Olap 引擎或者数据湖基本都借鉴了 LSM 的思想来平衡读写性能,以及处理 update/delete
ClickHouse
文件结构
CREATE TABLE my_first_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32,
date UInt32
)
ENGINE = MergeTree
PRIMARY KEY (user_id, timestamp)
PARTITION BY date;
INSERT INTO my_first_table (user_id, message, timestamp, metric, date) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0, 2),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421, 2),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718, 2),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159, 2);
DELETE FROM my_first_table
WHERE user_id = 101;
OPTIMIZE TABLE my_first_table;
执行以上 sql 可以得到以下目录结构
- default
- my_first_table
# 第一次 insert 写的 part 目录
- 2_1_1_0
# 第二次 delete 写的 part 目录
- 2_1_1_0_2
# 第三次执行完 compaction 的结果
- 2_1_1_1_2
每次对分区的写入都会产生一个新的目录称为 part,一个分区下包含多个 part。part 目录的命名规则为 {partitionId}_{min_block_num}_{max_block_num}_{level}_{version}
- partitionId: 分区值
- min/max block num: 包含的最小、最大的 lsm layer block num。part 初始写入时这两个值相等
- level: lsm level。每次 compact 都会 level + 1
- version: 每次 update/delete 都会 version+1,用于合并时确定影响范围内的 part,类似 iceberg 中的 Sequence Nubmer
以下文件都是 part 目录中包含的文件
元数据
- checksum.txt: 各文件的检验码
- serialization.json: 序列化信息
- default_compression_codec.txt: 压缩信息
- metadata_version.txt: 元数据版本信息
- columns.txt: schema
- count.txt: 行数
索引
- primary.cidx: 主键索引,用于存放主键与 granule 的映射关系
- minmax_date.idx: 分区列的 min-max 索引
- partition.dat: 从分区列计算出分区值的方法
数据: 根据写入数据大小使用 compact 和 wide 两种模式,compact 模式下所有列都会写入一个文件,wide 模式下每个列都会写一个文件
- data.bin: compact 数据文件,由压缩后的 bin block 组成
- bin block: 每个 bin block 控制在 64KB~1MB,相比于整个文件一起压缩,有以下优缺点
- 存在额外压缩计算开销,压缩比例不高
- bin block 为最小的 IO 单元,读时相比于加载整个文件,可以减少 IO 耗时
- data.cmrk3: 标记文件,用于存放 granule 与 bin block 的映射关系
索引
主键索引
稀疏索引:索引条目间隔 index_granularity(默认 8192 条)条数据记录,保存至 primary.idx 文件内
- 索引和数据按照 PRIMARY KEY 排序
- 数据被索引切分成多个 granule 数据块,通过二分搜索可以快速定位 granule
- 索引数据常驻内存
二级索引
二级索引保存多个 granule 的统计信息,用于跳过 granule,所以也称跳数索引
- minmax: 保存极值
- set: 保存索引列的 set。当唯一值数量超过 max_size 时,就不保存这个 granule 的 set
- bloom filter: 保存布隆过滤器
- ngrambf_v1
- tokenbf_v1
写入流程
每次写入一个新的 part 目录
读取流程
- part 目录下的 MinMax 索引,确定到 part 目录级别
- 主键索引,确定到 granule 级别
- 二级索引,对 granule 做进一步过滤
- 读出过滤后的 granule 数据根据主键进行合并
优缺点
优点:单机 Olap 查询性能高效
缺点:
- 没有事务性保证
- 通过分片来支持分布式存储,分布式 join 在两张表都很大的情况下效率很低
StarRocks
文件结构
和 Hbase 比较类似,表数据被水平切分为多个 tablet 分别存储在 BE 上,包含以下几个部分
- Rowset:一个 Tablet 被水平切分为多个 Rowset,每个 Rowset 以列存文件的形式存储
- Meta:保存 Tablet 的版本历史以及每个版本的信息,比如包含哪些 Rowset 等。序列化后存储在 RocksDB 中,为了快速访问会缓存在内存中
- DelVector:记录每个 Rowset 中被标记为删除的行,同样保存在 RocksDB 中,也会缓存在内存中以便能够快速访问
- Primary Index:保存主键与该记录所在位置的映射。以 LSM tree 的形式分别存储在内存和磁盘上
索引
由于 StarRocks 不要求 rowset 内有序,所以使用 HashMap 的方式保存哈希索引。整体类似 LSM Tree
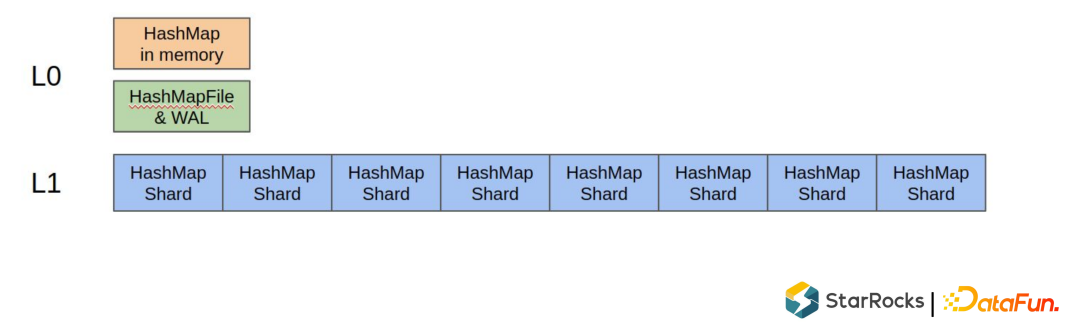
- L0 层存在 WAL 和一个内存中的 HashMap
- L1 层为多个从 L0 层 flush 的文件,每个文件大概 1M 左右大小
写入流程
- Tablet 先将数据写到 MemTable,满了后触发 flush
- flush 前需要做以下操作 a. Sort 先按主键对数据排序 b. Merge 对主键相同的多条记录进行合并 c. Split 把这批操作中的 Delete+Insert 和 Delete 操作拆分开来
- Delete 数据集会根据主键 index 生成 DelVector
- Delete+Insert 数据集除了生成 DelVector 还会写入新的 rowset
优缺点
优点:读取效率高
- 读取时不需要 merge
- 非主键列 filter 也可以下推
- 无需读取主键列
缺点:写入效率相对较低,除了写新增数据,还要更新历史的 DelVector
总结
| 存储引擎 | 更新方式 | 存储方式 | filter 下推 | merge 时机 | 读取性能 | 写入性能 |
|---|---|---|---|---|---|---|
| ClickHouse | merge on read | 有序列存 | 不支持 | 读 | 较低 | 高 |
| Hudi MOR | merge on read | 存量列存,增量行存 | 不支持 | 读 | 低 | 高 |
| Hudi/Iceberg COW | copy on write | 列存 | 支持 | 写 | 高 | 低 |
| Iceberg MOR | delete and insert | 列存 + pos/eq delete | 支持 | 写 | 较高 | 较低 |
| StarRock | delete and insert | 有序列存 + delete vector | 支持 | 写 | 高 | 较低 |
Reference
https://zhuanlan.zhihu.com/p/566219916
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2024/01/27/1-merge/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)