Hudi 是具有事务、记录级别的更新与删除操作和变更流的数据湖
数据库、数据仓库、数据湖
| 数据库 | 数据仓库 | 数据湖 | 湖仓一体 | |
|---|---|---|---|---|
| 基本概念 | 按照数据结构来组织、存储和管理数据的仓库 | 面向数据分析的集成化数据环境 | 存储在廉价分布式存储或者对象存储上的原始格式文件,以一种统一的语义对外暴露 | 构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理和管理功能 |
| 应用场景 | 服务于事务处理OLTP(Online Transaction Processing) | 服务于OLAP(Online Analytical Processing),支持复杂且高效的结构化数据分析操作 | 在深度学习、实时分析及其他方面分析原始数据 | 计算引擎之下、数据存储之上,处于中间层的数据湖 |
| 常见系统 | Mysql、Oracle | Hive | Hudi、Iceberg、Delta Lake | Hudi、Iceberg、Delta Lake |
| 优势 | 1. 高效的事务性操作 | 1. 大容量的历史数据存储 2. 支持多源数据导入,通过数仓分层,提高数据利用效率 | 1. 可以存储结构化、半结构化、非结构化数据,较大的灵活性 | 1. 事务性保证 2. 高效的记录级别更新 3. 批流一体 |
| 劣势 | 1. 大数量级的分析效率较低 | 1. 传统数仓 Lambda 架构,需要维护批式和流式两条链路 2. 记录级别的数据更新代价较大 |
背景
- 事件时间落后与处理时间,导致窗口运算时需要处理迟到数据。如果严格遵循事件时间语义,迟到的数据会触发对时间窗口的重新计算
- 长尾的业务仍然对于冷数据的更新有着很强的需求,如订单支付可能在很长时间后完成,导致订单状态的改变。
由于Hive的不可变性,触发整个分区的重新计算。从延迟和资源利用率的角度来看,在 Hadoop 上的这些操作都会产生昂贵的开销。根据数仓结构,这一开销通常也会级联地传导到整个 Hadoop 的数据处理 Pipeline 中,最终导致延迟增加了数小时。
所以 hudi 有以下应用场景:
- 近实时写入
- 减少碎片化工具的使用
- CDC 增量导入 RDBMS 数据
- 限制小文件的大小和数量
- 近实时分析
- 相对于秒级存储 (Druid, OpenTSDB) ,节省资源
- 提供分钟级别时效性,支撑更高效的查询
- Hudi 作为 lib,非常轻量
- 增量 pipeline
- 区分 arrivetime 和 event time 处理延迟数据
- 更短的调度 interval 减少端到端延迟 (小时 -> 分钟) => Incremental Processing
- 增量导出
- 替代部分 Kafka 的场景,数据导出到在线服务存储 e.g. ES
时间线
Hudi维护在数据表上所有操作的时间线,用来提供表的实时视图和增量更新。每个操作成为Instant,Hudi保证其原子性和时间一致性(Instant time),包含以下三个部分
Instant action: 对数据集的操作类型Instant time:Instant action的时间戳state:Instant状态REQUESTED: 已被调度却未启动的 actionINFLIGHT: 正在执行的 actionCOMPLETED: 已执行完的 action
以下是重要的 action
COMMIT: 向数据表中原子写一组数据CLEAN: 后台清理不需要的旧版本文件(file slice)DELTA_COMMIT: 向MergeOnRead表中原子写一组数据,数据可能只写入到delta file中COMPACTION: 后台压缩如合并base file和delta file生成新的file slice,是一种特殊的COMMITSROLLBACK: 回滚不成功的COMMITS和DELTA_COMMITSAVEPOINT: 将某些文件组标记为saved,CLEAN不会删除它们,用于容错
存储
如下图所示,每个partition作为一个目录。在partition内包含多个file group,file group包含一组记录的所有版本,用唯一的file id标识。file group内包含多个file slice,表示同一组记录的不同版本。file slice内包含一个Parquet格式的base file由COMMIT或者COMPACTION生成,和一组avro格式的delta file,记录base file生成后的insert/upsert操作的log。
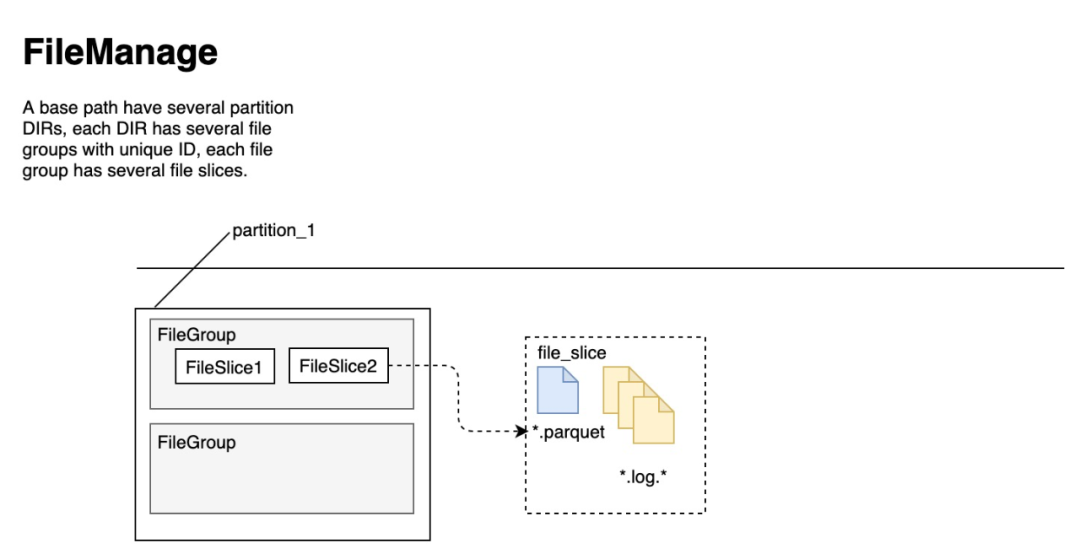
索引
Hoodie key (record key + partition path) 和 file id (FileGroup) 之间的映射关系,数据第一次写入文件后保持不变。Index 用于区分消息是 INSERT 还是 UPDATE。
- 新增 records 找到映射关系:record key => target partition
- 当前最新的数据 找到映射关系:partition => (fileID, minRecordKey, maxRecordKey) LIST (如果是 base files 可加速)
- 新增 records 找到需要搜索的映射关系:fileID => HoodieKey(record key + partition path) LIST,key 是候选的 fileID
- 通过 HoodieKeyLookupHandle 查找目标文件(通过 BloomFilter 加速)
数据表类型
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | 高(写放大) | 低 |
| 查询延迟 | 低 | 高(读放大) |
| 更新代价(I/O) | 高 (重写Parquet文件) | 低 (追加到增量日志) |
| Parquet文件大小 | 小 | 大 |
| 写开销 | 高 | 低 (依赖于压缩策略) |
Copy On Write
- 支持 Snapshot Queries 和 Incremental Queries
- update时执行同步合并,file slice中只有每个commit所产生的base file,没有delta file
- insert时会扫描当前partition的所有small file(小于一定大小的 base file),然后 merge写新的file slice;如果没有small file,直接写新的file group + file slice
- 存在写放大(为新写入的少量数据却进行大量数据的合并),没有读放大
如图所示,为CopyOnWrite表的一个Upsert操作和两个新旧sql查询。
- update会在目标file group下生成一个新的file sclice,insert会分配一个新文件组并生成第一个file sclice
- sql查询会检查时间上最新提交并读取每个file group中最新的file slice。旧sql不会读取到最近的
COMMIT
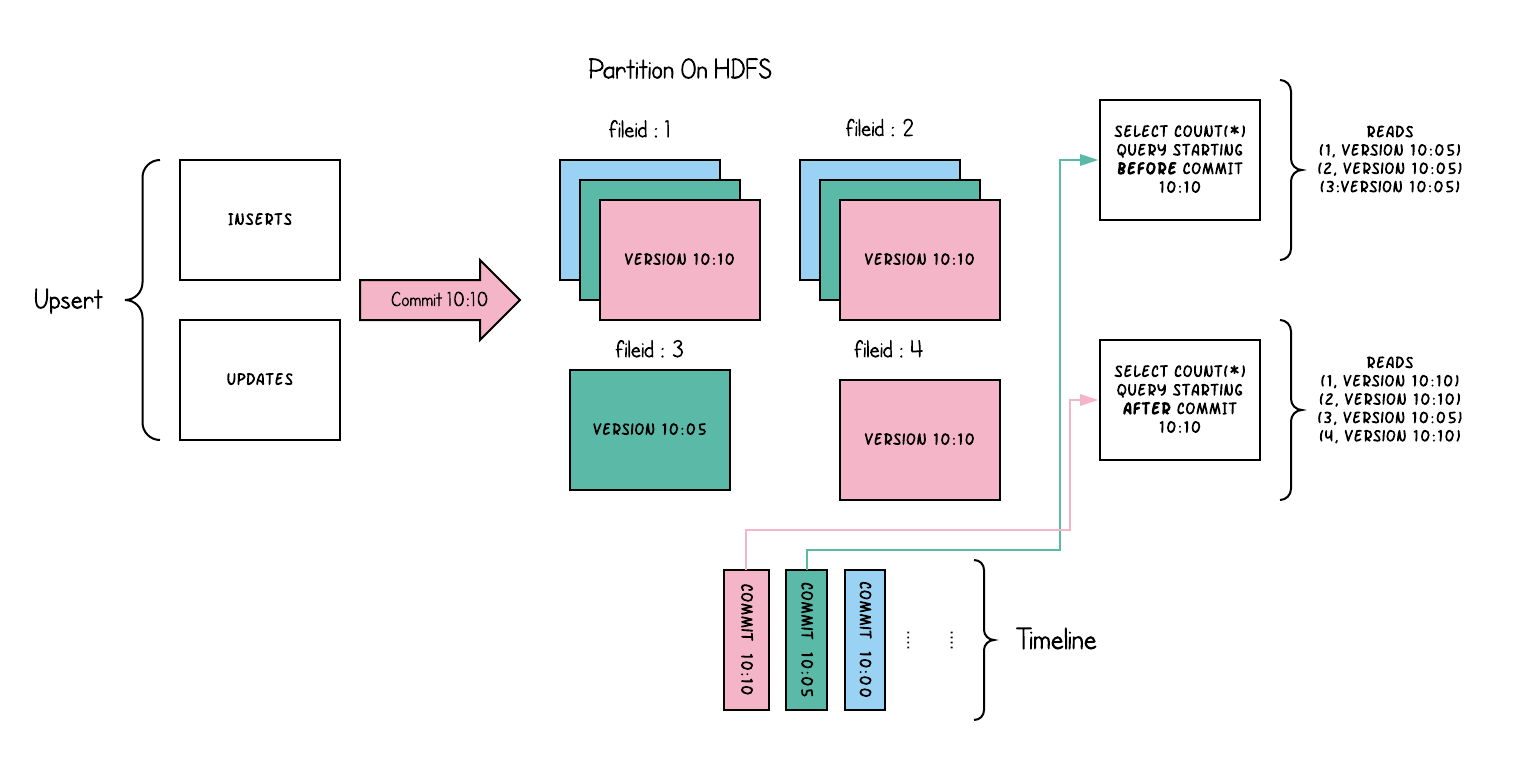
CopyOnWrite表有以下特点
- 优先支持在文件级原子更新数据,而无需重写整个表/分区
- 能够只读取更新的部分,而不是进行低效的扫描或搜索
- 严格控制文件大小来保持出色的查询性能
Merge On Read
- 支持 Snapshot Queries、Incremental Queries 和 Read Optimized Queries
- update时添加更新记录到delta file中,然后同步或异步压缩生成新版本的file slice,根据delta file的大小触发合并,提升查询性能
- insert时与CopyOnWrite一致
- 存在读放大(Snapshot Queries需要将base file和delta file合并),没有写放大
如图所示,为MergeOnRead表的一个Upsert操作和两个在10:10触发的Read Optimized Queries和Snapshot Queries。
- 每次
COMMIT只是写入对应的delta file - 定期的
COMPACTION(10:05触发) - Read Optimized Queries不可见上一次
COMPACTION(10:05)之后的数据 - Snapshot Queries可见实时数据
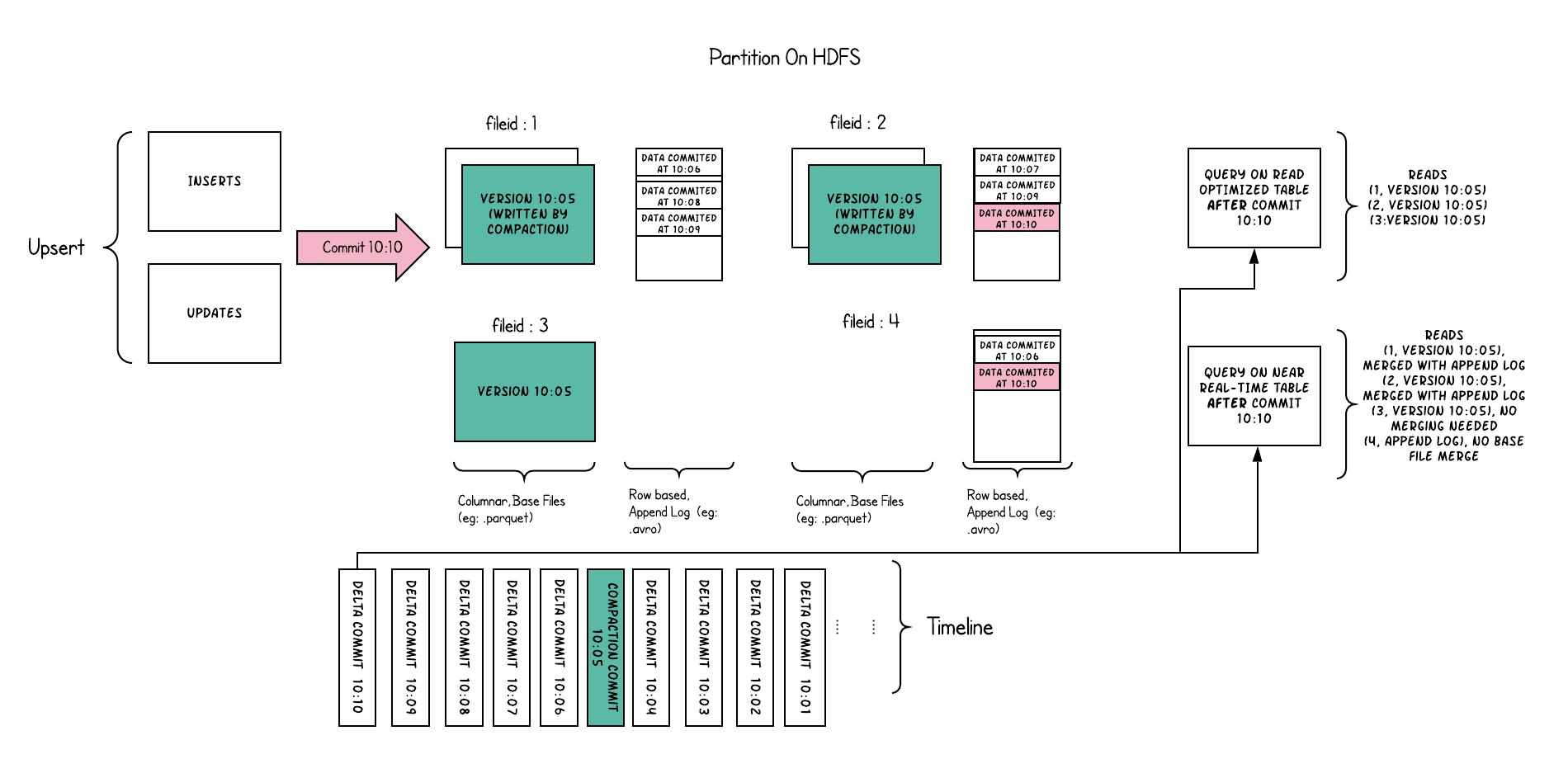
MergeOnRead表有以下特点
- 支持在DFS上启动近实时处理
- 避免写放大
查询类型
| Trade-off | Snapshot | Read Optimized |
|---|---|---|
| 数据延迟 | 低 | 高 |
| 查询延迟 | 高(合并base file和delta file) | 低(只读取base file) |
Snapshot Queries
近实时视图
该查询只查看给定commit或者compaction的最新快照。对于MergeOnRead表来说,会触发最新file slice中的base file和delta file的即时合并(几分钟的延迟)
Incremental Queries
增量视图
该查询只查看给定commit或者compaction的新写入数据。这样提供了增量数据管道。
Read Optimized Queries
读优化试图
该查询只查看给定commit或者compaction的最新快照。只暴露出最新的file slice中的base file,保证了列式存储的查询性能
REFERENCE
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2021/04/19/hudi/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)