Flink 中精准一次的容错机制
一致性
一致性语义
- 最多一次(At-most-Once): 用户的数据只会被处理一次,不管成功还是失败,不会重试也不会重发。
- 至少一次(At-least-Once): 这种语义下,系统会保证数据或事件至少被处理一次。如果中间发生错误或者丢失,那么会从源头重新发送一条然后进入处理系统,所以同一个事件或者消息会被处理多次。
- 精确一次(Exactly-Once): 每一条数据只会被精确地处理一次,不会多也不会少。
2PC
通过 2PC 保证 source 和 sink 的精确一次,需要实现以下四个方法
beginTransaction(): 开始一个事务,返回事务信息的句柄preCommit(): 刷写数据,但是不提交,数据不可见commit(): 原子性地提交 preCommit 阶段刷写的数据,数据可见abort(): 清理 preCommit 刷写的数据
检查点开始时,触发 2PC 算子的 preCommit 操作,所有算子都完成 snapshot 时,触发 2PC 算子的 commit 操作。
轻量级异步分布式状态快照
Flink 通过严格只处理一次的一致性保证和检查点与分区重新执行来保证执行的可靠性。因为数据源是持久并可以重新获得的,如文件,持久的消息队列等,非持久数据源通过日志实现持久化。
如果发生程序故障,Flink 将停止分布式流数据流。然后,系统重新启动算子,并将他们重置为最近检查点的状态。输入流也用状态快照重置,并保证作为重新启动的并行数据流中的的任何 record 都在所恢复检查点之后。
基于以下假设,Flink 使用轻量级异步分布式状态快照
- 作业异常和失败极少发生,因为一旦发生异常,作业回滚到上 一个状态的成本很高
- 为了低延迟,快照需要很快就能完成
- Task 与 TaskManager 之间的关系是静态的,即分配完成之后, 在作业运行过程中不会改变(至少是一个快照周期内),除非手动改变并行度
CheckPoint
容错机制会绘制分布式数据流和算子的状态的一致快照,包含所有算子的状态和一定时间间隔内的输入数据流。
Barrier
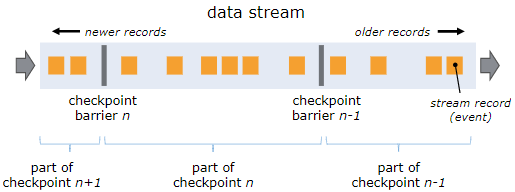
checkpoint barrier 插入到数据流中,并和 record 一起流动。barrier 严格地按照直线流动并且不会超过 record。如图所示,barrier 带有一个 ID,并且将数据流中的 record 分为当前快照的 recordSet(右部)和下一个快照的 recordSet(左部)。barrier 不会中断数据流的流动,因此非常轻量级。来自不同快照的多个 barrier 可以同时出现在数据流中,这意味着可以同时进行多个快照。
算子接收到 barrier 时进入对齐阶段,确保接收到每个输入流中的 barrier,才会向输出流中传递 barrier。当 sink接收到 barrier n 时,它会向检查点协调器确认快照 n。当所有的 sink 都接收到 barrier 时,快照 n 完成。

如图所示,当算子接收多个输入流时,需要对 barrier 进行对齐:
- 当算子接收到某个输入流的 barrier n 后,它就不能继续处理该数据流的后续 record,直到算子接收到其余输入流的 barrier n。否则快照 n 和快照 n+1 的 record 将会混淆。
- 算子将不能处理的 record 放到 input buffer 中
- 当算子接收到最后一个输入流中的 barrier n 时,算子会向后传递所有等待的输出 record 以及 barrier n
- 经过以上步骤,算子恢复所有输入流数据的处理,优先处理 input buffer 中的 record
Barrier 对齐
不跳过对齐是 Exatly once 语义,但是对齐阶段可能会导致流处理的延迟。通常,这种额外的延迟大约是几毫秒,但是出现过异常的延迟显着增加的情况。
跳过对齐是 At least once 语义。当算子接收到一个 barrier,就立即进行状态快照。算子在检查点 n 创建之前,会继续处理属于检查点 n+1 的 record,这就导致检查点 n 与检查点 n+1 之间存在数据重叠。
State
所有类型的状态都是快照的一部分。
- 用户定义状态:由 transformation 函数直接创建或者修改的状态
- 系统状态:这种状态指的是数据缓存,是算子计算的一部分。例如窗口,其中缓存一定数量的 record,直到计算完成为止。
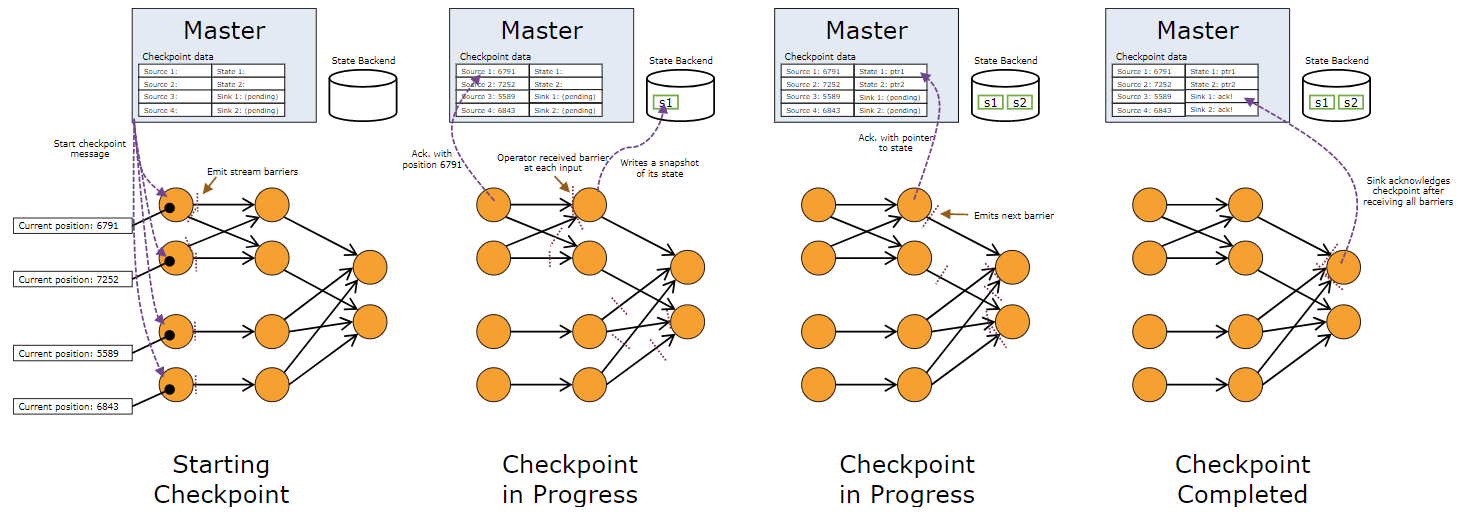
如图所示,算子在从输入流接收到所有 barrier 之后,向输出流发出 barrier 之前,对其状态进行快照。在这个时间点,barrier 之前的 record 进行的所有状态更新已经完成,并且没有依赖于 barrier 之后的 record。由于快照状态占用空间可能很大,因此将其存储在可配置的后端存储系统中。默认情况下,使用 JobManager 的内存,但对于生产用途,应配置分布式可靠存储(例如HDFS)。状态存储后,算子确认检查点,将 barrier 发送到输出流,然后继续处理数据。
快照包含:
- 对于并行输入数据源:快照创建时数据流中的位置偏移
- 对于算子:存储在快照中的状态的指针
恢复策略
一旦遇到故障,Flink 选择最近一个完成的检查点 k,重置所有算子的状态到检查点 k,数据源被置为从检查点 k 位置读取。如果是增量快照,算子需要从最新的全量快照恢复,然后对此状态进行一系列增量更新。
Flink 支持了不同级别的故障恢复策略,jobmanager.execution.failover-strategy 的可配置项有两种:full 和 region。
- Full:Task 发生故障,那么该 Job 的所有 Task 都会发生重启。恢复成本高,但是恢复作业一致性的最安全策略
- Region:当某一个 Task 发生故障时,只需重启最小 Region
重启策略
如果用户配置了checkpoint,但没有设置重启策略,那么会按照固定延迟重启策略模式进行重启;如果用户没有配置checkpoint,那么默认不会重启
无重启策略
restart-strategy: none
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
固定延迟重启策略
restart-strategy: fixed-delay
# 每个task重试
restart-strategy.fixed-delay.attempts: 3
# 每次重试间隔
restart-strategy.fixed-delay.delay: 5 s
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(5, TimeUnit.SECONDS) // 时间间隔
));
失败率重启策略
restart-strategy: failure-rate
# 时间范围内最大失败次数
restart-strategy.failure-rate.max-failures-per-interval: 3
# 时间范围
restart-strategy.failure-rate.failure-rate-interval: 5 min
# 重试间隔时间
restart-strategy.failure-rate.delay: 5 s
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔
Time.of(5, TimeUnit.SECONDS) // 每次任务失败时间间隔
));
REFERENCE
- CARBONE P, KATSIFODIMOS A, EWEN S, 等. Apache flink: Stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, IEEE Computer Society, 2015, 36(4).
- flink官方文档
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2024/01/13/5-flink-recover/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)