YARN(Yet Another Resource Negotiator)的设计思想就是分离资源管理和job的调度/监控
问题引入
由于传统的Hadoop MapReduce框架将编程模型与资源调度耦合在一起,所以存在很多问题:
- 资源调度模块只能用于MapReduce模型,导致开发人员滥用MapReduce编程模型
- 过于集中的处理作业控制流导致可扩展性问题
所以解耦编程模型和资源管理,YARN将很多与作业调度相关的功能(如task容错)委托给了具体的应用部件。
设计原则
- Scalability:可扩展性
- Multi-Tenancy:对多租户的支持,调度不同framework的job
- Serviceability:可维护性,资源管理框架与上层应用框架各自的版本升级依赖解耦
- Locality Awareness:本地感知,对于HDFS上存储的数据,将任务尽量分配到距离相近的结点上
- High Cluster Utilization:高集群利用率
- Availability:可用性
- Secure and Auditable Operation:安全且可审核的操作,面向多租户技术的环境隔离
- Support for Programming Model Diversity:支持不同的编程模型
- Flexible Resource Model:灵活的资源模型
- Backward Compatability:向下兼容
架构
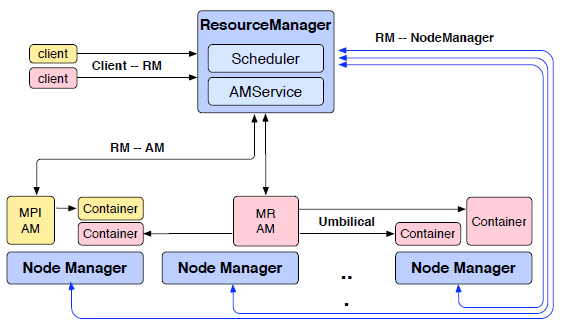
如图所示,展示了YARN的基本架构,其中蓝色是系统部件,粉红色(MR)和黄色(MPI)是运行在YARN之上的两个应用
platform层负责资源的调度,framework层负责具体应用的表达如MR、MPI。YARN将一些功能提升到了platform层,而逻辑执行计划的协调由framework层实现。
Resource Manager(RM)
全局资源管理器,从JobTracker继承了一部分功能,负责全局的资源管理和分配,而不会具体到每个Task的资源分配。由两个部件组成:Scheduler和ApplicationsManager。
Scheduler是一个可插拔的纯粹的调度器,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,调度器具有延迟调度和主导资源公平的特性
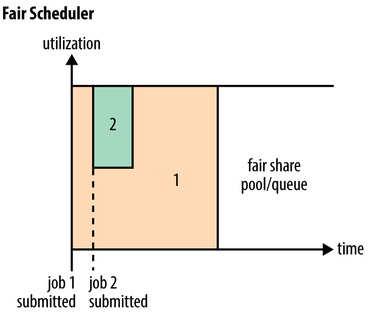
Fair Scheduler:第一个作业启动时,它也是唯一运行的作业,因而获得集群中所有的资源。当第二个作业启动时,它被分配到集群的一半资源, 这样每个作业都能公平共享资源。Capacity Scheduler:小作业保存专门队列里,优先调度小作业FIFO Scheduler:先进先出
ApplicationsManager负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动AM、监控AM运行状态并在失败时重新启动它等。
RM的主要功能是,根据应用程序需求,调度优先级和资源可用性向AM分配container和相应资源的授权访问token。container是绑定在一个结点上的逻辑资源,所谓container就是对结点资源的租用。RM通过NM的心跳获取结点快照建立集群资源整体视图,与应用程序的资源请求对比后做出相应调度策略。RM只对应用程序的整体资源进行配置,而忽略本地优化和应用流。RM接收NM报告的已执行完的container的退出状态,并转发这些状态给相应的AM。
为了更有效利用集群资源,RM能直接取回分配的资源,在资源稀缺的情况下,RM可以允许其他AM抢占某些不重要的container资源。
RM暴露两个公共接口和一个内部接口:
- client提交应用的公共接口
- AM对资源的动态访问协商的公共接口
- NM集群监控,资源访问管理的内部接口
Application Master(AM)
应用管理器,从JobTracker继承了一部分功能,协调单个应用在集群中的执行,本身运行在container中,减轻了原来运行JobTracker结点的压力。AM具有以下功能:
- 为job协调逻辑执行计划,管理job的生存周期
- 向RM申请资源
- 由资源动态构建物理执行计划
- 监控task的执行和task的容错
AM周期心跳RM来证明存活和资源请求,资源请求信息包含container的数量、每个container的资源(2GB RAM, 1 CPU)、首选的本地位置和优先级。RM以container和相应资源的授权访问token回应AM的资源请求。AM基于从RM接收到的资源,动态地调整物理执行计划,这对RM是不可见的。新结点(NM)加入时,AM会接到通知,以便于请求资源。
Node Manager(NM)
结点上的资源和task管理器,类似于TaskTracker。功能有提供container,验证container lease,管理container依赖关系,监控container的执行。
container由container launch context(CLC)描述。CLC包括环境变量的map、远程存储中的依赖项、有效载荷、安全token、创建的必要命令。NM在验证了lease之后进行配置container的环境,为了发布container,复制所有必要的依赖到本地存储上,这些依赖会被NM上的不同container使用。当依赖不被任何结点上正在运行的container使用时,该依赖会被GC守护进程清理。
首先让使用者配置NM上的可用资源并在RM上注册,之后NM通过心跳向RM报告状态,从RM的心跳响应接收指令,也会接受AM的指令。NM会监视本地硬盘,运行用户配置的脚本去发现硬件或者软件问题。当NM出现问题时,NM的状态置为unhealthy并报告RM,杀死container和停止资源分配直到恢复正常。
当container的任务完成、container要分配给其他租户或者container的lease到期时,NM会杀死container。当NM收到AM的指令时,也会杀死指定的container。当container退出,NM清理本地工作目录。当应用完成,应用的所有container的资源包括正在运行的都会被丢弃。
NM也会为应用任务的执行提供一些便利服务(auxiliary services)。例如,日志聚合功能,NM会在任务完成后日志上传到HDFS中进行持久化。文件驻留功能,NM运行container在退出时允许保存一些输出数据直到应用退出。
应用提交
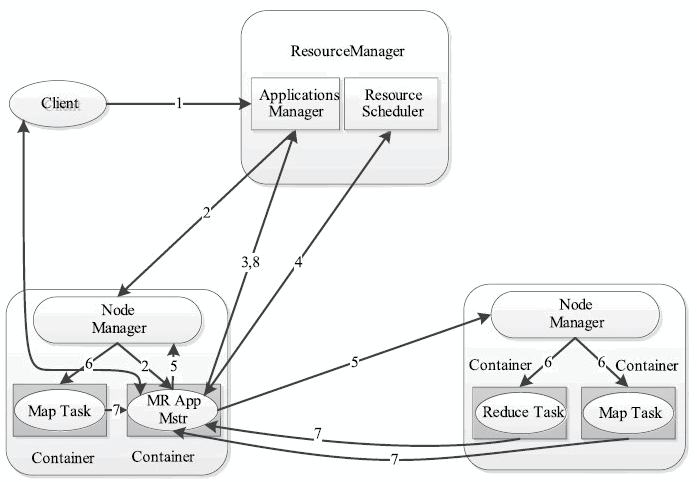
- client通过传递一个CLC(用来运行AM)给RM,来提交应用,RM会进行安全证书检查。
- RM为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动AM,应用的状态会由accepted变为running。
- AM首先向RM注册,这样用户就可以直接通过RM查看应用程序的运行状态。
- AM通过与RM的心跳请求资源(container)。
- 一旦AM申请到资源后,便与对应的NM通信,要求它启动任务。
- NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个RPC协议向AM汇报状态和进度,AM负责监控container状态和停止container来回收资源。
- AM完成任务后,向RM注销并关闭自己。
- 框架作者可以通过暴露一个控制面板,来控制不同client之间的控制流和job状态
容错
RM是YARN中的单点故障。当RM宕机的时候,通过以下步骤恢复:
- 从初始化时本地存储的信息中,RM恢复状态
- 恢复完成后,会杀死所有container包括AM
- 启动每个AM的新实例
如果RM通过心跳发现NM故障,则标记结点上的所有container为killed并通知所有AM,如果故障是暂时的,则NM将与RM重新同步,清除其本地状态然后继续。AM会对结点故障做出反应,重新执行故障结点上的container。对于在失败NM上已完成的map任务,如果属于未完成的job,那么AM会安排它们重新运行。
因为AM运行在container上,所以AM出错不会影响到集群的可用性。RM会将AM重新启动,重启的AM会和它正在运行的container进行同步。比如,MR AM会恢复所有已经完成的任务,但是运行中的任务和在恢复过程中完成的任务需要重新执行。
container的错误处理完全依赖于framework。如果用户代码抛出运行异常,任务JVM会在退出之前向其父AM发送错误报告,AM将此次任务尝试标记为failed,并释放容器以便资源可以为其他任务使用。如果由于JVM软件缺陷而造成JVM退出,NM会注意到进程已经退出,并通知AM将此次任务尝试标记为failed。AM被告知一个任务尝试失败后,将重新调度该任务的执行。AM会试图避免在以前失败过的NM上重新调度该任务。
调度策略
在多用户多任务调度场景下,面对已分配资源,存在抢占式调度和非抢占的调度。
- 抢占式调度:在空闲资源不足或者竞争统一资源的情况下,优先级低的任务会让出资源给优先级高的任务。适用于强调高优先级任务执行效率的调度策略。
- 非抢占式调度:只允许从空闲资源中分配,如果资源不足必须等待其他任务释放资源。适用于强调资源分配公平的调度策略。
面对未分配资源的调度策略
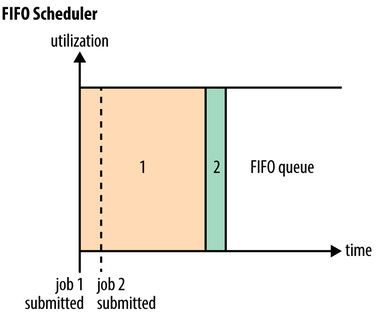
FIFO: 只有一个队列,按照提交时间或者优先级放入线性队列,资源调度时按照队列先后顺序进行资源分配。
- 在多用户场景下容易出现长时间等待调度的现象
- 大任务独占资源导致其他资源不断等待
- 多个小任务占用资源导致大任务一直无法得到资源
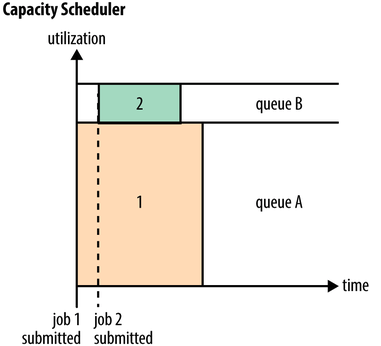
Capacity Scheduler(能力调度): 默认资源调度器。多个用户和任务组织成多个队列,每个队列设定最低保障和使用上限,当一个队列资源有剩余时,可以临时将剩余资源共享给其他队列。调度器优先将资源分配给资源使用率最低的队列,队列内部按照FIFO策略(先比较优先级再比较任务提交时间)进行调度。强调用户间的公平性
Fair Scheduler(公平调度): 与Capacity Scheduler类似,以队列为单位划分资源,每个队列可以设置最低保证和使用上限。但是也有以下不同之处
- 资源公平共享。队列内部或者队列间可以按照FIFO, Fair(默认)或者DRF策略进行资源分配
- 支持资源抢占。队列按照先等待再强制回收的策略收回之前共享的限制资源
- 提高小应用程序响应时间。由于队列内默认采用了Fair调度策略,基于最大最小公平算法,小作业可以快速获取资源并运行完成
- 负载均衡。尽可能将任务均匀分配到各个节点上
Dominant Resource Fair Scheduling(主资源公平调度DRF): 最大最小公平算法(Max-min fairness)的拓展。核心思想为最大化目前分配到最少资源量的用户或者任务的资源量
- 主资源:分配给用户的所有种类资源占该类总资源的分享量,最大值成为该用户的主分享量
- 优先给最小分享量的用户分配资源

REFERENCE
- Hadoop YARN介绍
- Apache Hadoop YARN.
- VAVILAPALLI V K, SETH S, SAHA B, 等. Apache Hadoop YARN: yet another resource negotiator[C]//Proceedings of the 4th annual Symposium on Cloud Computing - SOCC ’13. Santa Clara, California: ACM Press, 2013: 1–16.
- Hadoop权威指南
- 大数据日知录
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/02/29/yarn/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)