分布式系统构件之间通过传递消息可以解除相互之间的功能耦合,这样可以减轻子系统之间的依赖,使得各个子系统或者构件可以独立演进、维护或者重用。消息队列是在消息传输过程中保存消息的容器或中间件、其主要目的是提供消息路由并保障消息可靠传递。
Kafka是Linkedin开源的采用Pub-Sub机制的分布式消息系统,其具有极高的消息吞吐量,较强的可扩展性和高可用性,消息传递低延迟,能够对消息队列进行持久化保存,且支持消息传递的at least once语义。一边用来做通用的消息系统、即时Log收集、用户行为实时收集以及机器状态监控等。Kafka通过顺序IO,mmap和零拷贝提升了消息队列的速度。
整体架构
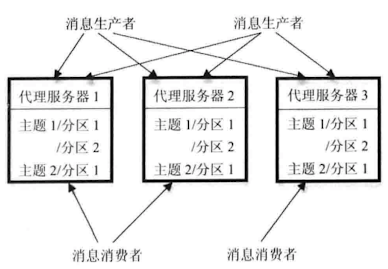
整体架构如图所示
- 消息生产者(Producer): 产生指Topic的消息并将其传 入代理服务器集群
- 代理服务器(Broker): 在磁盘存储维护各种不同Topic的消息队列
- 消息消费者(Consumer): 从代理服务器集群中拉取(Pull)出新产生的消息并对其进行处理
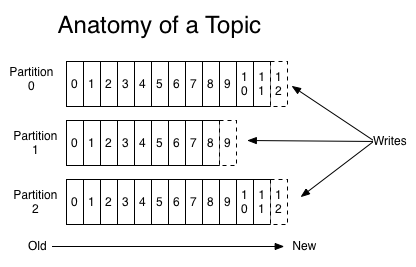
Topic与分区
Topic是发布的消息的类别。Kafka内部对Topic进行数据分区,每个数据分区是有序的、不可更改的尾部追加消息队列,队列内的每个消息被分配本数据分区内唯一Offset。生产者在产生消息时通过以下方式指定消息分区
- 指定随机的分区,如采用Round Robin随机分配
- 根据一定的应用语义逻辑分配,比如可以按照用户Uid进行哈希分配,这样保证同一用户的数据会放入相同队列中,便于后续处理
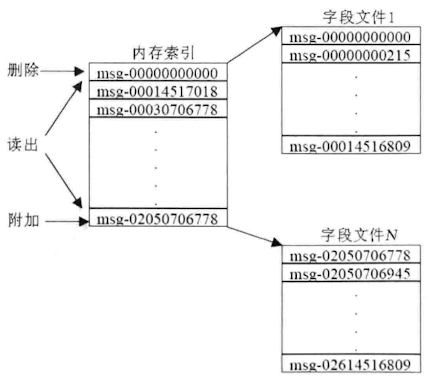
在物理上,Topic的每个分区在物理上对应一个文件夹,以topicName_partitionIndex命名,该文件夹下存储这个分区的所有消息数据文件(.log)和索引文件(.index)
- 消息数据: 一系列被切割成固定大小的文件来存储在磁盘上,每当消息生产者产生新消息时,则将其追加到最后一个文件的尾部。这种文件结构导致了生产者的顺序写入与消费者顺序读出,提交了IO效率
- 索引文件: 在内存维护每个文件首个消息Offset组成的有序数组作为索引,其内容指向对应的外部文件
当消费者读取某个消息时,会指定消息对应的Offset及读取内容大小信息,根据索引进行二分査找即可找到对应文件,然后进行换算即可知道要读取内容在文件中的起始位置, Kafka将内容读出后返回给消费者。
ISR副本管理机制
Kafka中副本管理单位是Topic的数据分区。其中一个作为主副本Leader,其他作为次级副本Slave。由于有副本的存在,所以生产者保证消息传送的at least once。相对于Paxos协议这种多数投票机制来保证主备一致性,如果支持f个副本容错,那么至少需要保持2f+1个副本。Kafka的ISR机制,则至少需要f+1个副本,同步数据量减小,读写效率增加。
ISR的运行机制如下:将所有次级副本数据分到两个集合,ISR集合,这个集合各份数据的特点是即时和主副本数据保持一致,而另外一个集合的备份数据允许其消息队列落后于主副本的数据。在做主备切换时,只允许从ISR集合中选择候选主副本。在数据分片进行消息写入时,只有ISR集合内所有备份都写成功才能认为这次写入操作成功。在具体实现时,Kaka利用 Zookeeper来保存每个ISR集合的信息,当SR集合内成员变化时,相关构件也便于通知。
ZooKeeper
Kaka将这个消费者的当前Offset和Topic信息交由自己保存,这样Broker成为完全无状态的,无须记载任何状态信息。并且消息可能会重复但是不会丢失,消费者保证了消息拉取的at least once。Kaka使用 Zookeeper保存的管理信息和实现的功能包括
- 侦测代理服务器和消息消费者的动态加入和删除。
- 当动态加入或者删除代理服务器以及消息消费者后对消息系统进行负载均衡。
- 维护消费者和消息 Topic以及数据分片的相互关系,并保存消费者当前读取消息的 Offset
- ISR数据副本管理信息
消费者与消费者组
- 消费者组:消费者用一个消费者组名标记自己
- 一个发布在Topic上消息被分发给此消费者组中的一个消费者
- 假如所有的消费者都在一个组中,那么这就变成了queue模型
- 假如所有的消费者都在不同的组中,那么就完全变成了Pub-Sub模型
REFERENCE
- 大数据日知录
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/12/13/bigData-kafka/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)