Flink 相对于 Spark Streaming 的微批处理架构,是真正意义上的流式处理架构。具备批流一体,高吞吐低延迟,状态机制,可靠的容错机制等优势。
优势
Apache Flink 同时支持流式及批量分析应用,即批流一体,所以Flink在实时数仓和实时ETL中有天然的优势:
- 状态管理,实时数仓里面会进行很多的聚合计算,这些都需要对于状态进行访问和管理,Flink 支持强大的状态管理
- 表义能力,Flink 提供极为丰富的多层次 API,包括Stream API、Table API 及 Flink SQL
- 生态完善,实时数仓的用途广泛,Flink 支持多种存储(HDFS、ES 等)
- 批流一体,Flink 已经在将流计算和批计算的 API 进行统一
- 丰富的窗口支持,Flink 支持包含滚动窗口、滑动窗口及其他窗口
- 多种时间语义,Flink 支持 Event Time、Processing Time 和 Ingestion Time
相对于Spark Streaming,有以下优势
- 架构
- Spark Streaming 的架构是基于Spark的,本质是微批处理,可以把 Spark Streaming 理解为时间维度上的 Spark DAG
- Flink 会构建一张分布式的 DAG 图,每个子任务都流式处理
- 一致性
- Spark Streaming 通过配置 checkpoint 的方式实现 At least once 语义。当任务出现 failover 的时候,会从 checkpoint 重新加载,使得数据不丢失,但是会导致数据重复处理。
- Flink 基于 2PC 实现了 Exactly once 语义
事件驱动
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。在传统架构中,我们需要读写远程事务型数据库,比如MySQL。在事件驱动应用中数据和计算不会分离,状态保存在本地,所以具有更高的吞吐和更低的延迟。 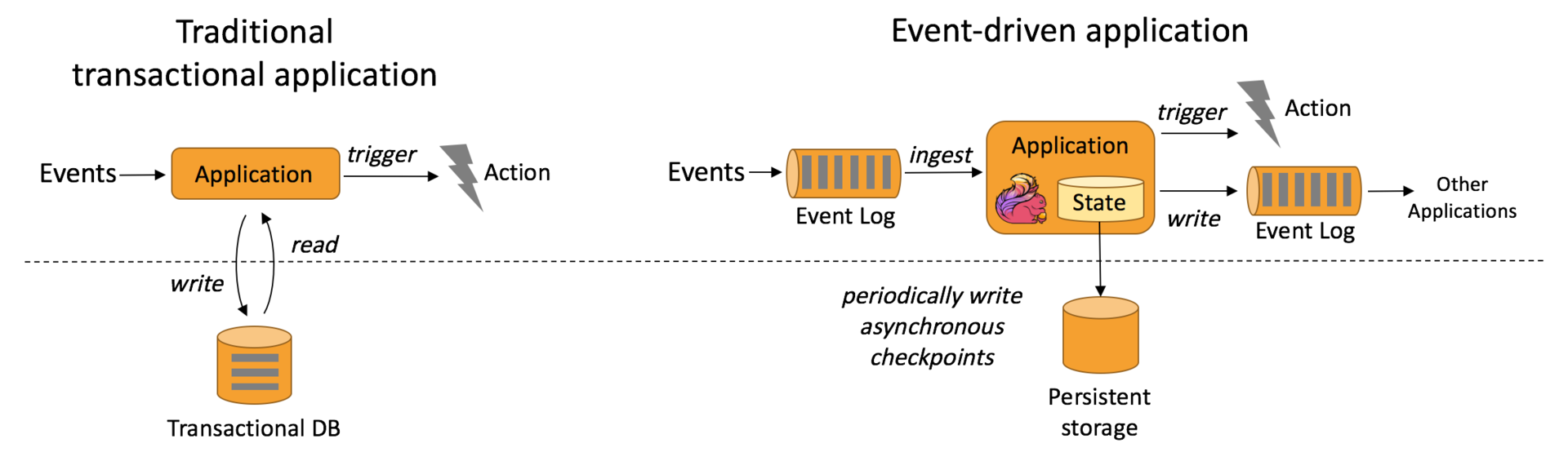
架构
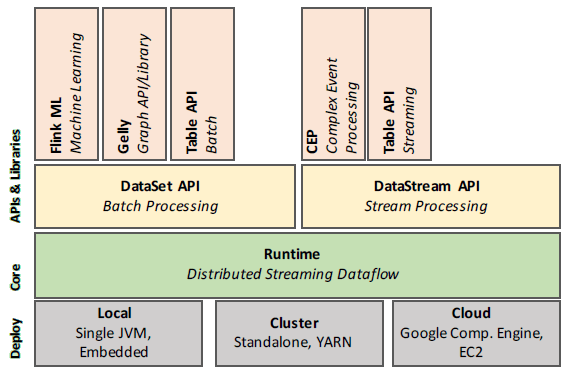
部署模式
调试模式
- Local
- 模拟 cluster 集群,仅启动 JobManager 完成应用的运行
- Standalone
- 部署相对简单,可以支持小规模,少量的任务运行
- 缺少系统层面对集群中 Job 的管理,容易遭成资源分配不均匀
- 资源隔离相对简单,任务之间资源竞争严重
生产模式
- Yarn-session
- 所有任务提交到同一个 Flink runtime 集群
- Client 需要执行 main 方法并生成 JobGraph 传输到 JM
- 不同作业间共享资源,并且其中一个任务的失败会影响该 session 上的其他作业
- 适用于启动延迟非常重要的短作业,例如交互式查询
- Yarn-per-job
- 每个任务提交到独占的 Flink runtime 集群
- Client 需要执行 main 方法并生成 JobGraph 传输到 JM
- 任务之间不会有影响,也不共享资源
- 适用于长稳运行的普通流式作业
- Yarn-application
- 每个任务提交到独占的 Flink runtime 集群
- JM 执行 main 方法并生成 JobGraph
- Client 不需要执行重操作,其资源不会成为瓶颈
Client 提交作业分为 Detached 模式和 Attached 模式。Detached 模式下,Client 提交完作业后可以退出。 Attached 模式下,Client 提交完作业后,需要与集群之间维持连接
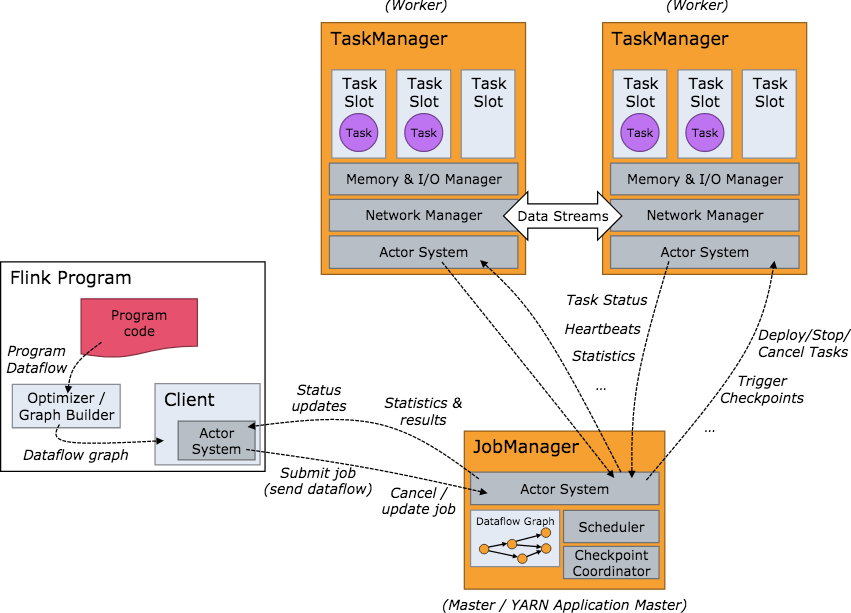
Runtime
Runtime 层以 JobGraph 的形式接收程序并执行
- Client
- Client 将 Flink 程序转化为数据流图,提交给 JobManager 去执行
- JobManager
- 集群管理者,协调 JobGraph 的分布式执行
- 负责调度任务、协调 checkpoints、协调故障恢复、收集 Job 的状态信息,并管理 Flink 集群中的从节点 TaskManager
- TaskManager
- 实际负责执行计算的 Worker,在其上执行 Flink Job 的一组Task。维护缓冲池,并负责网络连接以在算子之间交换数据流
- 所在节点的管理员,负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向 JobManager 汇报
API&LIB层
DataSet 用于处理有限数据集即批处理,而 DataStream 用于处理无界数据流即流处理。DataStream API 和 DataSet API 均通过单独的编译过程生成有状态算子连接的数据流 DAG,交由 Runtime 去执行。
Flink自带了一些用于特定领域的库,这些库会生成 DataSet API 和 DataStream API 程序。
- FlinkML 用于机器学习
- Gelly 用于图计算
- Table API 用于 SQL 操作
REFERENCE
- CARBONE P, KATSIFODIMOS A, EWEN S, 等. Apache flink: Stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, IEEE Computer Society, 2015, 36(4).
- flink官方文档
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2024/01/13/1-flink-overview/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)