Flink 中高效而丰富的算子状态管理机制
状态
Flink 的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
Keyed/Operator/Broadcast State
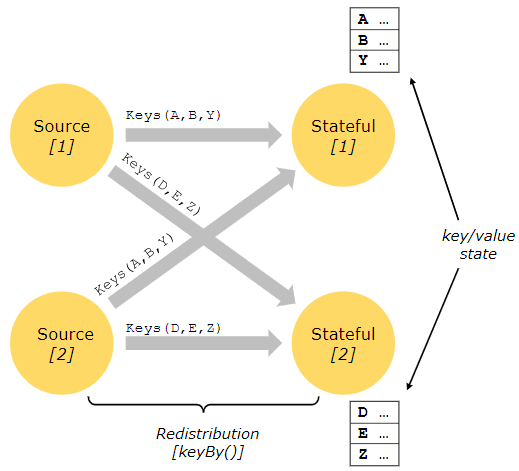
Keyed State 以键值对方式存储,并且与数据流一样严格分区。如图所示,只有在 keyBy 函数之后,才可以在对应 keyed stream 的子任务中访问到 Keyed State。
Operator State 绑定在子任务上,流入相同子任务的数据可以访问和共享Operator State。
Broadcast State 由 Broadcast Stream 生成,每个子任务保存全量的状态,但是 Broadcast state 的更新不能依赖于流中元素到达的顺序
Raw and Managed State
Managed State 由 Flink 进行维护管理,如ValueState、ListState、MapState 等。Flink runtime 对 state 进行编码,然后将其写入检查点。
Raw State 由算子维护,Flink 本身并不知道这些状态。快照时,仅将字节序列写入检查点。Raw State 的数据结构对 Flink 不透明,只能观察到原始的字节数组。一般不建议使用。
存储
MemoryStateBackend
MemoryStateBackend 将状态数据存储在本地内存中,一般用来进行本地调试用
FsStateBackend
FsStateBackend 会把状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的 HDFS 中,少量的元数据信息存储到 JobManager 的内存中。适用于大作业、状态较大、全局高可用的那些任务。
RocksDBStateBackend
RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 运行节点的数据目录下。CheckPoint 时,将状态快照写入到配置 HDFS 中,是唯一支持增量快照的状态后端,适用于超大状态的场景
访问
所有对 subTask 状态的并发操作都通过队列进行排队(Mailbox),单线程(Mailbox 线程)依次处理达到线程安全。使用 StateDescriptor 从 StateBackend 中获取 State 实例
public class Main {
/**
* (1,4)
* (1,6)
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(Tuple2.of(1, 3), Tuple2.of(1, 5), Tuple2.of(1, 7), Tuple2.of(1, 5), Tuple2.of(1, 2))
.keyBy(x->x.f0)
.flatMap(new CountWindowAverage())
.print();
env.execute("test");
}
private static class CountWindowAverage extends RichFlatMapFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> {
private ValueState<Tuple2<Integer, Integer>> state = null;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Tuple2<Integer, Integer>> descriptor =
new ValueStateDescriptor<>("average", TypeInformation.of(new TypeHint<Tuple2<Integer, Integer>>() {
}));
// 设置ttl
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10))
// 何时更新过期状态
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 是否可以访问过期数据
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
descriptor.enableTimeToLive(ttlConfig);
state = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Tuple2<Integer, Integer> value, Collector<Tuple2<Integer, Integer>> out) throws Exception {
Tuple2<Integer, Integer> curSum = Optional
.ofNullable(state.value())
.orElse(Tuple2.of(0, 0));
curSum.f0 += 1;
curSum.f1 += value.f1;
state.update(curSum);
if (curSum.f0 >= 2) {
out.collect(Tuple2.of(value.f0, curSum.f1 / curSum.f0));
state.clear();
}
}
}
}
REFERENCE
- CARBONE P, KATSIFODIMOS A, EWEN S, 等. Apache flink: Stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, IEEE Computer Society, 2015, 36(4).
- flink官方文档
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2024/01/13/2-flink-state/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)