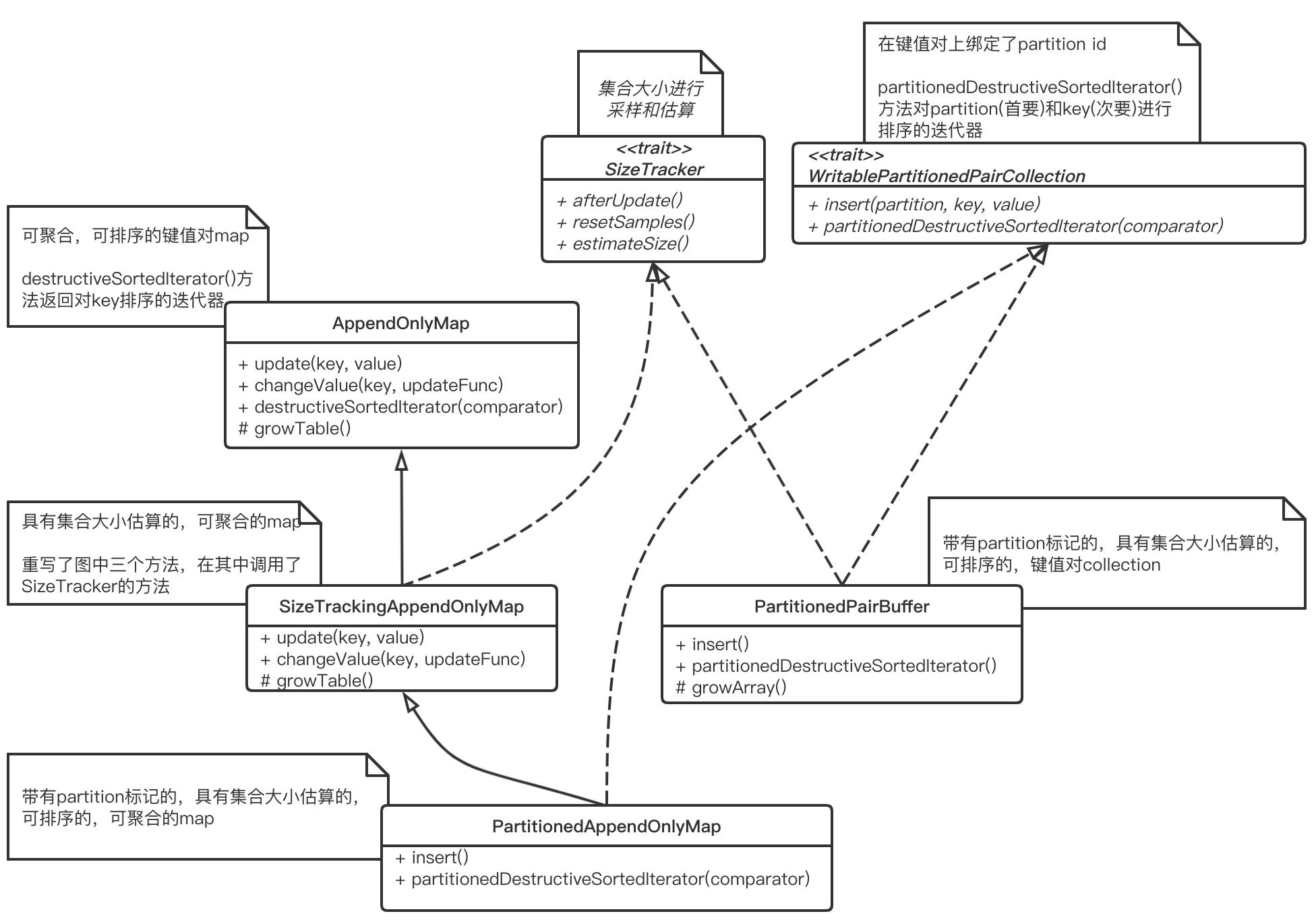
主要介绍了AppendOnlyMap与PartitionedPairBuffer两种Spark自己实现的类似map和colletion的数据结构,对大量聚合运算进行了优化且实现了采样估计集合大小的特性
SizeTracker
特质SizeTracker定义了对集合大小进行采样和估算的规范。有以下成员变量
SAMPLE_GROWTH_RATE: 采样增长的速率,固定为1.1samples:mutable.Queue[Sample]样本队列。最后两个样本将被用于估算集合大小case class Sample(size: Long, numUpdates: Long)bytesPerUpdate: 平均每次更新的字节数numUpdates: 从上一次resetSamples()后更新操作(包括插入和更新)的总次数nextSampleNum: 下次采样时,numUpdates的值。即numUpdates的值增长到与nextSampleNum相同时,才会再次采样
有以下成员方法
takeSample(): 采集样本- 调用
SizeEstimator.estimate()方法估算本集合的大小,并将估算的大小和更新次数numUpdates作为样本放入队列samples中 - 更新平均每次更新大小$bytesPerUpdate=max(0,\frac{cur_sample_size-pre_sample_size}{cur_sample_update-pre_sample_update})$
- 通过
numUpdates * SAMPLE_GROWTH_RATE更新nextSampleNum
private def takeSample(): Unit = { samples.enqueue(Sample(SizeEstimator.estimate(this), numUpdates)) // Only use the last two samples to extrapolate if (samples.size > 2) { samples.dequeue() } val bytesDelta = samples.toList.reverse match { case latest :: previous :: tail => (latest.size - previous.size).toDouble / (latest.numUpdates - previous.numUpdates) // If fewer than 2 samples, assume no change case _ => 0 } bytesPerUpdate = math.max(0, bytesDelta) nextSampleNum = math.ceil(numUpdates * SAMPLE_GROWTH_RATE).toLong }- 调用
resetSamples(): 重置样本protected def resetSamples(): Unit = { numUpdates = 1 nextSampleNum = 1 samples.clear() takeSample() }afterUpdate(): 向集合中更新了元素之后进行回调,以触发对集合的采样protected def afterUpdate(): Unit = { numUpdates += 1 if (nextSampleNum == numUpdates) { takeSample() } }estimateSize(): 在常数时间复杂度内对当前集合大小进行估算。返回上次采样后更新的数据大小(平均每次更新的数据大小*更新次数)与上一次采样的集合大小相加def estimateSize(): Long = { assert(samples.nonEmpty) val extrapolatedDelta = bytesPerUpdate * (numUpdates - samples.last.numUpdates) (samples.last.size + extrapolatedDelta).toLong }
WritablePartitionedPairCollection
特质WritablePartitionedPairCollection定义了对由键值对(key由键值和partition id组成)构成的集合大小估算的规范。定义了未实现的insert(),将键值对与相关联的分区插入到集合中。定义了未实现的partitionedDestructiveSortedIterator(),返回对排序后集合中的数据按照partition id的顺序进行迭代的迭代器
有以下已实现的方法
destructiveSortedWritablePartitionedIterator(): 对partitionedDestructiveSortedIterator()方法的封装,返回按顺序写入磁盘的迭代器WritablePartitionedIterator,需要传入DiskBlockObjectWriter来实现磁盘写入def destructiveSortedWritablePartitionedIterator(keyComparator: Option[Comparator[K]]) : WritablePartitionedIterator = { val it = partitionedDestructiveSortedIterator(keyComparator) new WritablePartitionedIterator { private[this] var cur = if (it.hasNext) it.next() else null def writeNext(writer: DiskBlockObjectWriter): Unit = { writer.write(cur._1._2, cur._2) cur = if (it.hasNext) it.next() else null } def hasNext(): Boolean = cur != null def nextPartition(): Int = cur._1._1 } }partitionComparator(): 伴生对象中定义的静态方法,返回对key的partition id进行升序排序的比较器partitionKeyComparator(): 伴生对象中定义的静态方法,返回对key的partition id进行升序排序的比较器,在partition id相等时根据key的键值进行比较
AppendOnlyMap
对聚合运算优化的哈希表,与HashMap的实现非常相似,但是只能添加和更新数据,最大可以支持$0.7×2^{29}$个元素
有以下成员属性
initialCapacity: 初始容量值,默认为64mask: 和key的哈希值做按位与运算的掩码,计算数据存放位置,值为capacity -1capacity: data数组的当前容量,是2的次方数,初始值为nextPowerOf2(initialCapacity)即最近的二次方数data:Array[AnyRef](2 * capacity)类型。交替保存key和value的数组,key和value各占一位,所以大小为2 * capacityLOAD_FACTOR:data数组容量增长的阈值的负载因子,常量固定为0.7growThreshold:data数组容量增长的阈值,LOAD_FACTOR * capacitycurSize: 当前数组大小haveNullValue:data数组中是否已经有了null值nullValue: value空值destroyed:data数组是否不再使用MAXIMUM_CAPACITY:1 << 29。data数组的容量不能超过MAXIMUM_CAPACITY,以防止data数组溢出
以下是成员方法
nextPowerOf2(): 返回大于等于原始数的最近的2次方数- 取二进制位的最高位,其余位补0得到新的整数
highBit - 如果
highBit与原始数相等则返回原始数,否则将highBit左移一位返回
- 取二进制位的最高位,其余位补0得到新的整数
以下是有关容量增加的方法
incrementSize(): 向data数组中插值后调用该方法,处理data容量扩增的问题。当curSize大于growThreshold时,调用growTable()方法增加data的大小private def incrementSize() { curSize += 1 if (curSize > growThreshold) { growTable() } }growTable(): 将data数组的容量扩大一倍,并且重哈希所有元素- 创建一个当前大小两倍的新数组
newData,计算出新数组的掩码 - 遍历旧数组的所有元素取出key和value,计算key的哈希值并和新的掩码进行位运算得到在新数组中的位置并放入。如果遇到哈希冲突,相对于
HashMap的拉链法,AppendOnlyMap采用线性探查去处理哈希冲突,相对来说较为节省内存但是扩容相对更复杂。因为 Spark 需要排序聚合之后的数据,排序会经常移动数据,由于相对于拉链法不存在链表结构,所以对于排序有着天然的友好性 - 更新
data,capacity,mask,growThreshold
protected def growTable() { // capacity < MAXIMUM_CAPACITY (2 ^ 29) so capacity * 2 won't overflow val newCapacity = capacity * 2 require(newCapacity <= MAXIMUM_CAPACITY, s"Can't contain more than ${growThreshold} elements") val newData = new Array[AnyRef](2 * newCapacity) val newMask = newCapacity - 1 // Insert all our old values into the new array. Note that because our old keys are // unique, there's no need to check for equality here when we insert. var oldPos = 0 while (oldPos < capacity) { if (!data(2 * oldPos).eq(null)) { val key = data(2 * oldPos) val value = data(2 * oldPos + 1) var newPos = rehash(key.hashCode) & newMask var i = 1 var keepGoing = true while (keepGoing) { val curKey = newData(2 * newPos) if (curKey.eq(null)) { newData(2 * newPos) = key newData(2 * newPos + 1) = value keepGoing = false } else { val delta = i newPos = (newPos + delta) & newMask i += 1 } } } oldPos += 1 } data = newData capacity = newCapacity mask = newMask growThreshold = (LOAD_FACTOR * newCapacity).toInt }- 创建一个当前大小两倍的新数组
下面是有关map操作的方法
update(): 更新到data数组中的键值对- 如果key为null则将value赋值给
nullValue,表示空值对应的value。但是如果data数组中还没有null还需要调用incrementSize() - 如果key不为null,由key的哈希值和掩码的位运算计算出位置,如果此位置没有key放入,则将key和value放入data数组并调用
incrementSize()。如果此位置有key并且相等,则更新value值。如果key不相等,说明出现了哈希冲突,使用线性探查解决哈希冲突
def update(key: K, value: V): Unit = { assert(!destroyed, destructionMessage) val k = key.asInstanceOf[AnyRef] if (k.eq(null)) { if (!haveNullValue) { incrementSize() } nullValue = value haveNullValue = true return } var pos = rehash(key.hashCode) & mask var i = 1 while (true) { val curKey = data(2 * pos) if (curKey.eq(null)) { data(2 * pos) = k data(2 * pos + 1) = value.asInstanceOf[AnyRef] incrementSize() // Since we added a new key return } else if (k.eq(curKey) || k.equals(curKey)) { data(2 * pos + 1) = value.asInstanceOf[AnyRef] return } else { val delta = i pos = (pos + delta) & mask i += 1 } } }- 如果key为null则将value赋值给
changeValue(): 与update()方法非常类似用于更新键值对,只不过value由updateFunc函数产生,实现了聚合功能。key为待聚合的key,updateFunc为聚合函数,传入Boolean类型参数表示key下是否有value(即是否初始化value),泛型参数表示之前该key的value- 如果key为null,则将
updateFunc(haveNullValue, nullValue)赋值给nullValue,但是如果data数组中还没有null还需要调用incrementSize() - 如果key不为null,由key的哈希值和掩码的位运算计算出位置,如果此位置没有key放入,则将key和
updateFunc(false, null.asInstanceOf[V])计算出来的value放入data数组并调用incrementSize()。如果此位置有key,则用updateFunc(true, oldValue.asInstanceOf[V])更新value值。否则说明出现了哈希冲突,使用线性探查解决哈希冲突
def changeValue(key: K, updateFunc: (Boolean, V) => V): V = { assert(!destroyed, destructionMessage) val k = key.asInstanceOf[AnyRef] if (k.eq(null)) { if (!haveNullValue) { incrementSize() } nullValue = updateFunc(haveNullValue, nullValue) haveNullValue = true return nullValue } var pos = rehash(k.hashCode) & mask var i = 1 while (true) { val curKey = data(2 * pos) if (curKey.eq(null)) { val newValue = updateFunc(false, null.asInstanceOf[V]) data(2 * pos) = k data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] incrementSize() return newValue } else if (k.eq(curKey) || k.equals(curKey)) { val newValue = updateFunc(true, data(2 * pos + 1).asInstanceOf[V]) data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] return newValue } else { val delta = i pos = (pos + delta) & mask i += 1 } } null.asInstanceOf[V] // Never reached but needed to keep compiler happy }- 如果key为null,则将
destructiveSortedIterator(): 在不使用额外的内存和不牺牲AppendOnlyMap的有效性的前提下,对AppendOnlyMap的data数组中的数据按照key进行排序,并返回迭代器- 将data数组中的元素向前整理
- 利用参数
keyComparator对整理后的data数组进行排序 - 返回一个迭代器,第一个为(null, nullValue)如果存在的话,后面返回按key排序的所有键值对
def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = { destroyed = true // Pack KV pairs into the front of the underlying array var keyIndex, newIndex = 0 while (keyIndex < capacity) { if (data(2 * keyIndex) != null) { data(2 * newIndex) = data(2 * keyIndex) data(2 * newIndex + 1) = data(2 * keyIndex + 1) newIndex += 1 } keyIndex += 1 } assert(curSize == newIndex + (if (haveNullValue) 1 else 0)) new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator) new Iterator[(K, V)] { var i = 0 var nullValueReady = haveNullValue def hasNext: Boolean = (i < newIndex || nullValueReady) def next(): (K, V) = { if (nullValueReady) { nullValueReady = false (null.asInstanceOf[K], nullValue) } else { val item = (data(2 * i).asInstanceOf[K], data(2 * i + 1).asInstanceOf[V]) i += 1 item } } } }iterator()nextValue(): 第一个为(null, nullValue)如果存在的话,后面返回data数组中顺序的所有键值对(乱序),最后一个返回nullnext(): 封装了nextValue(),超过了最后一个会抛出异常
override def iterator: Iterator[(K, V)] = { assert(!destroyed, destructionMessage) new Iterator[(K, V)] { var pos = -1 /** Get the next value we should return from next(), or null if we're finished iterating */ def nextValue(): (K, V) = { if (pos == -1) { // Treat position -1 as looking at the null value if (haveNullValue) { return (null.asInstanceOf[K], nullValue) } pos += 1 } while (pos < capacity) { if (!data(2 * pos).eq(null)) { return (data(2 * pos).asInstanceOf[K], data(2 * pos + 1).asInstanceOf[V]) } pos += 1 } null } override def hasNext: Boolean = nextValue() != null override def next(): (K, V) = { val value = nextValue() if (value == null) { throw new NoSuchElementException("End of iterator") } pos += 1 value } } }
SizeTrackingAppendOnlyMap
继承自AppendOnlyMap混入了SizeTracker特质。SizeTracker特质提供了对自身大小估算功能。重写了AppendOnlyMap的update()和changeValue()方法,在调用AppendOnlyMap中对应方法后再调用SizeTracker的afterUpade()方法。重写了growTable()方法,在调用AppendOnlyMap中对应方法后再调用SizeTracker的resetSample()方法以便于对AppendOnlyMap的大小估算更加准确
PartitionedAppendOnlyMap
继承自SizeTrackingAppendOnlyMap混入了WritablePartitionedPairCollection特质,即支持了key为(patition id, 键值)这种形式且多了WritablePartitionedPairCollection特质中的一些特性。
在partitionedDestructiveSortedIterator()方法中,使用了WritablePartitionedPairCollection伴生对象中定义的静态方法partitionedDestructiveSortedIterator(),对keyComparator进行包装,对key的partition id进行升序排序的比较器,在partition id相等时根据key的键值进行比较。
private[spark] class PartitionedAppendOnlyMap[K, V]
extends SizeTrackingAppendOnlyMap[(Int, K), V] with WritablePartitionedPairCollection[K, V] {
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
destructiveSortedIterator(comparator)
}
def insert(partition: Int, key: K, value: V): Unit = {
update((partition, key), value)
}
}
PartitionedPairBuffer
实现了WritablePartitionedPairCollection特质,混入了SizeTracker特质。用于保存键值对元素的数组,只是普通的collection,起到缓冲的作用,有以下成员属性
initialCapacity: 初始数组大小,默认64capacitycurSizedata:Array[AnyRef](2 * initialCapacity),因为key和value各占一个数组位置
有以下成员方法
insert(): 所有键值对都是按先后顺序插入data数组,插入后调用SizeTracker的afterUpdate()。如果大小不够则调用growArray()进行扩容growArray(): 新建数组,两倍扩容,扩容后调用SizeTracker的resetSamples()以便于对PartitionedAppendOnlyMap的大小估算更加准确partitionedDestructiveSortedIterator(): 返回排序(parititon id升序)后的data数组的迭代器
总结
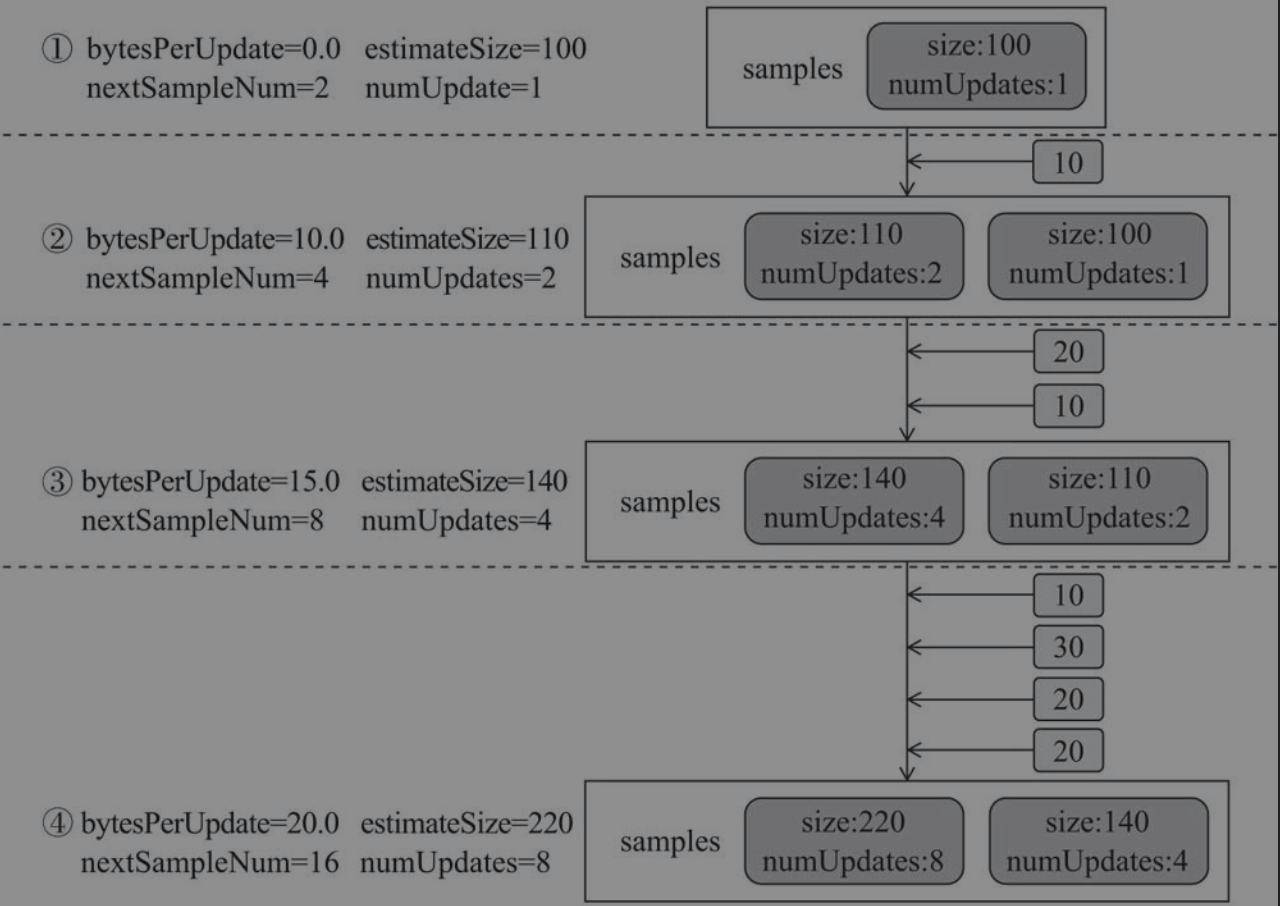
如图所示,SizeTracker的工作原理为当更新次数到一定限度时才会触发采样,并且这个阈值增加SAMPLE_GROWTH_RATE倍。在任意时刻都可以通过记录的平均更新大小(上次采样时计算)和更新次数对当前大小进行常数时间的估算。如图所示,SAMPLE_GROWTH_RATE取2,每次添加小方块数值的元素
REFERENCE
- Spark内核设计的艺术:架构设计与实现
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/28/calculation-dataStructure/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)