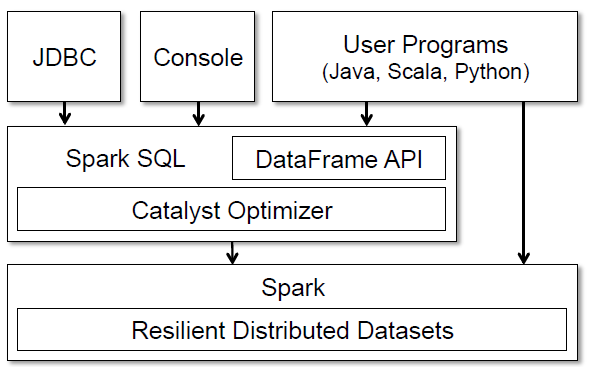
Spark中的重要模块,在Spark的函数式编程API中引入了关系数据的处理
引入
基于在Shark上的经验,开发出了Spark SQL,主要解决了以下两个功能。通过DataFrame API紧密结合了关系型处理和过程型处理。通过 Catalyst,一个可拓展的优化器,定制优化规则,控制代码生成和自定义拓展点。
DataFrame的存在正是为了解决Shark的缺点。Shark不支持在Spark程序中的数据(RDD) 上的关系型处理;在Spark中调用Shark只能通过SQL字符串形式;Hive的优化器是为MapReduce量身定制的,难以拓展。
- 通过
DataFrameAPI,同时支持原生RDD和外部数据源的关系型处理 - 使用现有的DBMS的技术,来提供更高的效率支持
- 支持添加新数据源
- 可以拓展新的分析算法
DataFrame
DataFrame一个分布式的拥有元数据的数据结构,相当于关系型数据库中的表。与RDD非常类似,可以看做由Row对象组成的RDD并可以使用过程型处理如Map,但是DataFrame会保留数据格式(元数据)并支持许多可优化的关系型处理如where。
DataFrame可以由外部表(或外部数据源)或RDD中创建。与RDD类似,DataFrame也是惰性运算的,每个DataFrame只是代表在数据源上的逻辑计划,只有当遇到输出操作如save,才会构建物理计划,计算结果。但是每次变换都会检查逻辑计划是否合法(检查数据类型是否合适,表达式中的列是否存在等)。
从RDD中构建DataFrame时,Spark SQL通过反射获取字段类型(元数据),并会创建logical data scan operator指向RDD,这会被编译成指向原始对象的物理operator,这样dataframe的内部操作实际上就是对原始对象进行操作
case class User(name: String , age: Int)
// Create an RDD of User objects
usersRDD = spark.parallelize(
List(User("Alice", 22), User("Bob", 19)))
// View the RDD as a DataFrame
usersDF = usersRDD.toDF
这段代码说明,在usersDF之上的操作最终都转化为对User的操作
数据模型
DataFrame支持所有主流的SQL数据类型,如boolean,interger,double等以及复杂数据类,如structs,arrays,maps等,还支持自定义拓展点(自定义数据源,UDT)。
数据源
所有数据源都需要实现createRelation函数,此函数接受一组键值对,返回一个代表此关系的BaseRelation。每个BaseRelation包含一个元数据和一个可选的数据源估计大小。
如果想要使用这些数据源,需要在SQL表达式中指定他们的包名,同时可以把键值对传入配置项
CREATE TEMPORARY TABLE messages
USING com.databricks.spark.avro
OPTIONS (path "messages.avro")
UDT
用户自定义类型是Catalyst内置类型的组合。为了注册一个Scala的类型作为UDT,用户需要提供类型与内置类型的正向和反向映射。如下面代码所示,定义了一个二维点的类型。
class PointUDT extends UserDefinedType[Point] {
def dataType = StructType(Seq( // Our native structure
StructField("x", DoubleType),
StructField("y", DoubleType)
))
def serialize(p: Point) = Row(p.x, p.y)
def deserialize(r: Row) =
Point(r.getDouble(0), r.getDouble(1))
}
运算
DataFrame支持关系型处理,并且是惰性运算
ctx = new HiveContext()
users = ctx.table("users")
young = users.where(users("age") < 21)
println(young.count())
在上面的代码中DataFrame users由表users构建,关系型操作users.where(users("age") < 21)构建了新的DataFrame young,但没有生成物理计划。只有调用count()时,才发生了计算。
DataFrame可以被注册成为一个临时表,就可以使用SQL来进行查询,但并不相当于RDD中的persist(),临时表仍然要从头开始计算。
users.where(users("age") < 21)
.registerTempTable("young")
ctx.sql("SELECT count(*), avg(age) FROM young")
持久化时,DataFrame并不是作为JVM对象存储数据,而是应用了列压缩技术如字典编码和行程编码。通过调用cache()持久化。
UDFs
DataFrame支持用户自定义函数(UDFs)。不需要额外的编程环境,不用复杂的打包、注册操作过程。很容易实现关系运算和高级分析函数处理的整合。
val model: LogisticRegressionModel = ...
ctx.udf.register("predict",
(x: Float, y: Float) => model.predict(Vector(x, y)))
ctx.sql("SELECT predict(age, weight) FROM users")
Catalyst优化器
Catalyst是一个用Scala编写的优化器。运用Scala的模式匹配特性,可以容易地添加优化规则。运用Scala的quasiquotes特性生成Java字节码
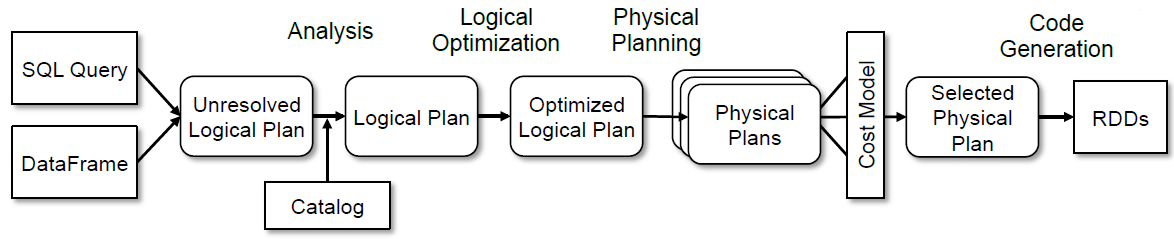
Catalyst的优化处理始于从SQL字符串(由SQL解析器生成AST)或DataFrame构造的unresolved逻辑计划。unresolved指字段类型未知,未和表进行匹配(不存在)。
树
树是Catalyst中处理的主要类型。每个结点包含一种类型,新的类型可以通过通继承TreeNode来实现
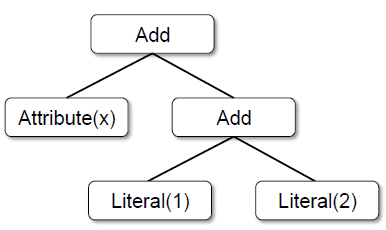
如图所示,这个树代表表达式x+(1+2),Literal(value:Int)表示常量,Attribute(name:String)表示row的一个属性,Add(left:TreeNode,right: TreeNode)表示相加操作符
优化规则
树可以由优化规则变换为另外一个树。通过Scala的模式匹配,寻找子树的特定结构应用优化规则。即使有新运算添加进系统,也不需要改变规则。Catalyst 把规则进行分组,同时针对每个批处理递归执行,直到再次应用规则的时候,树不会再次改变
Analysis阶段
读入calalog(含有所有table和DataFrame的元数据仓库),解析校对所引用的表名或者列名
- 从Catalog中根据名称查找关系
- 列映射,将命名属性(如col)映射到树中操作符结点的子项
- 给那些引用相同值的属性,一个唯一的ID(随后遇到如
col=col时,防止多次解析) - 通过表达式推断类型。例如,我们无法知道
1+col的返回类型,直到解析出col的类型。
经过Analysis阶段,unresolved逻辑计划变为逻辑计划。
Logical Optimization阶段
在逻辑优化阶段,会对逻辑计划应用标准的基于规则的优化,如常量合并,谓词下推等规则。接着会应用自定义规则。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec, scale))
if prec + 10 <= MAX_LONG_DIGITS =>
MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale)
}
}
}
如上代码所示,这个规则描述了固定精度的BigDecimal,在相加之后进行精度拓展。prec,scale的含义,可以看看Java的BigDecimal文档。
Physical Planning阶段
Spark SQL根据一个逻辑计划,使用与Spark执行引擎匹配的物理操作符来生成一个或多个物理计划。接着,使用成本代价模型来选择一个计划。
Code Generation阶段
Quasiquotes(把字符串替换为代码的特性)允许在 Scala 语言中使用编程的方式构建抽象语法树(ASTs),然后可以在运行时提供给 Scala 编译器生成字节码。
def compile(node: Node): AST = node match {
case Literal(value) => q"$value"
case Attribute(name) => q"row.get($name)"
case Add(left, right) =>
q"${compile(left)} + ${compile(right)}"
}
如以上代码所示,类似Add(Literal(1), Attribute("x"))的AST树就会生成1+row.get("x")的Scala表达式
REFERENCE
[1]ARMBRUST M, XIN R S, LIAN C, 等. Spark sql: Relational data processing in spark[C]//Proceedings of the 2015 ACM SIGMOD international conference on management of data. 2015: 1383–1394.
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/02/14/spark-sql/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)