介绍Spark中的TaskSchedulerImpl及其依赖的组件
TaskResultGetter
使用线程池对序列化的本地或远程task执行结果进行反序列化,以得到task执行结果。有以下重要的属性
scheduler:TaskSchedulerImplTHREADS: 获取task执行结果的线程数。通过spark.resultGetter.threads属性配置,默认为4getTaskResultExecutor: 固定大小为THREADS的线程池Executors.newFixedThreadPoolserializer:ThreadLocal[SerializerInstance],通过使用本地线程缓存,保证在使用SerializerInstance时是线程安全的taskResultSerializer:ThreadLocal[SerializerInstance],通过使用本地线程缓存,保证在使用SerializerInstance对task的执行结果进行反序列化时是线程安全的
有以下两个成员方法用于处理执行成功和失败的task
enqueueSuccessfulTask(): 向线程池提交反序列serializedData的任务,并交由TaskSetManager处理- 向
getTaskResultExecutor的线程池中提交以下任务 - 对
serializedData使用serializer进行反序列化,如果是得到DirectTaskResult,说明task结果在本地。首先检查获取该task结果后会不会超出maxResultSize,如果超过大小则kill这个task,否则用taskResultSerializer对task结果中保存的数据进行反序列 - 如果得到的是
IndirectTaskResult,说明task结果在远端。首先检查获取该task结果后会不会超出maxResultSize,如果超过大小则调用BlockManagerMaster.removeBlock()删除远端block并kill这个task。否则调用BlockManager.getRemoteBytes()获取远端block数据,并使用serializer反序列化block数据得到DirectTaskResult,调用taskResultSerializer对task结果中保存的数据进行反序列 - 最后调用
TaskSchedulerImpl.handleSuccessfulTask()方法,实际上调用了TaskSetManager.handleSuccessfulTask()方法去处理反序列化后的task结果
// TaskSetManager def canFetchMoreResults(size: Long): Boolean = sched.synchronized { totalResultSize += size calculatedTasks += 1 if (maxResultSize > 0 && totalResultSize > maxResultSize) { val msg = s"Total size of serialized results of ${calculatedTasks} tasks " + s"(${Utils.bytesToString(totalResultSize)}) is bigger than spark.driver.maxResultSize " + s"(${Utils.bytesToString(maxResultSize)})" logError(msg) abort(msg) false } else { true } } def enqueueSuccessfulTask( taskSetManager: TaskSetManager, tid: Long, serializedData: ByteBuffer): Unit = { getTaskResultExecutor.execute(new Runnable { override def run(): Unit = Utils.logUncaughtExceptions { try { val (result, size) = serializer.get().deserialize[TaskResult[_]](serializedData) match { case directResult: DirectTaskResult[_] => if (!taskSetManager.canFetchMoreResults(serializedData.limit())) { // kill the task so that it will not become zombie task scheduler.handleFailedTask(taskSetManager, tid, TaskState.KILLED, TaskKilled( "Tasks result size has exceeded maxResultSize")) return } // deserialize "value" without holding any lock so that it won't block other threads. // We should call it here, so that when it's called again in // "TaskSetManager.handleSuccessfulTask", it does not need to deserialize the value. directResult.value(taskResultSerializer.get()) (directResult, serializedData.limit()) case IndirectTaskResult(blockId, size) => if (!taskSetManager.canFetchMoreResults(size)) { // dropped by executor if size is larger than maxResultSize sparkEnv.blockManager.master.removeBlock(blockId) // kill the task so that it will not become zombie task scheduler.handleFailedTask(taskSetManager, tid, TaskState.KILLED, TaskKilled( "Tasks result size has exceeded maxResultSize")) return } logDebug("Fetching indirect task result for TID %s".format(tid)) scheduler.handleTaskGettingResult(taskSetManager, tid) val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId) if (!serializedTaskResult.isDefined) { /* We won't be able to get the task result if the machine that ran the task failed * between when the task ended and when we tried to fetch the result, or if the * block manager had to flush the result. */ scheduler.handleFailedTask( taskSetManager, tid, TaskState.FINISHED, TaskResultLost) return } val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]]( serializedTaskResult.get.toByteBuffer) // force deserialization of referenced value deserializedResult.value(taskResultSerializer.get()) sparkEnv.blockManager.master.removeBlock(blockId) (deserializedResult, size) } // Set the task result size in the accumulator updates received from the executors. // We need to do this here on the driver because if we did this on the executors then // we would have to serialize the result again after updating the size. result.accumUpdates = result.accumUpdates.map { a => if (a.name == Some(InternalAccumulator.RESULT_SIZE)) { val acc = a.asInstanceOf[LongAccumulator] assert(acc.sum == 0L, "task result size should not have been set on the executors") acc.setValue(size.toLong) acc } else { a } } scheduler.handleSuccessfulTask(taskSetManager, tid, result) } catch { case cnf: ClassNotFoundException => val loader = Thread.currentThread.getContextClassLoader taskSetManager.abort("ClassNotFound with classloader: " + loader) // Matching NonFatal so we don't catch the ControlThrowable from the "return" above. case NonFatal(ex) => logError("Exception while getting task result", ex) taskSetManager.abort("Exception while getting task result: %s".format(ex)) } } }) }- 向
enqueueFailedTask(): 反序列task失败原因并交由TaskSetManager处理- 对执行结果反序列化,得到类型为
TaskFailedReason的失败原因 - 调用
TaskSchedulerImpl.handleFailedTask(),实际内部调用了TaskSetManager.handleFailedTask()方法去处理task失败的情况
def enqueueFailedTask(taskSetManager: TaskSetManager, tid: Long, taskState: TaskState, serializedData: ByteBuffer) { var reason : TaskFailedReason = UnknownReason try { getTaskResultExecutor.execute(new Runnable { override def run(): Unit = Utils.logUncaughtExceptions { val loader = Utils.getContextOrSparkClassLoader try { if (serializedData != null && serializedData.limit() > 0) { reason = serializer.get().deserialize[TaskFailedReason]( serializedData, loader) } } catch { case cnd: ClassNotFoundException => // Log an error but keep going here -- the task failed, so not catastrophic // if we can't deserialize the reason. logError( "Could not deserialize TaskEndReason: ClassNotFound with classloader " + loader) case ex: Exception => // No-op } finally { // If there's an error while deserializing the TaskEndReason, this Runnable // will die. Still tell the scheduler about the task failure, to avoid a hang // where the scheduler thinks the task is still running. scheduler.handleFailedTask(taskSetManager, tid, taskState, reason) } } }) } catch { case e: RejectedExecutionException if sparkEnv.isStopped => // ignore it } }- 对执行结果反序列化,得到类型为
LauncherBackend
用户应用程序使用LauncherServer与Spark应用程序通信。TaskSchedulerImpl的底层依赖于LauncherBackend,LauncherBackend依赖于BackendConnection跟LauncherServer进行通信
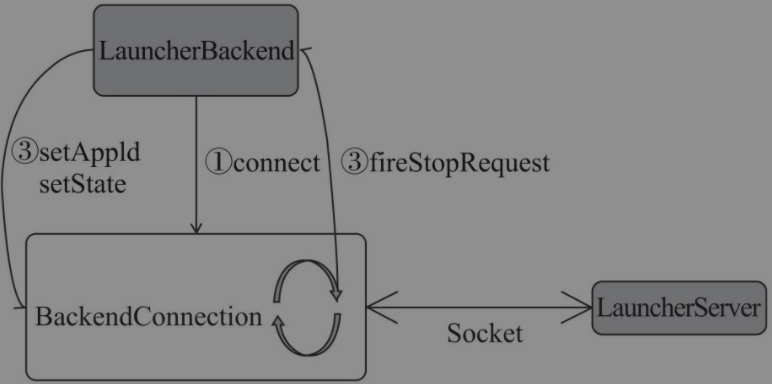
- 调用
LauncherBackend.connect()方法创建BackendConnection,并且创建线程执行。构造BackendConnection的过程中,BackendConnection会和LauncherServer之间建立起Socket连接,并不断从Socket连接中读取LauncherServer发送的数据 - 调用
LauncherBackend.setAppId()方法或SetState()方法,通过Socket连接向LauncherServer发送SetAppId消息或SetState消息 - LauncherServer发送stop消息。
BackendConnection从Socket连接中读取到LauncherServer发送的Stop消息,然后调用LauncherBackend.fireStopRequest()方法停止请求。
SchedulerBackend
SchedulerBackend是TaskScheduler的调度后端接口。TaskScheduler给task分配资源实际是通过SchedulerBackend来完成的,SchedulerBackend给task分配完资源后将与分配给task的Executor通信,并要求后者运行Task
特质SchedulerBackend定义了接口规范,如下所示
appId,applicationId(): 当前job的app idstart(): 启动SchedulerBackendstop():停止SchedulerBackendreviveOffers(): 给调度池中的所有task分配资源defaultParallelism(): 获取job的默认并行度killTask(): 向Executor请求kill指定taskisReady():SchedulerBackend是否准备就绪getDriverLogUrls(): 获取Driver日志的Url。这些Url将被用于在Spark UI的Executors标签页中展示
如图所示,有以下实现类
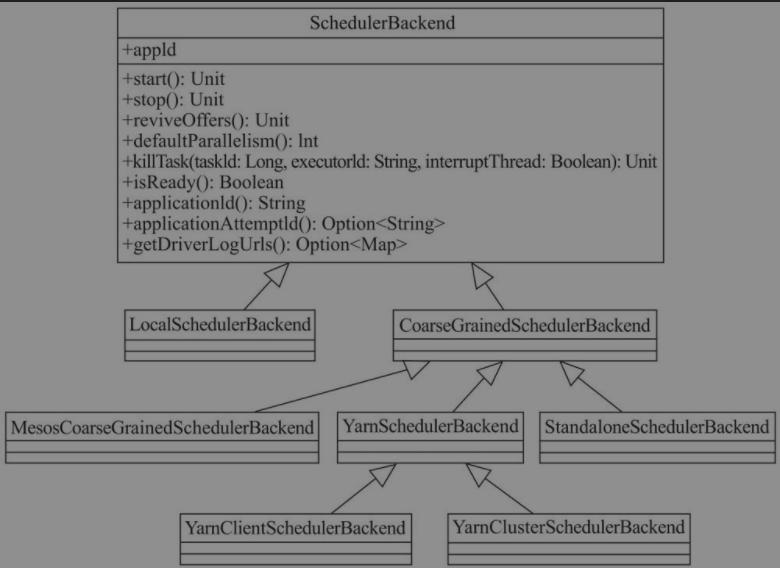
LocalSchedulerBackend: local模式中的调度后端接口。在local模式下,Executor、LocalSchedulerBackend、Driver都运行在同一个JVM进程中。CoarseGrainedSchedulerBackend: 由CoarseGrainedSchedulerBackend建立的CoarseGrainedExecutorBackend进程将会一直存在,真正的Executor线程将在CoarseGrainedExecutorBackend进程中执行,其子类分别代表了standalone, yarn-cluster, yarn-client, mesos等部署模式
LocalEndpoint
与LocalSchedulerBackend进行通信,LocalSchedulerBackend中保存有LocalEndpoint的RpcEndpointRef,并将命令传递给Executor。有以下成员属性
userClassPath:Seq[URL]。用户指定的ClassPathscheduler: Driver中的TaskSchedulerImplexecutorBackend: 与LocalEndpoint相关联的LocalSchedulerBackendtotalCores: 用于执行任务的CPU内核总数。local模式下,totalCores固定为1freeCores: 空闲的CPU内核数。应用程序提交的Task正式运行之前,freeCores与totalCores相等localExecutorId: local部署模式下,固定为driverlocalExecutorHostname: local部署模式下,固定为localhostexecutor: 此Executor在LocalEndpoint构造的过程中就已经实例化new Executor(localExecutorId, localExecutorHostname, SparkEnv.get, userClassPath, isLocal = true)
LocalEndpoint继承了ThreadSafeRpcEndpoint,重写了receive()和receiveAndReply()方法以实现消息的接收处理
reviveOffers(): 给调度池中task分配资源并执行- 创建
WorkerOffer序列用于标识每个Executor上的资源 - 调用
scheduler.resourceOffers()获取需要分配资源的task,实际上将task的调度交由TaskScheduler执行,并在此Executor上执行task
def reviveOffers() { val offers = IndexedSeq(new WorkerOffer(localExecutorId, localExecutorHostname, freeCores, Some(rpcEnv.address.hostPort))) for (task <- scheduler.resourceOffers(offers).flatten) { freeCores -= scheduler.CPUS_PER_TASK executor.launchTask(executorBackend, task) } }- 创建
receive(): 处理消息- 如果是
ReviveOffers消息,则会调用reviveOffers()给task分配资源并调度执行 - 如果是
StatusUpdate消息,则会调用scheduler.statusUpdate()更新task状态,如果已完成则回收资源并调用receiveOffers() - 如果是
KillTask消息,则调用executor.killTask()kill掉task
override def receive: PartialFunction[Any, Unit] = { case ReviveOffers => reviveOffers() case StatusUpdate(taskId, state, serializedData) => scheduler.statusUpdate(taskId, state, serializedData) if (TaskState.isFinished(state)) { freeCores += scheduler.CPUS_PER_TASK reviveOffers() } case KillTask(taskId, interruptThread, reason) => executor.killTask(taskId, interruptThread, reason) }- 如果是
receiveAndReply(): 只处理StopExecutor消息,调用executor.stop()停止Executor并响应
LocalSchedulerBackend
TaskSchedulerImpl通过LocalSchedulerBackend与LocalEndpoint进行消息交互并在Executor上执行task。下面是重要的成员属性
conf:SparkConfscheduler:TaskSchedulerImpltotalCores: 固定为1localEndpoint:LocalEndpoint的NettyRpcEndpointRefuserClassPath:Seq[URL]。用户指定的类路径。通过spark.executor.extraClassPath属性进行配置listenerBus:LiveListenerBuslauncherBackend:LauncherBackend的匿名实现类的实例
下面是实现的重要的成员方法
start(): 启动- 注册
LocalEndpoint的NettyRpcEndpointRef - 向
listenerBus投递SparkListenerExecutorAdded - 调用
LauncherBackend向LauncherServer发送SetAppId和SetState消息
override def start() { val rpcEnv = SparkEnv.get.rpcEnv val executorEndpoint = new LocalEndpoint(rpcEnv, userClassPath, scheduler, this, totalCores) localEndpoint = rpcEnv.setupEndpoint("LocalSchedulerBackendEndpoint", executorEndpoint) listenerBus.post(SparkListenerExecutorAdded( System.currentTimeMillis, executorEndpoint.localExecutorId, new ExecutorInfo(executorEndpoint.localExecutorHostname, totalCores, Map.empty))) launcherBackend.setAppId(appId) launcherBackend.setState(SparkAppHandle.State.RUNNING) }- 注册
reviveOffers(),killTask(),statusUpdate(): 向localEndpoint发送对应的消息
TaskSchedulerImpl
特质TaskScheduler,定义了task调度的接口规范,只有一个实现类TaskSchedulerImpl。负责接收DAGScheduler给每个Stage创建的TaskSet,按照调度算法将资源分配给task,将task交给Spark集群不同节点上的Executor运行,在这些task执行失败时进行重试,通过推测执行减轻落后的task对整体作业进度的影响。有以下重要的成员属性
sc:SparkContextmaxTaskFailures: task失败的最大次数isLocal: 是否是Local部署模式conf:SparkConfSPECULATION_INTERVAL_MS: 检测task是否需要推测执行的时间间隔。通过spark.speculation.interval属性进行配置,默认为100msMIN_TIME_TO_SPECULATION: task至少需要运行的时间。task只有超过此时间限制,才允许推测执行,启动副本task。避免对小task开启推测执行。固定为100speculationScheduler: 对task进行推测执行的线程池,以task-scheduler-speculation为前缀,且线程池的大小为1STARVATION_TIMEOUT_MS: 判断TaskSet饥饿的阈值。通过spark.starvation. timeout属性配置,默认为15sCPUS_PER_TASK: 每个task需要分配的CPU核数。通过spark.task.cpus属性配置,默认为1taskSetsByStageIdAndAttempt:HashMap[Int, HashMap[Int,TaskSetManager]],stage id与task尝试id和TaskSetManager的对应关系taskIdToTaskSetManager: task与TaskSetManager的映射关系。taskIdToExecutorId: task与执行此task的Executor的映射关系hasReceivedTask: 标记TaskSchedulerImpl是否已经接收到taskhasLaunchedTask: 标记TaskSchedulerImpl接收的task是否已经有运行过的starvationTimer: 处理饥饿的定时器nextTaskId:AtomicLong,用于提交task生成task idexecutorIdToRunningTaskIds:HashMap[String, HashSet[Long]],Executor和运行在其上的task之间的映射关系,由此看出一个Executor上可以运行多个TaskhostToExecutors:HashMap[String, HashSet[String]],Host(机器)与运行在此Host上的Executor之间的映射关系,由此可以看出一个Host上可以有多个ExecutorhostsByRack:HashMap[String,HashSet[String]],机架和机架上Host(机器)之间的映射关系executorIdToHost: Executor与Executor运行所在Host(机器)的映射关系backend: 调度后端接口SchedulerBackendmapOutputTracker:MapOutputTrackerMasterrootPool: 根调度池schedulingModeConf: 调度模式名称。通过spark.scheduler.mode属性配置,默认为FIFOschedulingMode: 调度模式枚举类。根据schedulingModeConf获得
下面是重要成员方法
initialize(): 初始化调度器,构建调度池def initialize(backend: SchedulerBackend) { this.backend = backend schedulableBuilder = { schedulingMode match { case SchedulingMode.FIFO => new FIFOSchedulableBuilder(rootPool) case SchedulingMode.FAIR => new FairSchedulableBuilder(rootPool, conf) case _ => throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " + s"$schedulingMode") } } schedulableBuilder.buildPools() }start(): 启动调度器,如果不是在Local模式下并且开启了推测执行(spark.speculation, 默认为false),则使用speculationScheduler设置一个执行间隔为SPECULATION_INTERVAL_MS的定时检查可推测执行task的定时器override def start() { backend.start() if (!isLocal && conf.getBoolean("spark.speculation", false)) { logInfo("Starting speculative execution thread") speculationScheduler.scheduleWithFixedDelay(new Runnable { override def run(): Unit = Utils.tryOrStopSparkContext(sc) { checkSpeculatableTasks() } }, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS) } }checkSpeculatableTasks(): 检查可推测执行的task。实际调用了根调度池的checkSpeculatableTasks,如果需要推测执行则调用SchedulerBackend.reviveOffers()对LocalEndpoint发送消息,并最终分配资源以运行taskdef checkSpeculatableTasks() { var shouldRevive = false synchronized { shouldRevive = rootPool.checkSpeculatableTasks(MIN_TIME_TO_SPECULATION) } if (shouldRevive) { backend.reviveOffers() } }submitTasks(): 提交TaskSet,由DAGScheduler调用- 由传递的
TaskSet创建TaskSetManager并在成员属性中注册 - 该stage的所有已有
TaskSetManager都标记为僵尸状态,因为stage只有一个存活的TaskSetManager - 调用
schedulableBuilder.addTaskSetManager()将TaskSet放入调度池中 - 如果当前应用程序不是Local模式并且没有接收到task,则调用
starvationTimer开启一个定时器检查hasLaunchedTask成员变量,并不断打印warning日志警告worker没有分配足够的资源,直到有任务执行并退出 - 调用
backend.reviveOffers()在Executor上分配资源并运行task
private[scheduler] def createTaskSetManager( taskSet: TaskSet, maxTaskFailures: Int): TaskSetManager = { new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt) } override def submitTasks(taskSet: TaskSet) { val tasks = taskSet.tasks logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks") this.synchronized { val manager = createTaskSetManager(taskSet, maxTaskFailures) val stage = taskSet.stageId val stageTaskSets = taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager]) stageTaskSets.foreach { case (_, ts) => ts.isZombie = true } stageTaskSets(taskSet.stageAttemptId) = manager schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) if (!isLocal && !hasReceivedTask) { starvationTimer.scheduleAtFixedRate(new TimerTask() { override def run() { if (!hasLaunchedTask) { logWarning("Initial job has not accepted any resources; " + "check your cluster UI to ensure that workers are registered " + "and have sufficient resources") } else { this.cancel() } } }, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS) } hasReceivedTask = true } backend.reviveOffers() }- 由传递的
resourceOfferSingleTaskSet(): 给单个TaskSet提供资源- 遍历每个worker资源,如果可用cpu数大于单个task所需的cpu数,则开始分配资源
- 调用
TaskSetManager.resourceOffer()由延迟调度策略返回一个task的TaskDescription - 在成员属性中注册此task并更新
availableCpus - 如果使用了屏障调度器则更新传入参数
addressesWithDescs
private def resourceOfferSingleTaskSet( taskSet: TaskSetManager, maxLocality: TaskLocality, shuffledOffers: Seq[WorkerOffer], availableCpus: Array[Int], tasks: IndexedSeq[ArrayBuffer[TaskDescription]], addressesWithDescs: ArrayBuffer[(String, TaskDescription)]) : Boolean = { var launchedTask = false // nodes and executors that are blacklisted for the entire application have already been // filtered out by this point for (i <- 0 until shuffledOffers.size) { val execId = shuffledOffers(i).executorId val host = shuffledOffers(i).host if (availableCpus(i) >= CPUS_PER_TASK) { try { for (task <- taskSet.resourceOffer(execId, host, maxLocality)) { tasks(i) += task val tid = task.taskId taskIdToTaskSetManager.put(tid, taskSet) taskIdToExecutorId(tid) = execId executorIdToRunningTaskIds(execId).add(tid) availableCpus(i) -= CPUS_PER_TASK assert(availableCpus(i) >= 0) // Only update hosts for a barrier task. if (taskSet.isBarrier) { // The executor address is expected to be non empty. addressesWithDescs += (shuffledOffers(i).address.get -> task) } launchedTask = true } } catch { case e: TaskNotSerializableException => logError(s"Resource offer failed, task set ${taskSet.name} was not serializable") // Do not offer resources for this task, but don't throw an error to allow other // task sets to be submitted. return launchedTask } } } return launchedTask }resourceOffers(): 由集群管理器调用给task在Executor上分配资源- 遍历worker资源列表,更新Host, Executor和机架的映射关系,更新黑名单列表,如果有新加入的executor则调用
TaskSetManager.executorAdded()重新计算task的本地性 - 对worker资源列表进行重新洗牌,避免总将task分配给一个worker
- 根据每个worker资源的cpu数量以生成
TaskDescription数组的列表tasks,每个worker可用cpu数量列表availableCpus列表 - 调用
rootPool.getSortedTaskSetQueue()获取按照调度算法排序好的调度池中的所有TaskSetManager - 遍历之前排序好的
TaskSetManager,跳过屏障调度的TaskSetManager并且资源不够执行的TaskSetManager。按其允许的本地性等级(即TaskSetManager.myLocalityLevels属性)从高到低作为参数,调用resourceOfferSingleTaskSet()给每个TaskSetManager分配资源。如果没有给任何task分配资源则做失败处理,如果使用了屏障调度并且并没有给所有task都分配资源则抛出异常并终止 - 标记
hasLaunchedTask已执行task并返回获得资源的task列表
protected def shuffleOffers(offers: IndexedSeq[WorkerOffer]): IndexedSeq[WorkerOffer] = { Random.shuffle(offers) } def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized { var newExecAvail = false for (o <- offers) { if (!hostToExecutors.contains(o.host)) { hostToExecutors(o.host) = new HashSet[String]() } if (!executorIdToRunningTaskIds.contains(o.executorId)) { hostToExecutors(o.host) += o.executorId executorAdded(o.executorId, o.host) executorIdToHost(o.executorId) = o.host executorIdToRunningTaskIds(o.executorId) = HashSet[Long]() newExecAvail = true } for (rack <- getRackForHost(o.host)) { hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host } } blacklistTrackerOpt.foreach(_.applyBlacklistTimeout()) val filteredOffers = blacklistTrackerOpt.map { blacklistTracker => offers.filter { offer => !blacklistTracker.isNodeBlacklisted(offer.host) && !blacklistTracker.isExecutorBlacklisted(offer.executorId) } }.getOrElse(offers) val shuffledOffers = shuffleOffers(filteredOffers) // Build a list of tasks to assign to each worker. val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores / CPUS_PER_TASK)) val availableCpus = shuffledOffers.map(o => o.cores).toArray val sortedTaskSets = rootPool.getSortedTaskSetQueue for (taskSet <- sortedTaskSets) { logDebug("parentName: %s, name: %s, runningTasks: %s".format( taskSet.parent.name, taskSet.name, taskSet.runningTasks)) if (newExecAvail) { taskSet.executorAdded() } } for (taskSet <- sortedTaskSets) { val availableSlots = availableCpus.map(c => c / CPUS_PER_TASK).sum if (taskSet.isBarrier && availableSlots < taskSet.numTasks) { logInfo(s"Skip current round of resource offers for barrier stage ${taskSet.stageId} " + s"because the barrier taskSet requires ${taskSet.numTasks} slots, while the total " + s"number of available slots is $availableSlots.") } else { var launchedAnyTask = false // Record all the executor IDs assigned barrier tasks on. val addressesWithDescs = ArrayBuffer[(String, TaskDescription)]() for (currentMaxLocality <- taskSet.myLocalityLevels) { var launchedTaskAtCurrentMaxLocality = false do { launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks, addressesWithDescs) launchedAnyTask |= launchedTaskAtCurrentMaxLocality } while (launchedTaskAtCurrentMaxLocality) } if (!launchedAnyTask) { taskSet.getCompletelyBlacklistedTaskIfAny(hostToExecutors).foreach { taskIndex => executorIdToRunningTaskIds.find(x => !isExecutorBusy(x._1)) match { case Some ((executorId, _)) => if (!unschedulableTaskSetToExpiryTime.contains(taskSet)) { blacklistTrackerOpt.foreach(blt => blt.killBlacklistedIdleExecutor(executorId)) val timeout = conf.get(config.UNSCHEDULABLE_TASKSET_TIMEOUT) * 1000 unschedulableTaskSetToExpiryTime(taskSet) = clock.getTimeMillis() + timeout logInfo(s"Waiting for $timeout ms for completely " + s"blacklisted task to be schedulable again before aborting $taskSet.") abortTimer.schedule( createUnschedulableTaskSetAbortTimer(taskSet, taskIndex), timeout) } case None => // Abort Immediately logInfo("Cannot schedule any task because of complete blacklisting. No idle" + s" executors can be found to kill. Aborting $taskSet." ) taskSet.abortSinceCompletelyBlacklisted(taskIndex) } } } else { if (unschedulableTaskSetToExpiryTime.nonEmpty) { logInfo("Clearing the expiry times for all unschedulable taskSets as a task was " + "recently scheduled.") unschedulableTaskSetToExpiryTime.clear() } } if (launchedAnyTask && taskSet.isBarrier) { if (addressesWithDescs.size != taskSet.numTasks) { val errorMsg = s"Fail resource offers for barrier stage ${taskSet.stageId} because only " + s"${addressesWithDescs.size} out of a total number of ${taskSet.numTasks}" + s" tasks got resource offers. This happens because barrier execution currently " + s"does not work gracefully with delay scheduling. We highly recommend you to " + s"disable delay scheduling by setting spark.locality.wait=0 as a workaround if " + s"you see this error frequently." logWarning(errorMsg) taskSet.abort(errorMsg) throw new SparkException(errorMsg) } // materialize the barrier coordinator. maybeInitBarrierCoordinator() // Update the taskInfos into all the barrier task properties. val addressesStr = addressesWithDescs // Addresses ordered by partitionId .sortBy(_._2.partitionId) .map(_._1) .mkString(",") addressesWithDescs.foreach(_._2.properties.setProperty("addresses", addressesStr)) logInfo(s"Successfully scheduled all the ${addressesWithDescs.size} tasks for barrier " + s"stage ${taskSet.stageId}.") } } } if (tasks.size > 0) { hasLaunchedTask = true } return tasks }- 遍历worker资源列表,更新Host, Executor和机架的映射关系,更新黑名单列表,如果有新加入的executor则调用
statusUpdate(): 用于更新task的状态(LAUNCHING, RUNNING, FINISHED, FAILED, KILLED, LOST)- 由task id获取到对应的
TasksetManager - 如果状态是LOST,调用
removeExecutor()移除运行该task的Executor,并加入黑名单 - 如果状态是完成状态(FINISHED, FAILED, KILLED, LOST),则清除在调度器中的注册信息并在
TaskSetManager中移除该运行task。如果是FINISHED状态则调用taskResultGetter.enqueueSuccessfulTask()对执行成功的task结果进行处理,如果是其他状态则调用taskResultGetter.enqueueFailedTask()对执行失败的task结果进行处理 - 如果之前移除过Executor,则调用
dagScheduler.executorLost()去处理移除Executor上的task,并调用backend.reviveOffers()给task分配资源并执行
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) { var failedExecutor: Option[String] = None var reason: Option[ExecutorLossReason] = None synchronized { try { Option(taskIdToTaskSetManager.get(tid)) match { case Some(taskSet) => if (state == TaskState.LOST) { // TaskState.LOST is only used by the deprecated Mesos fine-grained scheduling mode, // where each executor corresponds to a single task, so mark the executor as failed. val execId = taskIdToExecutorId.getOrElse(tid, { val errorMsg = "taskIdToTaskSetManager.contains(tid) <=> taskIdToExecutorId.contains(tid)" taskSet.abort(errorMsg) throw new SparkException(errorMsg) }) if (executorIdToRunningTaskIds.contains(execId)) { reason = Some( SlaveLost(s"Task $tid was lost, so marking the executor as lost as well.")) removeExecutor(execId, reason.get) failedExecutor = Some(execId) } } if (TaskState.isFinished(state)) { cleanupTaskState(tid) taskSet.removeRunningTask(tid) if (state == TaskState.FINISHED) { taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData) } else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) { taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData) } } case None => logError( ("Ignoring update with state %s for TID %s because its task set is gone (this is " + "likely the result of receiving duplicate task finished status updates) or its " + "executor has been marked as failed.") .format(state, tid)) } } catch { case e: Exception => logError("Exception in statusUpdate", e) } } // Update the DAGScheduler without holding a lock on this, since that can deadlock if (failedExecutor.isDefined) { assert(reason.isDefined) dagScheduler.executorLost(failedExecutor.get, reason.get) backend.reviveOffers() } }- 由task id获取到对应的
总结
如图所示,推测执行的一般过程
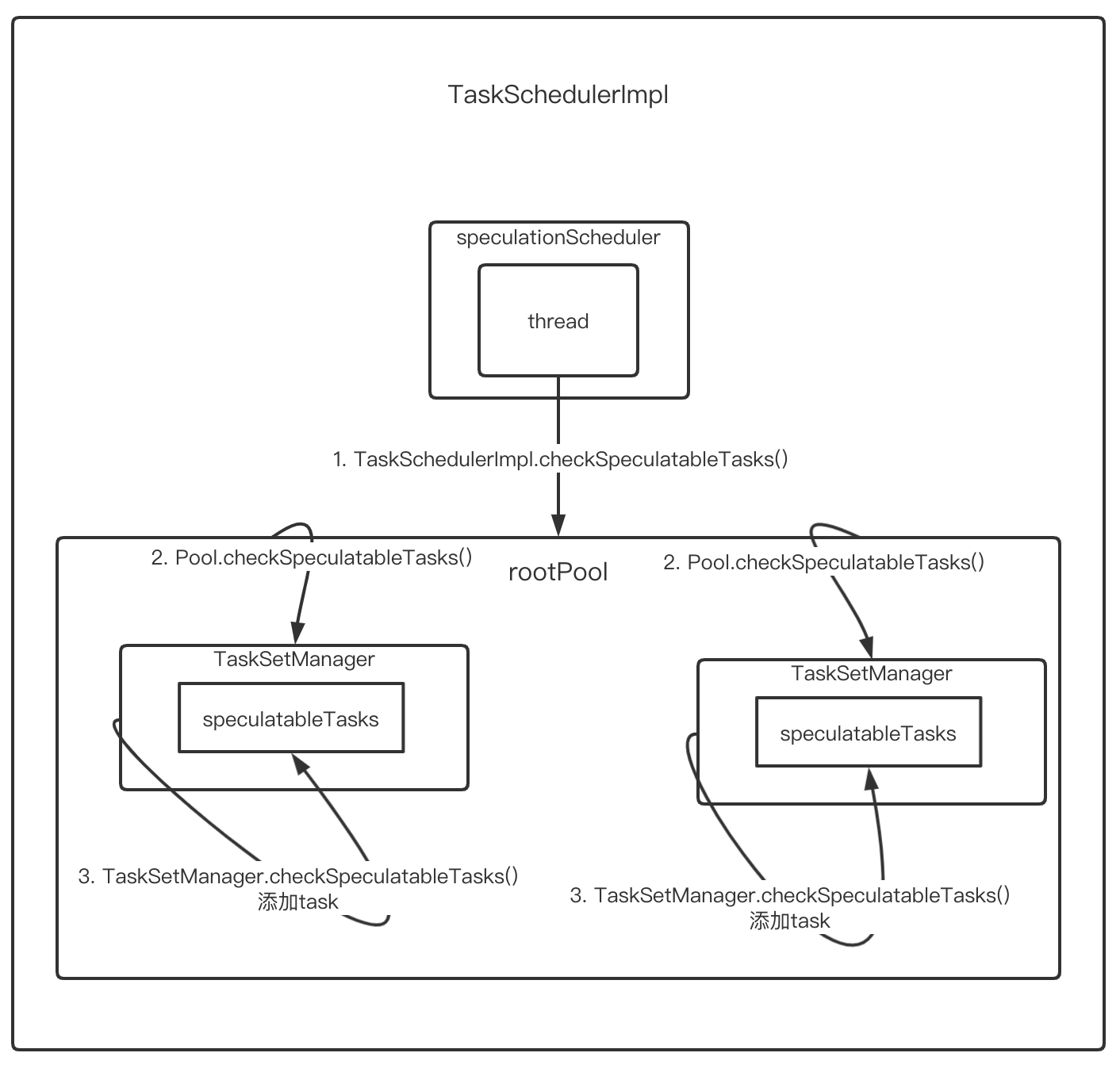
- 由
speculationScheduler线程池创建的单个线程在固定间隔时间不断调用TaskSchedulerImpl.checkSpeculatableTasks() - 实际调用了根调度池的
checkSpeculatableTasks()方法 - 跟调度器又会不断的递归调用直至传递给
TaskSetManager,判断推测执行的条件并向speculatableTasks列表添加需要推测执行的任务。 - 在
speculatableTasks列表中的推测task会由TaskSetManager.dequeueTask()方法和DAGSchuler提交的task一起被取出,这部分由TaskSchedulerImpl进行调度。实际上TaskSchedulerImpl调用的是TaskSetManager.resourceOffer()但是其内部调用了TaskSetManager.dequeueTask()
如图所示,表示TaskSchedulerImpl的task调度流程
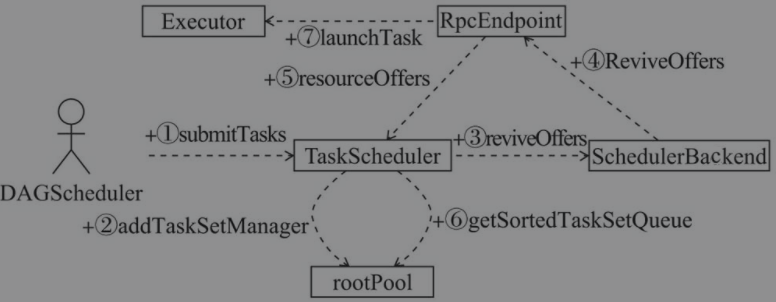
DAGScheduler.submitMissingTasks()内部调用了TaskScheduler.submitTasks()提交了一个TaskSetTaskScheduler接收到TaskSet后,创建TaskSetManager并通过调度池构建器放入根调度池中- 调用
SchedulerBackend.reviveOffers()准备在worker上分配资源以执行task - 第3步调用方法后,会向
RpcEndpoint发送ReviveOffers消息 RpcEndpoint接收到这个消息后,调用自身的resourceOffers()方法,其内部调用了TaskScheduler.resourceOffers()传递本地的Worker资源,第6步中详述了这一过程TaskScheduler调用根调度池的getSortedTaskSetQueue()方法获得按照调度算法排序后的所有TaskSetManager,对每个Taskset做以下操作,直到返回可以在这些Worker上执行所有task- 迭代可用的worker资源列表
- 迭代调用
TaskSetManager.resourceOffer()按照最大本地性原则和延迟调度策略选择其中的task - 为task创建尝试执行信息、序列化、生成TaskDescription等
- 在
RpcEndpoint.resourceOffers()中,已经由第6步返回了可在本地Worker上执行的task列表,调用Executor.launchTask()进行task尝试
如图所示,表示TaskschedulerImpl对task执行结果处理流程
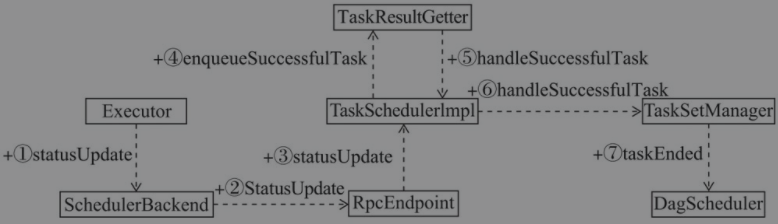
- Executor在执行task的过程中,不断将task的状态通过调用
SchedulerBackend.statusUpdate()发送更新task的状态。当task执行成功后,也会将task的完成状态通知SchedulerBackend - 在
SchedulerBackend.statusUpdate()方法内,SchedulerBackend将task的状态封装为StatusUpdate消息通过RpcEndpointRef发送给RpcEndpoint RpcEndpoint接收到StatusUpdate消息后,由receive()方法对消息处理,内部调用TaskSchedulerImpl.statusUpdate()方法,并且如果task完成会释放cpu并给新的task分配资源运行- 在
TaskSchedulerImpl.statusUpdate()方法内部,如果状态为FINISHED,则调用TaskResultGetter.enqueueSuccessfulTask()方法 - 在
TaskResultGetter.enqueueSuccessfulTask()方法内部,将向线程池提交以下任务- 对
DirectTaskResult类型的结果进行反序列化得到执行结果 - 对于
IndirectTaskResult类型的结果需要先从远端下载block数据,然后再进行反序列化得到执行结果 - 调用
TaskSchedulerImpl.handleSuccessfulTask()处理反序列后的执行结果
- 对
TaskSchedulerImpl.handleSuccessfulTask()方法内部实际上调用了TaskSetManager.handleSuccessfulTask()TaskSetManager.handleSuccessfulTask()方法内部对执行成功的task做了必要的标记之后,就调用DAGScheduler.taskEnded()方法对执行结果处理。向DAGSchedulerEventProcessLoop投递CompletionEvent事件,实际上交由DAGScheduler.handleTaskCompletion()处理。- 如果是
ResultTask,如果所有ResultTask都执行成功,则标记ResultStage为成功,并调用JobWaiter.resultHandler()回调函数来处理Job中每个Task的执行结果 - 如果是
ShuffleMapTask,调用MapOutputTrackerMaster.registerMapOutput()将完成信息注册。如果所有partition都执行完了,则判断shuffleStage.isAvailable并进行失败重试,否则标记stage成功并调用submitWaitingChildStages()方法处理子stage
- 如果是
REFERENCE
- Spark内核设计的艺术:架构设计与实现
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/15/schedule-task/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)