优秀可靠的数仓体系,需要清晰的数据分层结构。即要保证数据层的稳定又要屏蔽对下游的影响,并且要避免链路过长。这里分析常见的数仓分层体系
优势
- 清晰数据结构: 每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
- 减少重复开发: 规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
- 统一数据口径: 通过数据分层,提供统一的数据出口,统一对外输出的数据口径
- 数据血缘追踪: 能够快速准确地定位到问题,并清楚它的危害范围
- 复杂问题简单化: 将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
ODS数据接入层
Operational Data Store
存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,数据粒度最细。一般经过ETL,将数据进行去噪,去重,提脏,业务提取,单位统一,砍字段。数据源一般如binlog日志,安全日志,流量相关的埋点日志等。
DWD数据明细层
Data Warehouse Detail
一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。基于每个具体的业务过程特点,构建最细粒度的明细层事实表,维度退化(关联维度表),将维度退化至事实表中,减少事实表和维表的关联。
DWM数据中间层
Data WareHouse Middle
轻量汇总层,该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标
DWS数据服务层
Data WareHouse Servce
重度汇总层,又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
ADS应用层
Application Data Service
主要是提供给数据产品和数据分析使用的数据,复用性较差,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里
DIM公共维度层
Dimension
建立整个业务过程的一致性维度,降低数据计算口径和算法不统一风险
- 高基数维度数据: 一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
- 低基数维度数据: 一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
业务示例

技术示例
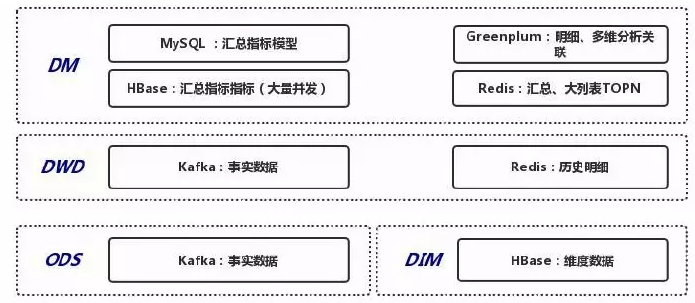
下图是基于Flink的严选实时数仓的技术实现
REFERENCE
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/12/04/dw-layer/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)