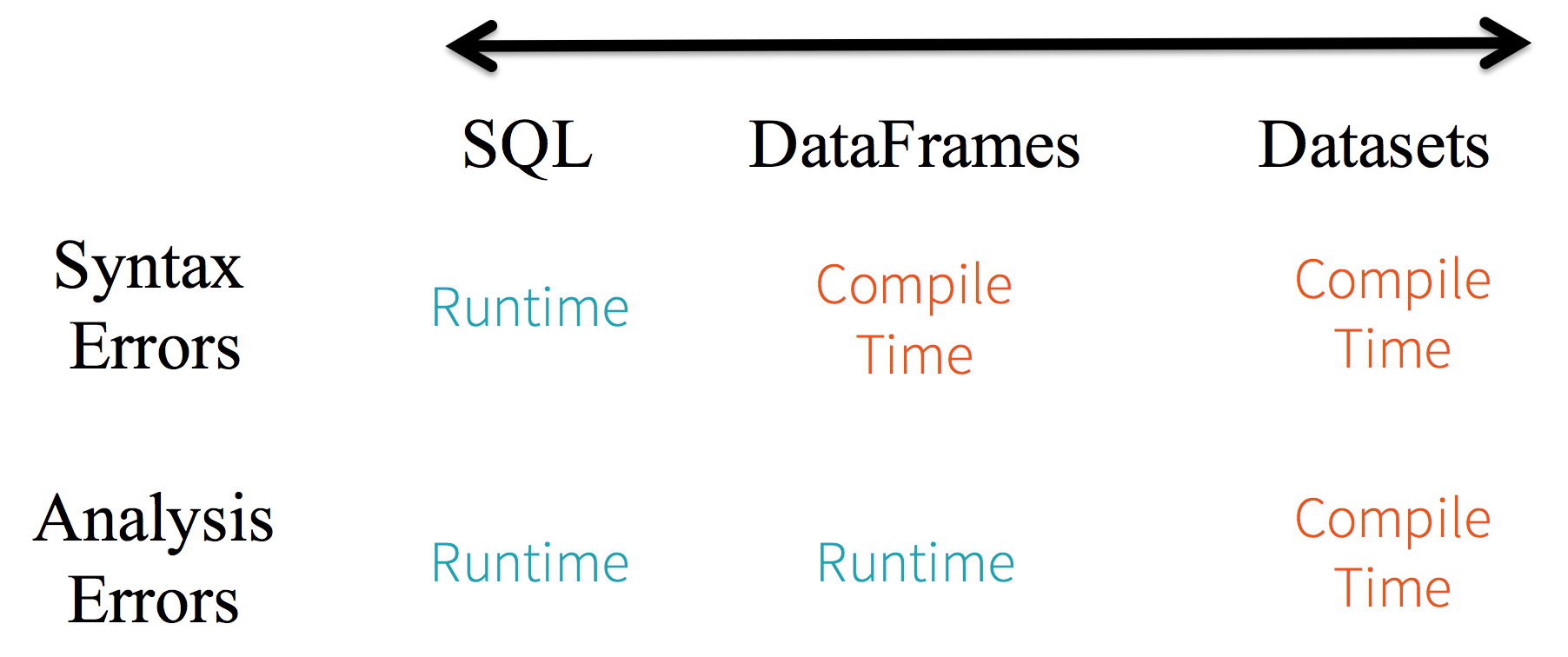
提供了比RDD更丰富的算子,基于Catalyst优化器构建支持执行计划的优化
使用
Encoder[T]来序列化和反序列化,由于知道具体的类型,所以可以使用成员位置信息,降低反序列化的范围,只反序列化需要的列
转化
// dataFrame, dataset to rdd
ds.rdd
df.rdd
// rdd to dataframe
import spark.implicits._
rdd.toDF(col_names)
// rdd to dataset
import spark.implicits._
rdd.toDS(case_class)
// dataframe to dataset
import spark.implicits._
df.as[case_class]
// dataset to dataframe
ds.toDF(col_names)
REFERENCE
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/11/25/spark-sql-dataset/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)