HDFS是一个高容错,大文件存储,高吞吐量的分布式文件系统
设计原则
- 硬件故障是普遍存在的。特别是HDFS集群中存在成百上千的服务器,结点故障时常发生,需要通过高容错策略保证故障检测和快速恢复
- 流式数据访问。HDFS设计用于批处理,而不是用户交互使用,所以需要高吞吐量,而不是低延时
- 大文件。HDFS支持保存大文件,从GB乃至TB。大量小文件会耗尽NameNode的存储空间。
- 简单一致性。为保证一致性,HDFS采用单写多读策略。在文件创建完成后,只能在文件末尾添加或者截断。这样做简化了一致性模型并且保证了高吞吐量
- 移动计算。在存储数据的结点上计算,而不是把数据传输到运行计算的结点上
- 可拓展
架构
在HDFS中,文件的组织形式是目录和文件的层级结构,即namespace。
文件的元数据以inode的形式存储在 NameNode 上,inode中包含权限,修改和访问时间,namespace,硬盘使用率等信息。
文件内容以块的形式存储在 DataNode 上。这种以inode和数据块的组织形式的文件系统非常类似linux的文件系统。HDFS中的块比较大,默认为128MB,目的是为了最小化寻址开销。
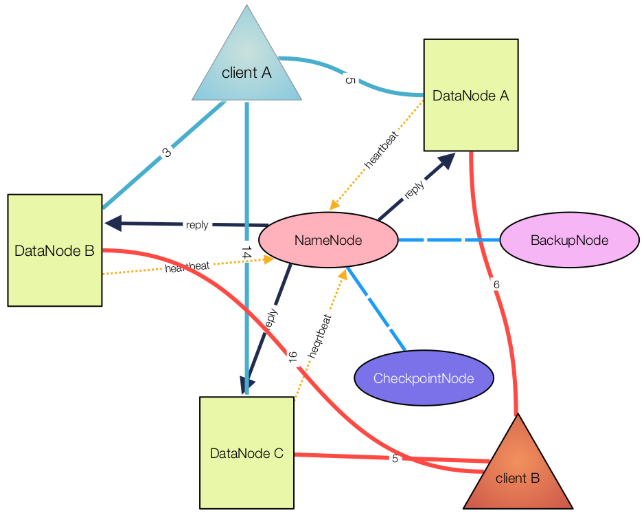
NameNode
元数据结点,相当于GFS中的master结点。结点内保存以下数据:
- namespace:以树的形式保存在内存中
- 块与DataNode地址的映射表:该信息不会在checkpoint中记录,因为块地址可能经常会变化
- image:namespace镜像文件
- checkpoint:对image的持久化记录,存在本地文件系统中
- journal:image的修改日志,存在本地文件系统中
联邦HDFS
由于NameNode的内存限制了系统的横向扩展,所以允许多个NameNode来管理文件系统的namespace。在联邦环境下,每个namenode维护一个namespace volume, 由namespace的元数据和对应的数据块池组成。namespace volume之间是相互独立的。
DataNode
数据存储结点,相当于GFS中的slave结点。结点内保存块数据和块的元数据(检验和,时间戳,块ID)。
注册
- namespace ID:标识了当前集群使用的namespace,只有namespace ID相同的结点才能加入集群,每个结点都永久保存这个ID
- storage ID:每个DataNode结点都保存唯一的storage ID,NameNode将以storage ID区分DataNode,而不是以其地址,并且第一次注册之后就不会改变
一个结点作为DataNode加入现有集群,应遵循以下注册步骤:
- 握手:DataNode向NameNode验证namespace ID和软件版本
- 文件系统格式化时,会分配namespace ID
- 新初始化的没有namespace ID的DataNode加入集群时,NameNode会给其分配namespace ID
- 若验证失败,DataNode进程会自动退出
- 若验证成功,DataNode向NameNode注册其storage ID
块报告
在注册完成之后,DataNode会立即向NameNode发送一次块报告,此后每小时发送一次块报告。
块报告中包含块ID,时间戳和块长度,这样NameNode就可以掌握文件系统中块的更新视图
块扫描
DataNode会周期性检查块副本的数据是否与检验和一致。如果发现副本损坏,会立即通知NameNode。但是NameNode会优先复制未损坏的副本,当副本数达到复制因子再删除损坏的副本。这样做可以尽量保存数据,即使数据损坏,用户也能在获取损坏的数据。
块缓存
对于频繁访问的文件,其对应的块可能被显式地缓存在datanode的内存中,以堆外块缓存(off-heap block cache)的形式存在。作业调度器通过在缓存块的datanode上运行任务,可以利用块缓存的优势提高读操作的性能。
用户或应用通过在缓存池(cache pool) 中增加一个cache directive 来告诉namenode需要缓存哪些文件及存多久。缓存池是一个用于管理缓存权限和资源使用的管理性分组。
退役
管理员可指定不接受的结点地址。当DataNode被标记为不接受的结点时,会进入退役状态(Decommissioning)。DataNode变成只读,存储的块会移动到其他DataNode上。当所有块都移动完毕时,DataNode变成退役完毕状态(Decommissioned),可以安全移除。
client
读文件
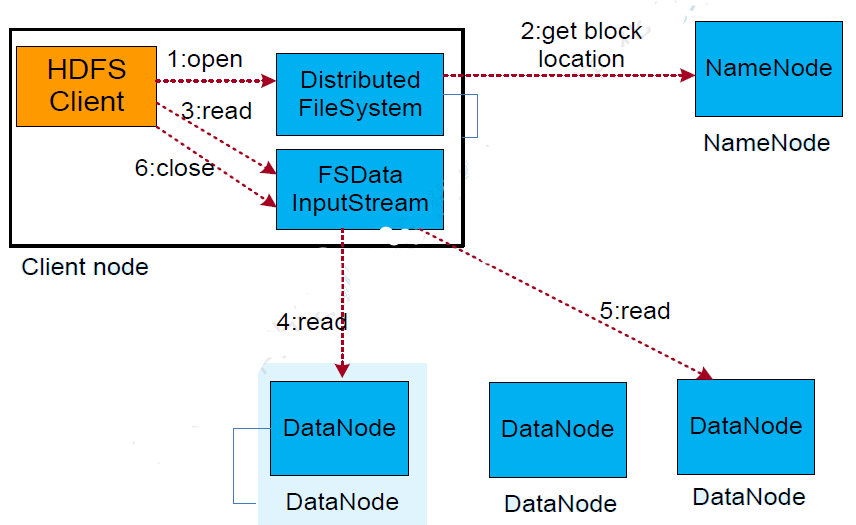
- client向NameNode请求读文件
- NameNode返回文件的数据块列表和对应的DataNode地址
- client依次从距离最近的DataNode处读取块数据
- 如果当前DataNode不可用,则从下一个DataNode处读取块数据
- client会读取块数据和其校验和,如果不一致,则认为该块已损坏,从下一个DataNode处读取块数据
- 如果client读取正在写的文件,会先询问其文件长度
写文件
HDFS通过租约机制实现多读单写模型。
- 每个client在写文件时首先要获得该文件的lease,通过心跳来更新lease
- soft limit:在此时间范围内,client独占该文件;超过时间范围,其他client可以抢占该lease
- hard limit:超过该时间范围,HDFS强制关闭该文件并释放lease
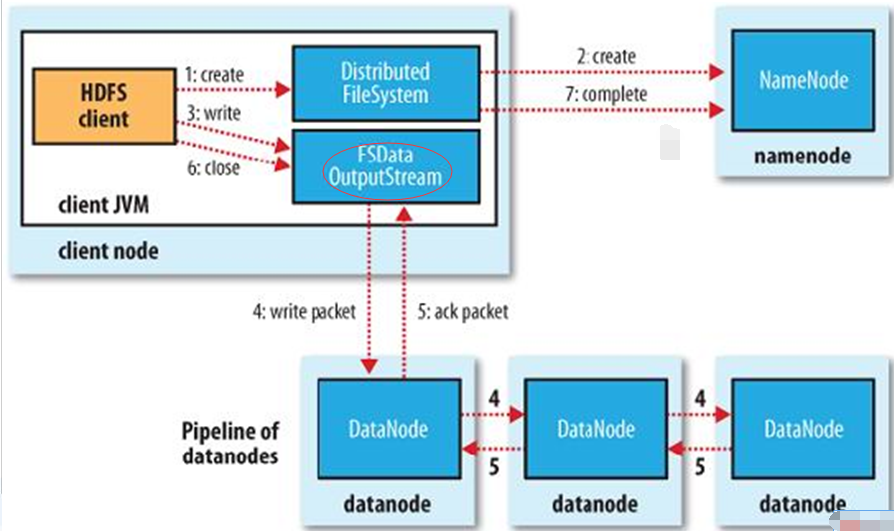
- 向NameNode请求写文件,并请求第一个可写块
- NameNode返回块ID和块副本的DataNode列表(默认三个),构造client和DataNode之间的管道
- 构造一个管道连接client和所有DataNode,使从client到最后一个DataNode的总网络距离最小
- 管道中的数据以包的形式(64KB)传送,下一个包传送之前不一定需要接受到ACK(流水线机制),取决于窗口大小
- client还会发送校验和,管道中最后一个DataNode会将校验和存储
- 询问下一个块地址,并建立新的管道,发送数据
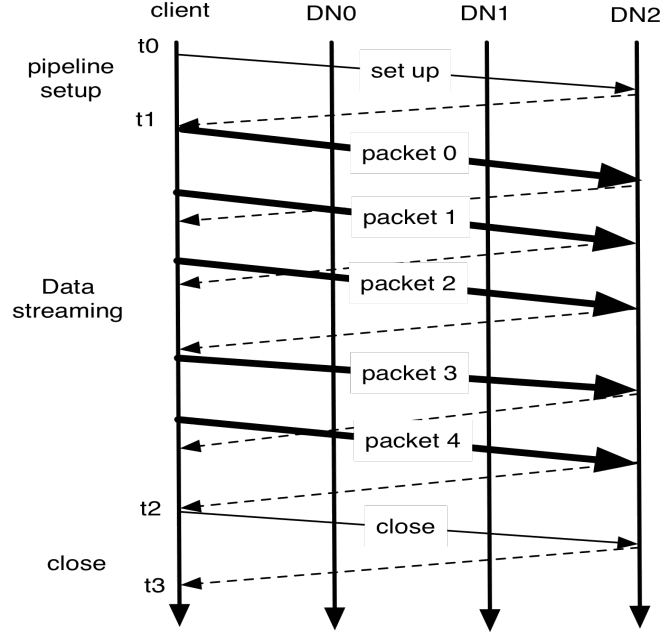
在文件关闭之前,HDFS并不能保证client读取时可以看到已写入的数据。通过hflush指令,让当前数据包立即传输并等待数据传输完(ACK),所以所有hflush之前的操作都可见
CheckpointNode
CheckpointNode可以运行在一个单独的结点上,也可以运行在NameNode上。CheckpointNode中包含了checkpoint和journal,可以看做是NameNode的快照。checkpoint一般不会改变,除非遇到以下两种情况:
在集群启动(重启)时,NameNode会从checkpoint初始化namespace,然后从journal中应用更改,这样就可以恢复到journal中记录的最新状态。在开始为client提供服务之前,会将新的checkpoint和空journal写回到存储目录。
CheckpointNode可以周期性的触发新checkpoint的创建。从NameNode下载当前的checkpoint和journal文件,在本地合并它们,然后将新的checkpoint返回给NameNode。之所以要周期性地触发checkpoint的创建,是因为可以缩短从checkpoint恢复的时间,缩短journal的长度,减小损坏发生的几率。
Secondary NameNode与CheckpointNode功能一致。
BackupNode
BackupNode起到对NameNode备份的作用,是一个真正意义上的备份结点,可以看做只读的NameNode。
BackupNode不仅拥有CheckpointNode的全部功能,并且在内存中保持image,并不断从NameNode处接收journal保存在本地,并应用于内存中的image,由此与NameNode保持实时的同步。
Standby NameNode
为解决NameNode的单点失效的问题,Hadoop2增加了高可用性(HA)模式。在这一模式中,增加了备用的NameNode。当活动NameNode失效,备用NameNode就会接管它的任务并开始服务客户端,不会有任何明显中断。
- 主备NameNode之间需要通过共享存储系统实现journal的共享。在进行主备切换的时候,备用NameNode在确认元数据完全同步之后才能继续对外提供服务。
- DataNode需要同时向两个NameNode发送块报告,因为数据块的映射信息存储在NameNode的内存中,而非磁盘。
- 客户端需要使用特定的机制来处理NameNode的失效问题,这一机制对用户是透明的。
- 备用NameNode可以周期性为活动NameNode设置检查点,类似CheckpointNode的功能,因此在HA模式下,无法启动BackupNode和CheckpointNode
机制
心跳
在运行期间,DataNode每隔3秒(默认)向NameNode发送心跳,证明DataNode正在运行并且数据块是可获得的。如果NameNode十分钟没有接收到心跳,则认为该DataNode故障或者停止服务,计划在其他DataNode上创建块副本。
心跳中包含DataNode的总存储空间,已用空间和正在传输的数据大小,这些数据将用于DataNode的空间分配和负载均衡策略。
NameNode会在接收到心跳时,向DataNode回复指令:发送块副本到其他结点,移除本地块副本,关闭或重新注册结点,立即发送块报告。
机架感知
一般来说,同一个机架的结点通过一个交换机来通信,而不同机架之间的通信需要通过更多的交换机,所以同一个机架间结点的网络带宽要大于不同机架间结点的带宽。
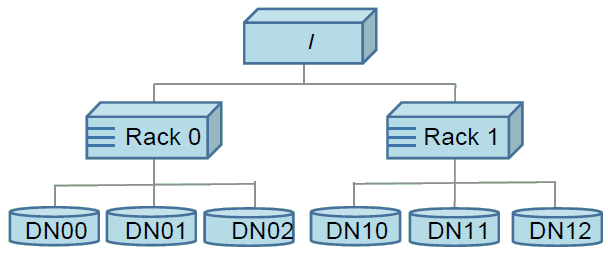
如图所示,由于机架间的带宽不同,HDFS规定结点到父结点的距离假定为1。两结点的距离为两者到其最近的共同祖先的距离和。在DataNode向NameNode注册时,NameNode会根据用户自定义的脚本确定该DataNode所属的机架,如果不指定脚本则默认所有DataNode从属于一个机架。
副本管理
副本摆放需要在可靠性与效率之间进行权衡。如果副本摆放过于分散,那么可靠性会增加但效率就会下降,反之亦然。
- 一个DataNode最多只能存储一个副本
- 一个机架内最多只能存放两个副本
NameNode通过DataNode的块报告,对DataNode进行块管理。如果块副本过少,会将该块放入优先队列里,复制因子越小的块优先复制;如果过多,优先删除硬盘使用率高的DataNode上的副本。
负载均衡
负载均衡使每个DataNode的空间使用率尽可能趋于相等。定义结点的空间利用率-集群的空间利用率为结点的不平衡度。用户设置一个处于0~1的阈值,如果不平衡度小于阈值,则可以认为集群是平衡的。当结点不平衡时,均衡器会对不均匀分布的数据进行移动,将利用率高的结点上的副本移动到利用率低的结点上,移动过程中会考虑副本摆放策略。
快照
系统升级的时候,数据丢失问题出现的可能性会增加,HDFS引入了快照,能够描述整个集群的信息。
- NameNode读入checkpoint和journal,合并放入内存中,再创建一个新的checkpoint和空的journal到新的位置,旧的checkpoint和journal仍会保存
- NameNode通知DataNode创建一个本地快照。DataNode并不会直接复制块副本,而是建立块副本的硬链接。由于硬链接的性质,当删除块副本,只是删除其硬链接,块副本仍然存在。运用写时复制技术处理块副本被修改的情况。
- 回滚时,NameNode恢复之前创建的checkpoint。DataNode恢复所有重命名的目录,并且使用后台进程删除新建的块副本。
安全模式
在集群启动时,NameNode会处于一段时间的安全模式,期间不能修改HDFS的数据。在这段时间内,NameNode会做以下工作
- 合并checkpoint和journal并加载进内存
- 启动DataNode,通过DataNode的块报告和心跳信息,检查是否满足复制因子
工作完成后,会再等待30秒,然后退出安全模式
REFERENCE
[1] HDFS Architecture.
[2] SHVACHKO K, KUANG H, RADIA S, 等. The Hadoop Distributed File System[C]//2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST). Incline Village, NV, USA: IEEE, 2010: 1–10.
[3] WHITE T. Hadoop权威指南(中文版)[M]. 周傲英, 译, 曾大聃, 译. 清华大学出版社, 2010.
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/02/25/hdfs/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)