Flink JM 将解析后的 StreamGraph 交由 TM 调度执行。从数据源读取数据开始,上游的数据处理完毕后 push 到下游继续处理,直到数据输出到外部存储中。
数据流
算子
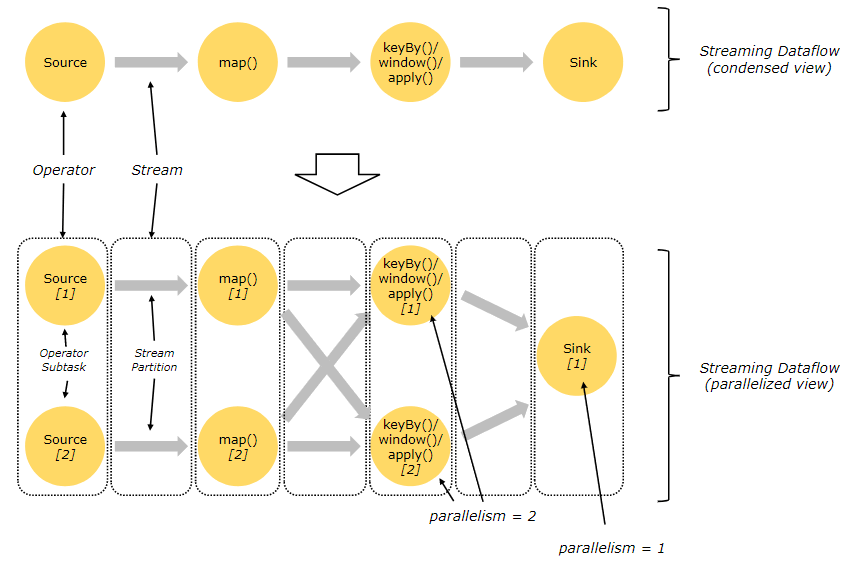
数据流由有状态的算子和连接算子的 edge 组成。如图所示,数据流以并行化的方式执行,所以算子会根据并行度被并行化为多个 sub task,而 edge 被拆分为一个或多个流分区,流向一个 sub task。
转化流程
SQL
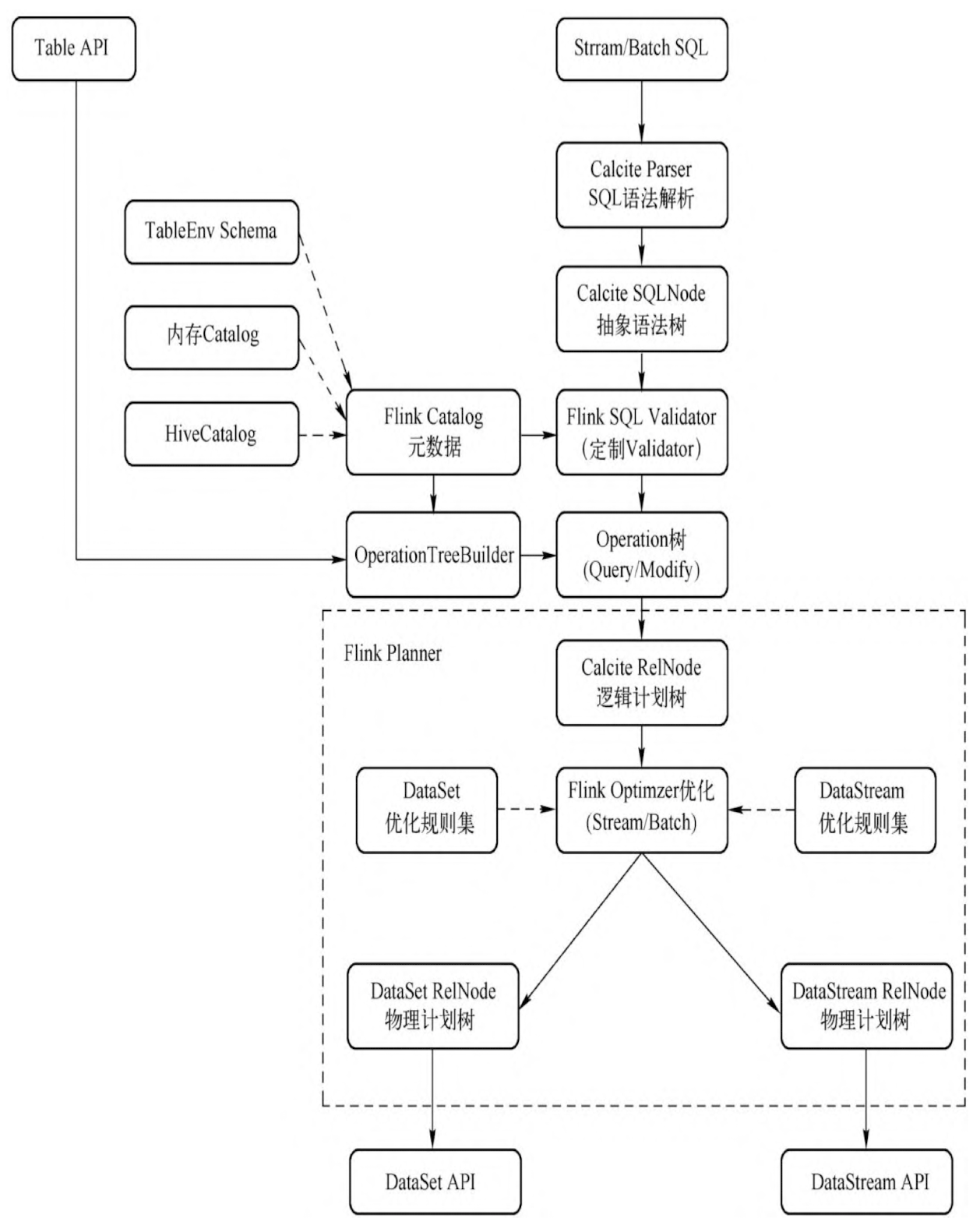
与 Spark Sql 非常类似,Flink Sql 使用 Calcite 进行语法生成抽象语法树,结合元数据解析为 Operation 树,并过优化规则优化为物理计划树,最后转化为 DataSet/DataStream 算子。
以下以祖传的 wordCount 为例
CREATE TABLE source_table (
num INT
) WITH (
'connector'='datagen',
'fields.num.min'='0',
'fields.num.max'='10',
'rows-per-second'='1'
);
SELECT num, count(*) AS cnt
FROM source_table
GROUP BY num;
任务以回撤流输出
+----+-------------+----------------------+
| op | num | cnt |
+----+-------------+----------------------+
| +I | 7 | 1 |
| +I | 5 | 1 |
| +I | 4 | 1 |
| +I | 10 | 1 |
| -U | 4 | 1 |
| +U | 4 | 2 |
| -U | 10 | 1 |
explain 后的结果为
== Abstract Syntax Tree ==
LogicalAggregate(group=[{0}], cnt=[COUNT()])
+- LogicalTableScan(table=[[default_catalog, default_database, source_table]])
== Optimized Physical Plan ==
GroupAggregate(groupBy=[num], select=[num, COUNT(*) AS cnt])
+- Exchange(distribution=[hash[num]])
+- TableSourceScan(table=[[default_catalog, default_database, source_table]], fields=[num])
== Optimized Execution Plan ==
GroupAggregate(groupBy=[num], select=[num, COUNT(*) AS cnt])
+- Exchange(distribution=[hash[num]])
+- TableSourceScan(table=[[default_catalog, default_database, source_table]], fields=[num])
转化后的 JobGraph 如下所示

DataStream
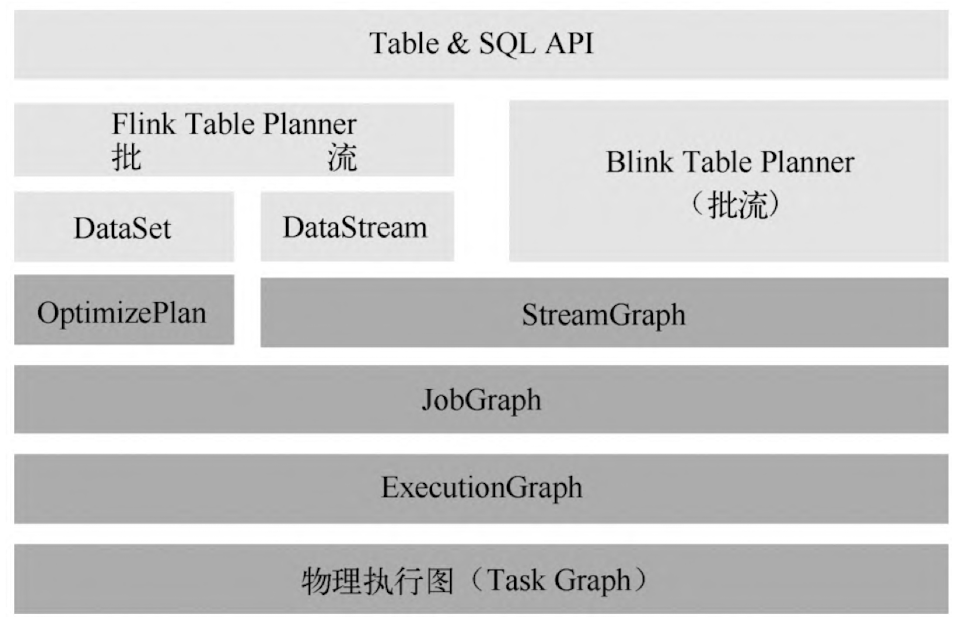
在 per-job 和 session 模式下,client 负责转化 StreamGraph 和 JobGraph
DataStream 算子会先转化为 StreamGraph,表达计算过程的逻辑
- 转化为 JobGraph,在 web ui 上看到的就是这个。在 StreamGraph 基础上进行 OperatorChain 优化
- 转化为 ExecutionGraph,包含了作业中所有并行执行的 Task 信息、Task 之间的关联关系、数据流转关系
以祖传的 wordCount 代码来看 StreamGraph -> JobGraph -> ExecutionGraph 的流程
public class WindowWordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1)
.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) {
for (String word : sentence.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
StreamGraph
每个 DataStream 算子都会先转化为一个 Transformation,然后再转化为 StreamNode 和 StreamEdge
Transformation 如下所示
[LegacySourceTransformation{id=1, name='Socket Stream', outputType=String, parallelism=1}]
[OneInputTransformation{id=2, name='Flat Map', outputType=Java Tuple2<String, Integer>, parallelism=12}]
[PartitionTransformation{id=3, name='Partition', outputType=Java Tuple2<String, Integer>, parallelism=12}]
[OneInputTransformation{id=4, name='TumblingProcessingTimeWindows', outputType=Java Tuple2<String, Integer>, parallelism=12}]
[LegacySinkTransformation{id=5, name='Print to Std. Out', outputType=Java Tuple2<String, Integer>, parallelism=12}]
对应的 StreamGraph 如下所示

- 实体 StreamNode 表示执行计算的算子,由 Transformation 转化而成,可以有多个输入和输出
- 虚拟 StreamNode 表示 StreamEdge 的属性,由 Transformation 转化而成,会附着到 StreamEdge 中。如 PartitionTransformation
- StreamEdge 用来连接两个 StreamNode,包含了旁路输出 tag、partitioner 等的信息
JobGraph
如下所示,web ui 中显示的 DAG 图就是 JobGraph

- JobVertex 由 OperatorChain 融合优化后的多个 StreamNode 组合而成,输入是 JobEdge,输出是 IntermediateDataSet
- JobEdge 是连接 IntermediateDatSet 和 JobVertex 的边,其数据分发模式会直接影响执行时 Task 之间的数据连接关系,是点对点连接还是全连接
- IntermediateDataSet 表示 JobVertex 中包含的算子会产生的数据集。其个数与 JobVertext 对应的 StreamNode 的出边数量相同,可以是一个或者多个
ExecutionGraph
- ExecutionJobVertex 和 JobVertex 一一对应。包含一组 ExecutionVertex
- ExecutionVertex 表示 ExecutionJobVertex 的并发执行实例,与 JobVertex 的并发数一致
- Execution 表示 ExecutionVertex 一次尝试。在发生故障或者数据需要重算的情况下,ExecutionVertex 可能会有多个 ExecutionAttemptID 来标识 Execution
- ExecutionEdge 表示 ExecutionVertex 的输入,连接到上游产生的 IntermediateResultPartition
- ExecutionVertex 表示 ExecutionJobVertex 的并发执行实例,与 JobVertex 的并发数一致
- IntermediateResult 表示 ExecutionJobVertex 的逻辑输出结果,和 IntermediateDataSet 一一对应。包含一组 IntermediateResultPartition
- IntermediateResultPartition 表示 ExecutionVertex 的逻辑输出结果
资源和资源组
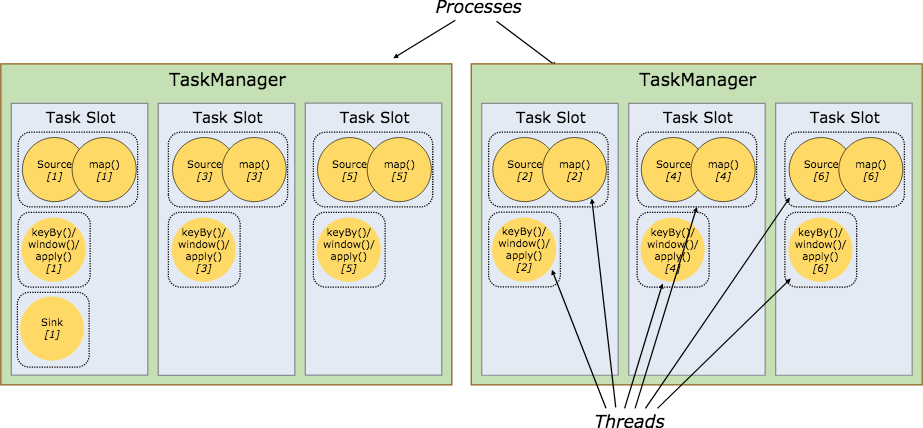
在 Flink 集群中,一个 TaskManger 就是一个 JVM 进程,并且会用独立的线程来执行 Task。如下图所示,每个 TaskManger 中含有固定的 Slot,作为为运行Task的容器,起到了内存隔离的作用,并且共享 TCP 连接,减少网络传输。 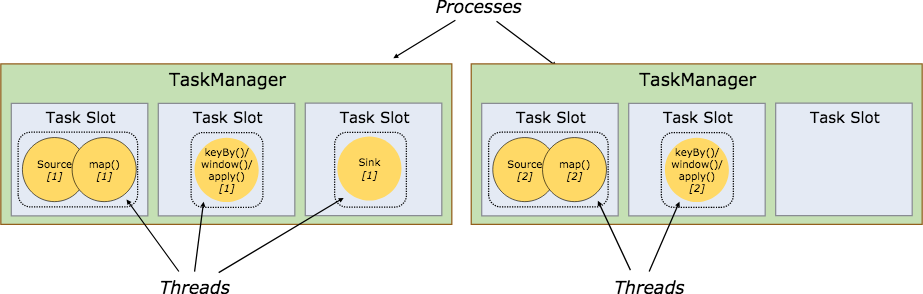
OperatorChain
在 StreamGraph -> JobGraph 阶段,类似 Spark 中窄依赖,让没有 shuffle 的算子在同一个线程中执行。
- 减少线程间上下文的切换
- 减少序列化的资源消耗
- 减少网络传输的资源消耗
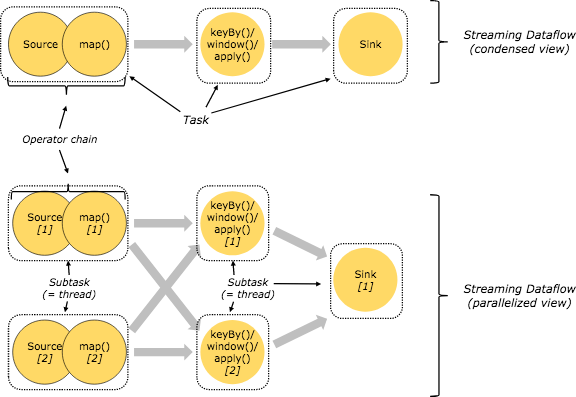
符合以下条件的算子将合并为算子链
下游算子的输入 StreamEdge 只能有一个
- 上下游算子实例处于同一个 SlotSharingGroup 中,默认都是 default
- 下游节点的连接策略为 ALWAYS (表示可以与上下游链接,map、flatmap、filter 等默认是 ALWAYS)
- 上游节点的连接策略为 ALWAYS 或 HEAD(表示只能与下游链接,Source 默认是 HEAD)
- 上下游算子的并行度相同
- StreamEdge 的分区类型为 ForwardPartitioner
- 没有禁用算子链
SlotSharing
在调度 ExecutionGraph 阶段,将不能形成算子链的两个 Execution 放在一个 Slot 中执行。一些简单的 map 和 filter 算子所需要的资源不多,但是有些算子比如window、group by 则需要更多的计算资源才能满足计算所需。资源需求大的算子可以共用其他的 Slot,提高整个集群的资源利用率。在一个 Slot 中执行多个线程,类似 Spark vcore 功能。比如下图中的 flatmap 和 key&sink 放在一个 slot 里执行以达到资源共享的目的。
数据交换
Push 模式
Flink 的 Stream 计算模型采用的是 PUSH(Pipeline) 模式,上游主动向下游推送数据,下游收到数据触发计算,没有数据则进入等待状态
| 对比点 | Pull | Push |
|---|---|---|
| 延迟 | 延迟高(需要等待上游所有计算完毕) | 延迟低(上游边计算边向下游输出) |
| 下游状态 | 有状态,需要知道拉取时机和拉取点 | 无状态 |
| 上游状态 | 无状态 | 有状态,需要知道下游的推送点 |
| 连接状态 | 短链接 | 长链接 |
传递方式
数据要交给下一个算子或者 Task 进行计算, 有以下三种情形
- OperatorChain内部的数据传递,发生在本地线程内
- 同一个 TM 的不同 Task 之间传递数据,发生在同一个 JVM的不同线程之间
- 不同 TM 的 Task 之间传递数据,即跨 JVM 的数据传递,需要使用跨网络的通信
反压
REFERENCE
- CARBONE P, KATSIFODIMOS A, EWEN S, 等. Apache flink: Stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, IEEE Computer Society, 2015, 36(4).
- flink官方文档](https://ci.apache.org/projects/flink/flink-docs-release-1.10/)
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2024/01/13/3-flink-stream/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)