SQL语句经由ANTLR4解析树转换为未解析的逻辑算子树,逻辑计划本质上是一种中间过程表示,与Spark平台无关,后续阶段会进一步解析占位符并映射为可执行的物理计划
ConstraintHelper
特质ConstraintHelper是用于推断约束规则的,约束规则本质上属于数据过滤条件的一种,同样是Expression类型。有以下方法
inferAdditionalConstraints(): 从给定的相等约束集合中推断出一组附加约束。例如a=5, a=b -> b=5constructIsNotNullConstraints(): 从非空表达式以及可能空的属性推断出一组isNotNull约束。例如a>5 -> isNotNull(a)
QueryPlanConstraints
特质QueryPlanConstraints继承了ConstraintHelper。有以下方法
validConstraints: 返回此结点的合法约束,由继承的子类实现constraints: 将validConstraints经由父类的inferAdditionalConstraints()和constructIsNotNullConstraints()方法进行约束推断后得到新的ExpressionSet约束if (conf.constraintPropagationEnabled) { ExpressionSet( validConstraints .union(inferAdditionalConstraints(validConstraints)) .union(constructIsNotNullConstraints(validConstraints, output)) .filter { c => c.references.nonEmpty && c.references.subsetOf(outputSet) && c.deterministic } ) } else { ExpressionSet(Set.empty) }
AnalysisHelper
AnalysisHelper定义与query analysis相关的方法,通过analyzed属性来标识该计划是否被分析,防止重复分析。有以下重要的方法
resolveOperatorsUp(): 将偏函数PartialFunction[LogicalPlan, LogicalPlan]规则递归应用于树并返回此结点的副本,当规则不适用或者子树已经标记为已分析,则保持不变。后序遍历,先对子结点应用规则再对当前结点应用规则resolveOperatorsDown(): 作用与resolveOperatorsUp()相同。先序遍历,先对当前结点应用规则再对子结点应用规则resolveOperators(): 实际上调用了resolveOperatorsDown()resolveExpressions(): 规则类型为PartialFunction[Expression, Expression],实际调用了resolveOperatorsUp()只对Expression类型的结点应用规则
QueryPlan
抽象计划类,其子类为逻辑计划和物理计划。QueryPlan的主要操作分为5个模块,分别是输入输出、 字符串、 规范化、表达式操作、基本属性,如下图所示
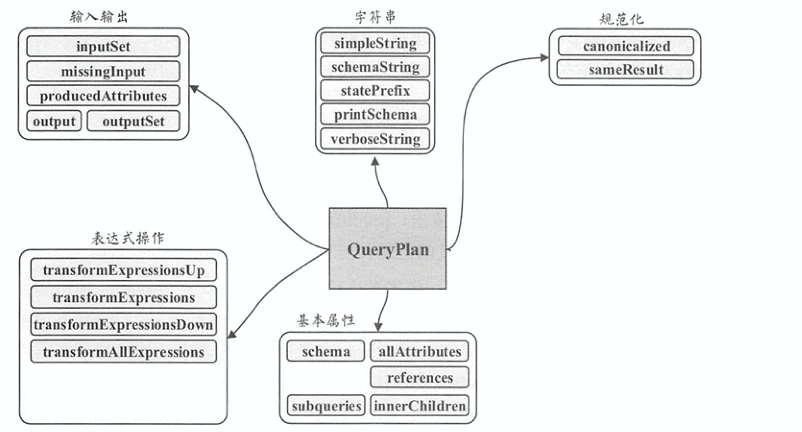
基本属性
schema: 当前结点的输出StructType类型,将output()的结果封装成StructTypeallAttributes: 结点所涉及的所有属性列表AttributeSeq,返回所有子结点的output()references: 结点表达式中所涉及的所有属性集合AttributeSetdef references: AttributeSet = AttributeSet(expressions.flatMap(_.references))subqueries(),innerChildren(): 结点包含的所有子查询PlanExpression
输入输出
output(): 抽象方法,返回Seq[Attribute]outputSet(): 把output()返回的结果封装成AttributeSetinputSet(): 获取当前结点的输入属性集AttributeSet,将所有子结点的输出属性封装成AttributeSet返回def inputSet: AttributeSet = AttributeSet(children.flatMap(_.asInstanceOf[QueryPlan[PlanType]].output))producedAttributes(): 该结点产生的属性集AttributeSet,当前返回空属性集由子类实现missingInput(): 该结点表达式中涉及的但是其子结点和当前结点输出中并不包含的属性def missingInput: AttributeSet = references -- inputSet -- producedAttributes
字符串: 用于打印树型结构信息的方法。其中
statePrefix()方法用来表示节点对应计划状态的前缀字符串规范化:
canonicalized()对当前结点及其子结点进行规范化,smaeResult()则比较两个QueryPlan规范后是否相等表达式操作
transformExpressionsDown(): 对该结点表达式遍历,并对每个结点调用了父类方法TreeNode.transformDown()并应用偏函数规则PartialFunction[Expression, Expression]transformExpressionsUp(): 对该结点表达式遍历,并对每个结点调用了父类方法TreeNode.transformUp()并应用偏函数规则PartialFunction[Expression, Expression]transformExpressions: 调用了transformExpressionsDown()transformAllExpressions(): 对此结点及其所有子结点上调用transformExpressions()expressions(): 返回此结点中的所有表达式
LogicalPlan
如下图所示,LogicalPlan继承了QueryPlan和QueryPlanConstraints和AnalysisHelper,作为数据结构记录了对应逻辑算子树节点的基本信息和基本操作。
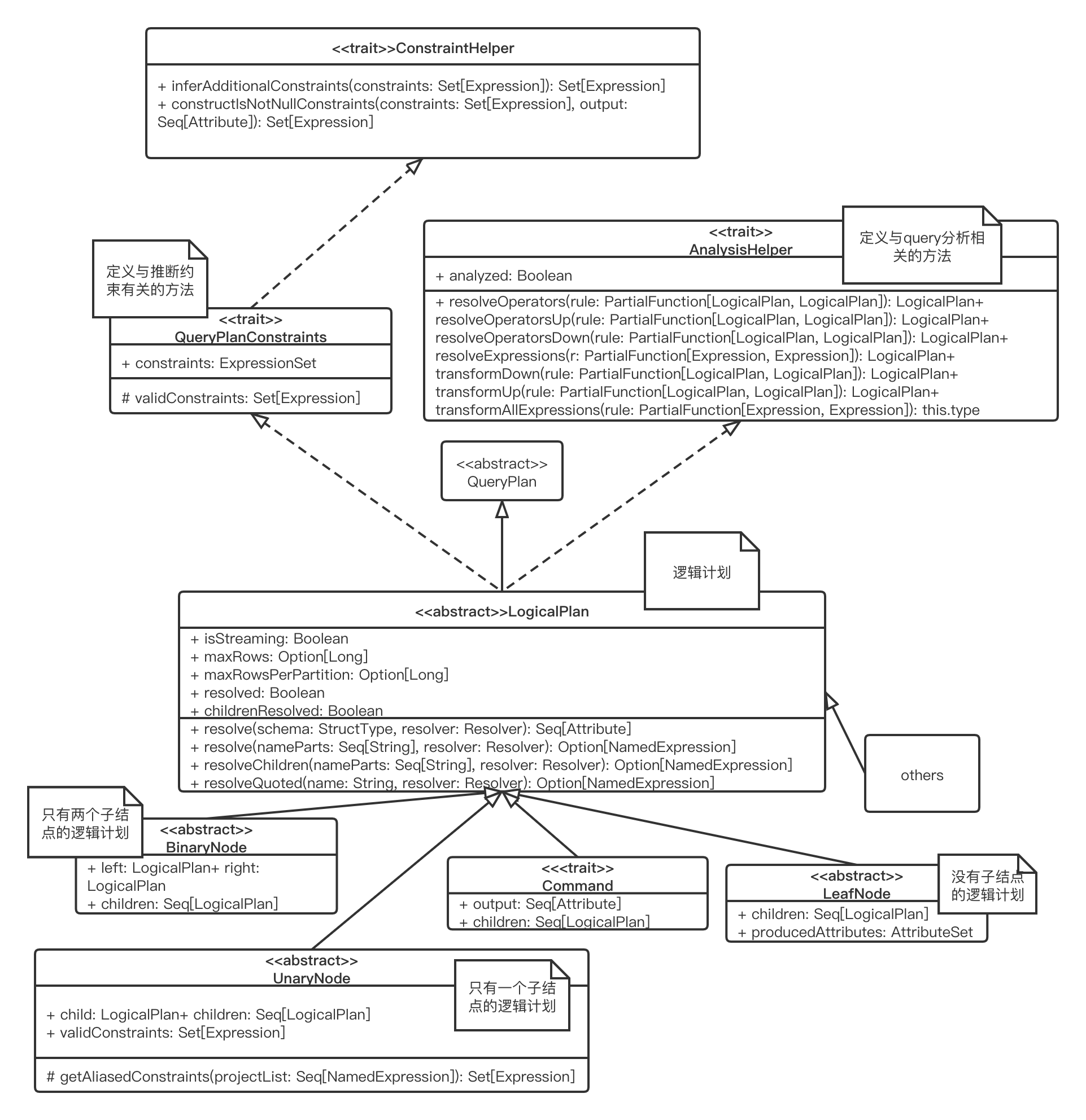
isStreaming: 此逻辑算子树是否含有流式数据源maxRows: 此逻辑计划最大可能计算的行数maxRowsPerPartition: 此逻辑计划的每个partition最大可能计算的行数resolved,childrenResolved: 当前表达式和子结点时候含有未解析的占位符
有以下与解析相关的方法,占位符字符串的格式为[scope].AttributeName.[nested].[fields]...
resolve(): 根据此逻辑计划的输出将给定的字符串或者StructType(占位符)解析为NamedExpression表达式resolveQuoted(): 给定属性名根据符号点进行分割,并根据此逻辑计划的输出解析成NamedExpressionresolveChildren: 根据此逻辑计划所有子节点的输入将给定的字符串解析为NamedExpression
LeafNode
没有子结点的逻辑计划,重载了children返回空序列。由下图所示的继承关系可以看出,叶子结点一般代表着数据源,如RDD, hive, 集合等
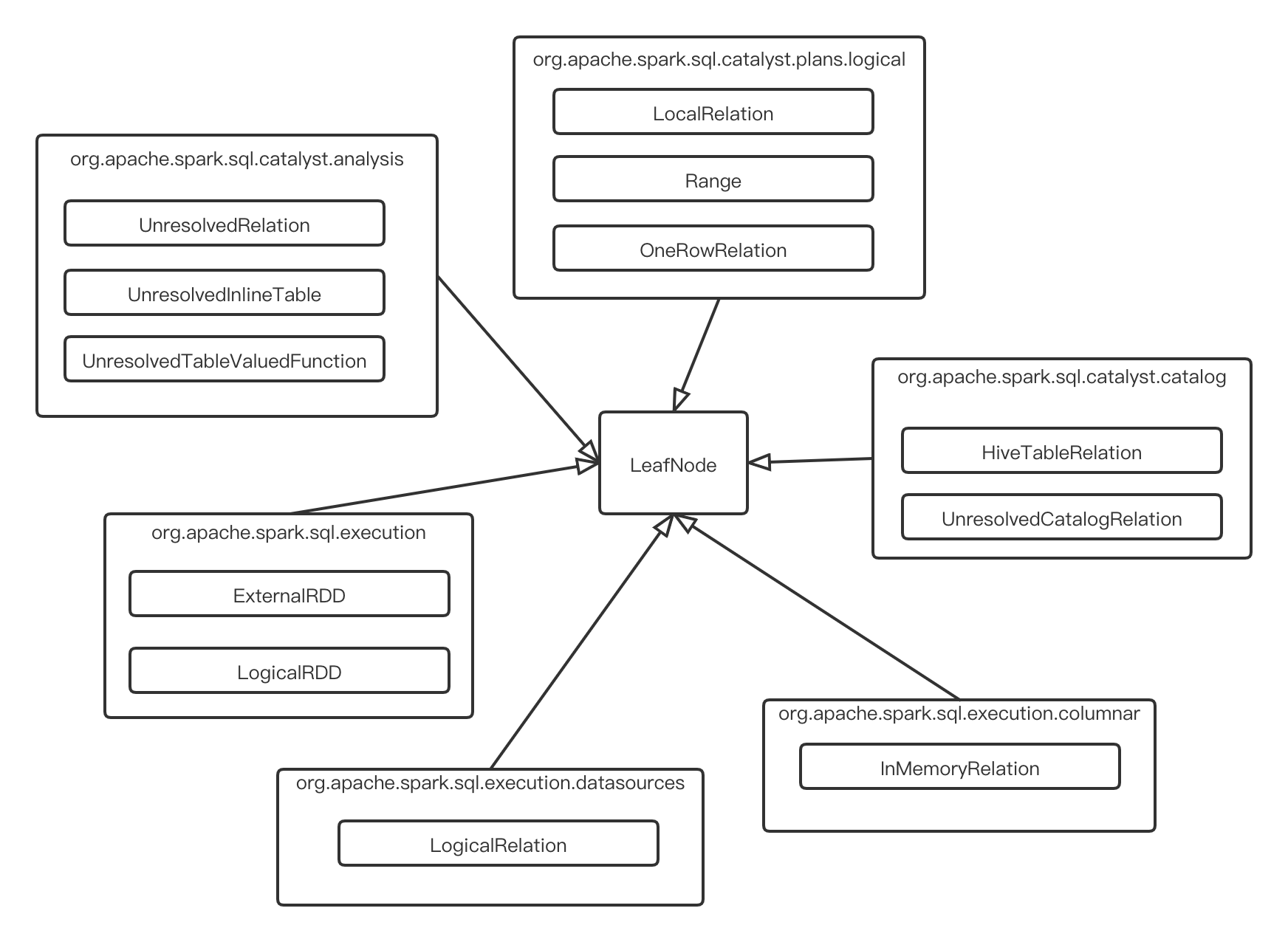
下面解释一些常用的逻辑计划
UnresolvedRelation: 未解析的表引用,Resolve阶段通过查找catalog解析UnresolvedInlineTable: 未解析的内联表"VALUES (1, 'a'), (2, 'b') AS t1(a, b)",将被解析成LocalRelationLogicalRelation: 持有BaseRelation的逻辑计划。BaseRelation是具有已知schema的关系契约(tuple集合)InMemoryRelation: 代表物理查询计划中的缓存DatasetLocalRelation: 代表从本地集合中扫描数据的逻辑计划OneRowRelation: 代表一行数据的关系,输出为空。在没有FROM子句的SELECT语句中使用
Command
代表着系统执行的非查询命令的逻辑结点,比如说DDL操作,相比于查询,执行的优先级更高。有以下继承关系,其方法run()实现了与命令相关的逻辑
特质
DataWritingCommand: 用于写出数据或者更新指标的命令样例类
CreateDataSourceTableAsSelectCommand: 用于使用查询结果创建数据源表的命令,如下所示CREATE TABLE [IF NOT EXISTS] [db_name.]table_name USING format OPTIONS ([option1_name "option1_value", option2_name "option2_value", ...]) AS SELECT ...样例类
CreateHiveTableAsSelectCommand: 建表并插入查询结果样例类
InsertIntoHadoopFsRelationCommand: 将数据写入HDFS特质
SaveAsHiveFile- 样例类
InsertIntoHiveDirCommand: 将查询结果写入到文件系统中的hive语句 - 样例类
InsertIntoHiveTable: 将数据写入hive表
- 样例类
特质
RunnableCommand: 直接运行的命令。有许多实现此特质的样例类
BinaryNode
有两个子结点的逻辑计划结点,有以下继承关系
- 样例类
CoGroup: full outer join - 样例类
Join - 样例类
OrderedJoin: 实现的output()方法返回左右子结点的输出合并 - 抽象类
SetOperation: 集合操作- 样例类
Except: 实现的output()方法只返回左子结点的输出,validConstraints()也只返回左子结点的约束 - 样例类
Intersect: 实现的output()方法只返回左子结点的输出,当左右子结点中有一个为可空时返回可空的,validConstraints()也返回左右子结点的约束合并
- 样例类
UnaryNode
只有一个子结点的逻辑计划结点,常用于对数据的逻辑转换操作,下面介绍一些常见的样例类
Project: 表示 SELECT 语句中选中列的那部分。包含了选中列的表达式NamedExpressioncase class Project(projectList: Seq[NamedExpression], child: LogicalPlan) extends OrderPreservingUnaryNodeFilter: 表示 WHERE 语句中的条件。包含了布尔表达式Expressioncase class Filter(condition: Expression, child: LogicalPlan) extends OrderPreservingUnaryNode with PredicateHelperSort: 表示 ORDER BY(全局排序)和SORT BY(分区排序)case class Sort(order: Seq[SortOrder], // 排序的字段或者表达式,还有排序方向 global: Boolean, // 否为全局的排序,还是分区的排序 child: LogicalPlan) extends UnaryNodeDistinct: 表示SELECT中带有DISTINCT关键字的列case class Distinct(child: LogicalPlan) extends UnaryNodeAggregate: 表示 GROUP BYcase class Aggregate( groupingExpressions: Seq[Expression], // GROUP BY 的字段 aggregateExpressions: Seq[NamedExpression], // SELECT 的字段 child: LogicalPlan) extends UnaryNode
其他子类
InsertIntoTable: 向表中插入数据,这个结点是未解析的,在分析阶段会被替换CreateTable: 创建一个表,可选插入数据,这个结点是未解析,在分析阶段会被替换View: 保存视图的元数据和输出,分析阶段结束后被删除Union: 组合多个逻辑计划,相当于UNION ALLAppendData: 在已存在的表中追加数据ObjectProducer: 用于产生只包含object列的行数据
Unresolved逻辑计划树生成
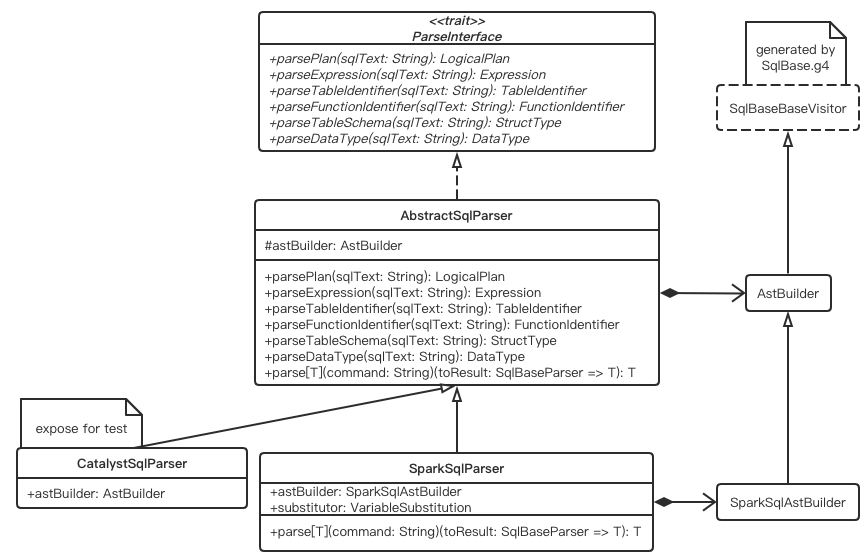
AstBuilder&AbstractSqlParser
SqlBaseBaseVistor为ANTLR生成的类用于遍历ANTLR4解析树,AstBuilder继承了SqlBaseBaseVistor并实现了其中的一部分访问者方法,将ANTLR4解析树结点转换为逻辑计划。以visitSingleStatement()方法为例
withOrigin()方法根据ANTLR4解析树结点上下文ctx注册当前sql语句的行和开始字符处- 方法内部先调用了
visit()方法,如下所示,触发visitor遍历模式,根据ANTLR4解析树结点的不同调用不同visitXXX()方法 - 子结点都转换完,才会生成当前结点的逻辑计划
// AstBuilder
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
// 这里是递归
// ctx.statement里调用了最终调用了ParserRuleContext.getChild(type, 0)返回第一个子结点
visit(ctx.statement).asInstanceOf[LogicalPlan]
}
// AbstractParseTreeVisitor
public T visit(ParseTree tree) {
return tree.accept(this);
}
// XXXXContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if (visitor instanceof SqlBaseVisitor) return ((SqlBaseVisitor<? extends T>)visitor).visitXXXX(this);
else return visitor.visitChildren(this);
}
特质ParserInterface定义了将ANTLR4解析树结点转换为逻辑计划的抽象方法,如下所示
parsePlan(): 将字符串类型的SQL语句转化为逻辑计划parseExpression(): 将字符串类型的SQL语句转化为表达式parseTableIdentifier(): 将字符串类型的SQL语句转化为数据表标识parseFunctionIdentifier(): 将字符串类型的SQL语句转化为数据库定义函数的标识parseTableSchema(): 将字符串类型的SQL语句转化为表的schema信息,即结构体类型parseDataType(): : 将字符串类型的SQL语句转化为类型信息
AbstractSqlParser继承了ParserInterface特质并实现了这些抽象方法,下面以parsePlan()为例
调用了
parse()方法构造SqlBaseParser对象去驱动访问者模式调用了
AstBuilder.visitSingleStatement()方法去解析逻辑计划
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
SparkSqlAstBuilder&SparkSqlParser
SparkSqlAstBuilder继承了AstBuilder,并在其基础上定义了一些 DDL 语句的访问操作,实现了SqlBaseBaseVistor其中的剩余的访问者方法,由其实例在SparkSqlParser调用
SparkSqlParser继承了AbstractSqlParser,并且重写了parse()方法,对字符串增加了对${var}$这些字符串的替换
class SparkSqlParser(conf: SQLConf) extends AbstractSqlParser(conf) {
val astBuilder = new SparkSqlAstBuilder(conf)
private val substitutor = new VariableSubstitution(conf)
protected override def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
super.parse(substitutor.substitute(command))(toResult)
}
}
示例
如图所示,下面是SQL语句SELECT NAME FROM STUDENT WHERE AGE > 18 ORDER BY ID DESC的ANTLR4解析树
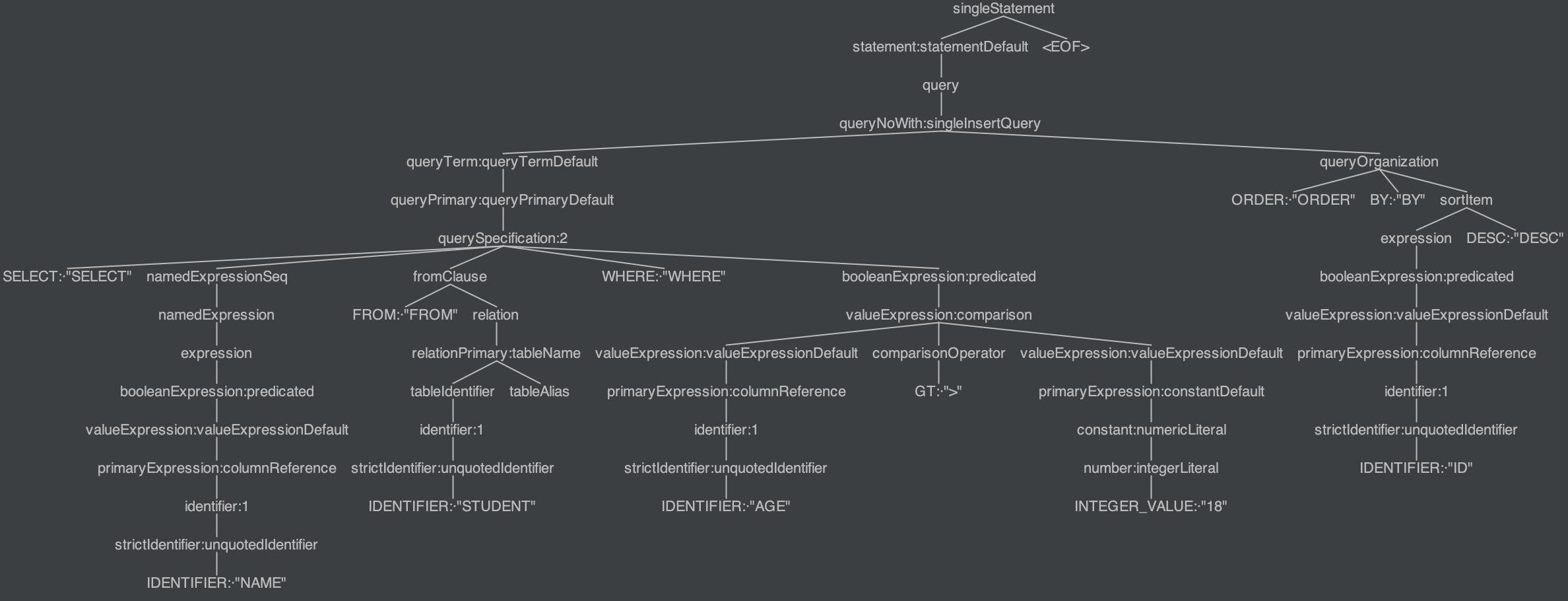
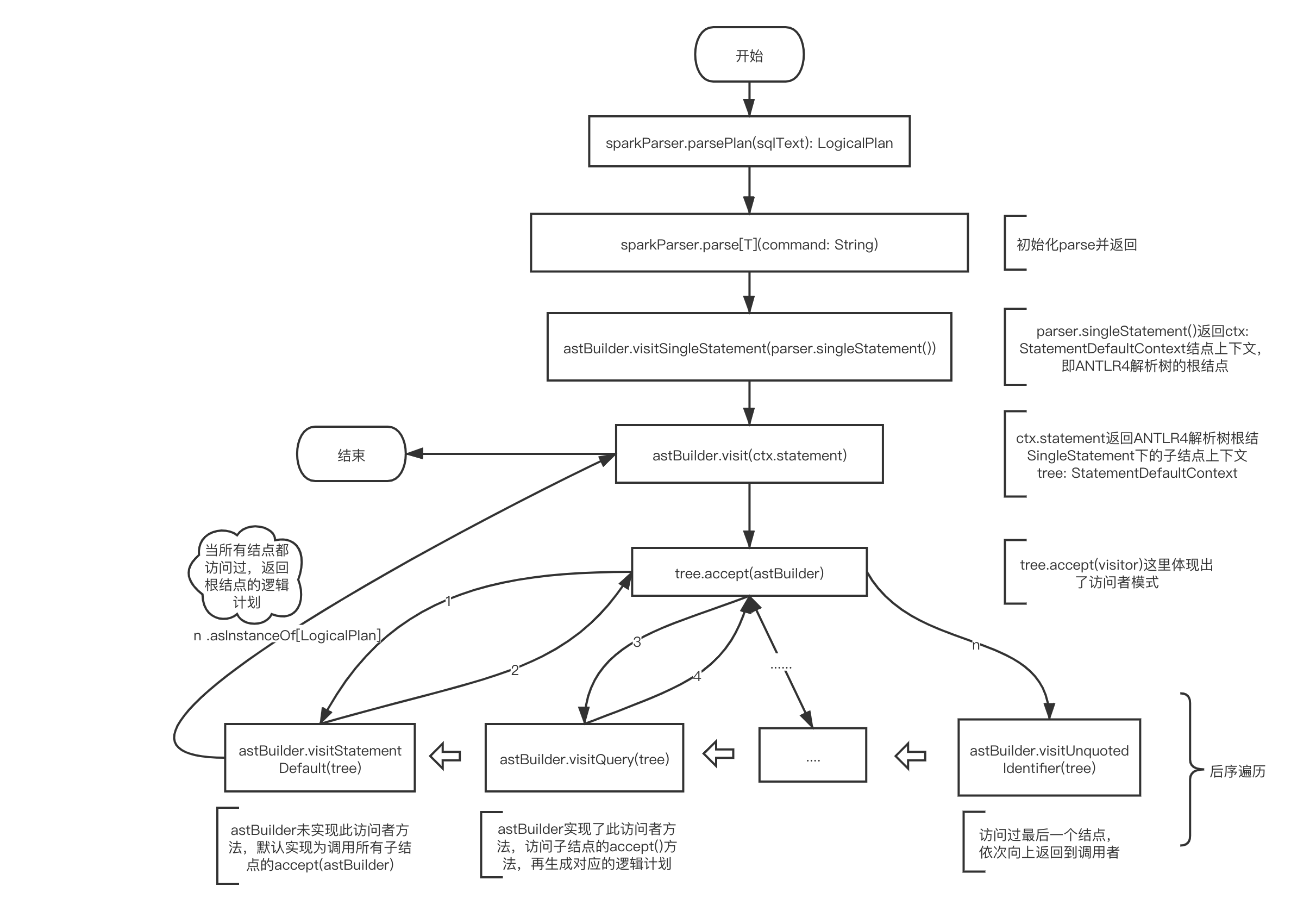
由以下流程图所示,展示了此SQL语句的ANTLR4解析树结点转换为unresolved逻辑计划的调用逻辑,有以下符号标记
astBuilder表示SparkSqlAstBuilder实例,继承自ANTLR产生的SqlBaseVisitor访问者类sparkParser表示SparkSqlParser实例,内部使用了astBuilderparser表示SqlBaseParser实例tree表示ParseTree实例,其子类表示各结点上下文如StatementDefaultContext
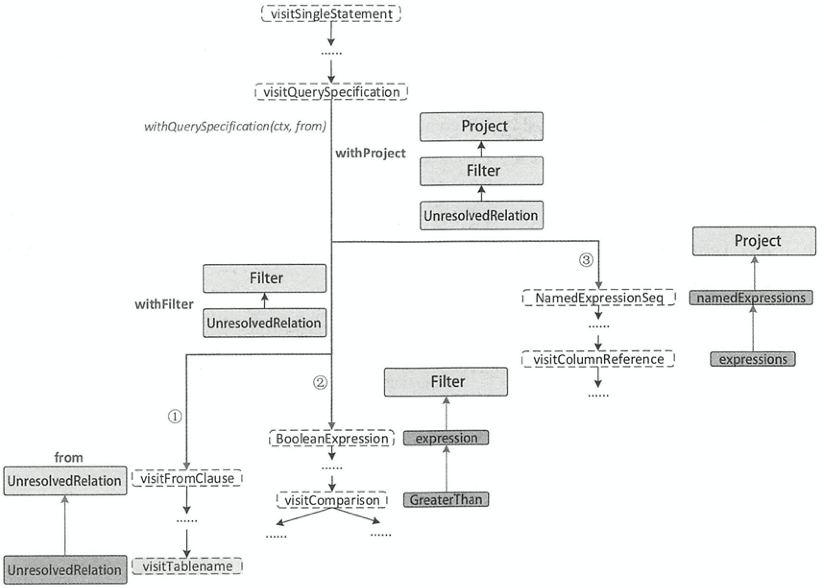
最终,ANTLR4解析树被转化为如下所示的Unsolved逻辑计划树
== Parsed Logical Plan ==
'Sort ['ID DESC NULLS LAST], true
+- 'Project ['NAME]
+- 'Filter ('AGE > 18)
+- 'UnresolvedRelation `STUDENT`
可以看出逻辑计划树和ANTLR4解析树是相对应的,Sort作为根结点,子结点的解析逻辑如下图所示,结合具体源码就可以看出解析逻辑
REFERENCE
- Spark SQL内核剖析
- Spark Sql LogicalPlan 介绍——zhmin
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/10/21/spark-sql-logic-plan/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)