Iceberg 是数据湖三剑客之一,以下简要分析 Iceberg 的元数据、存储结构及读写流程
背景
与 hudi 类似,面向海量数据分析场景的高效存储格式。支持 Full schema evolution,time travel 和事务性管理。以下简要分析 Iceberg 的元数据、存储结构和读写流程
元数据
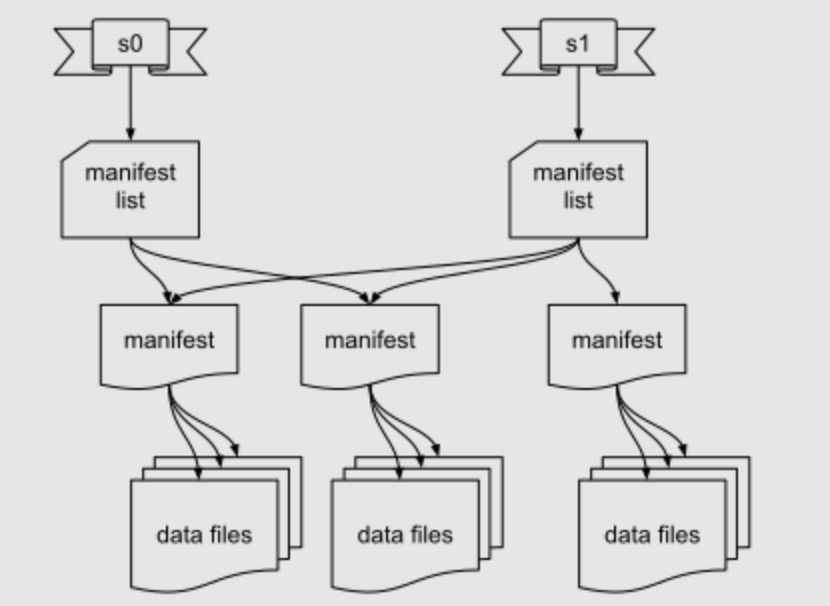
- metadata: 提交级别的元数据,包含 snapshots, schema, statics
- snapshot: 某个时刻的 snapshot,每次提交都会产生新的 snapshot,包含一组 manifest
- Sequence Nubmer:每次提交都会产生,相当于 version
- manifest: 每次提交的一组文件
- data file: parquet
- delete file
- Position deletes: 文件名, row offset
- Equality deletes: 匹配条件
读写流程
以下 SQL 为例,iceberg 两种表格式 COW 和 MOR 的读写流程
CREATE TABLE testhive.default.table (
id INT,
dep STRING
) USING iceberg
TBLPROPERTIES (
'write.format.default' = 'parquet',
'write.delete.mode' = 'copy-on-write',
'write.update.mode' = 'copy-on-write',
'write.delete.mode' = 'merge-on-read',
'write.update.mode' = 'merge-on-read',
'format-version' = '2'
);
INSERT INTO TABLE testhive.default.table VALUES (1, 'software'), (2, 'hr'), (3, 'hehe');
UPDATE testhive.default.table SET id = -1 WHERE dep = 'hr';
DELETE FROM testhive.default.table WHERE id = 3;
Copy On Write
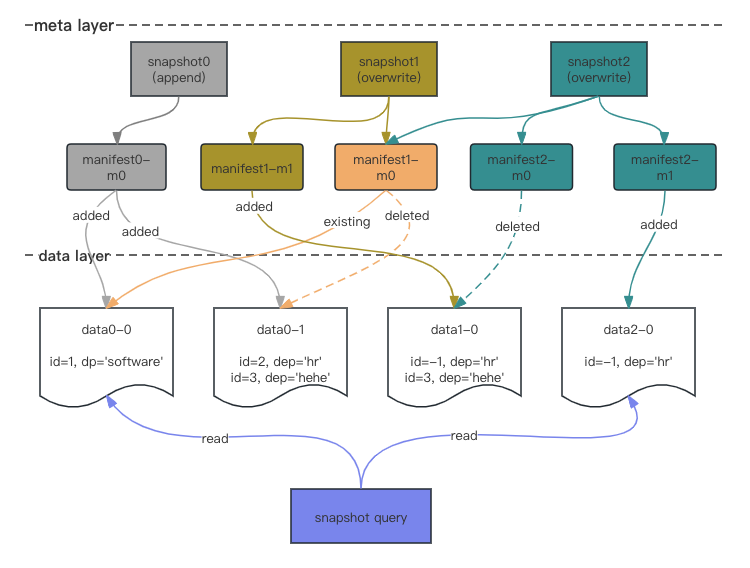
- 第一次写入生成 snapshot0,新增了两个 parquet 文件
- 第二次写入生成 snapshot1,全量读 snapshot1 根据 update filter 过滤后,重写 data0-1 为 data1-0
- 第三次写入生成 snapshot2,全量读 snapshot2 根据 delete filter 过滤后,重写 data1-0 为 data2-0
- 查询时读取 snapshot2 的 metafestList(manifest1-m0, manifest2-m0, manifest2-m1),读取 data0-0 和 data2-0 两个 parquet 文件
Merge On Read
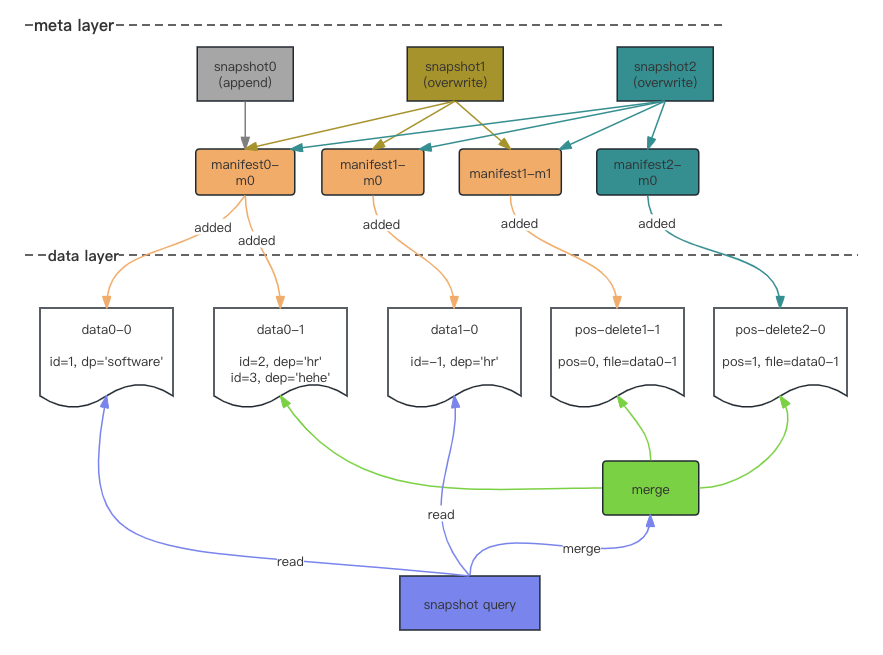
- 第一次写入生成 snapshot0,新增了两个 parquet 文件
- 第二次写入生成 snapshot1,全量读 snapshot1 根据 update filter 过滤后,新增 pos-delete1-1 删除更新前的数据,新增 data1-0 保存更新后的数据
- 第三次写入生成 snapshot2,全量读 snapshot2 根据 delete filter 过滤后,新增 pos-delete2-0 删除数据
- 查询时读取 snapshot2 的 metafestList(manifest0-m0, manifest1-m0, manifest1-m1, manifest2-mo),读取 data0-0 和 data1-0 两个 parquet 文件,合并 data0-1, pos-delete1-1, pos-delete2-0 三个 parquet 文件。合并时如果数据较少,在内存中构建 bitmap 根据位置进行过滤;数据较大,则使用 sortMerge 方式
Delete file
写入流程
Spark 的 MOR 表会写入 pos-delete,Flink 会缓存一个 batch 的数据,根据缓存判断写 pos-delete 还是 eq-delete
- 判断 rowkind 为 insert/update-after
- 放入 insertRowMap Map<data, pos>
- 写 dataFile
- 判断 rowkind 为 delete/update-before
- insertRowMap 中存在,写 pos-delete
- insertRowMap 中不存在,写 eq-delete
读取流程
Position deletes 文件会进行以下合并
- 合并时如果数据较少,在内存中构建 bitmap 根据位置进行过滤
- 数据较大,则使用 sortMerge 方式
Equality deletes 文件会进行以下合并
- 找到所有 seq-num 小于 deleteFile 的 dataFile
- 进行 anti-join
分区
DDL 中定义了普通列和分区列的映射关系
CREATE TABLE testhive.default.table (
id bigint,
date string)
USING iceberg
PARTITIONED BY (date, bucket(2, id));
INSERT INTO TABLE testhive.default.table VALUES
(0, '2022-01-01'),
(1, '2022-01-01'),
(2, '2022-01-01'),
(3, '2022-01-01'),
(0, '2022-01-02'),
(1, '2022-01-02');
实际存储上产生了类似 parition by date + clustered by (id) into 2 buckets 的效果
├── date=2022-01-01
│ ├── id_bucket=0
│ │ └── 00000-0-1f12309b-9c48-4fcf-916a-09094cbe52c0-00001.parquet
│ └── id_bucket=1
│ └── 00001-1-1df1c41b-1f28-4512-889f-9ed6b9a7b4b0-00001.parquet
└── date=2022-01-02
└── id_bucket=0
└── 00001-1-1df1c41b-1f28-4512-889f-9ed6b9a7b4b0-00002.parquet
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2024/01/27/1-iceberg/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)