介绍Spark中的block传输
DiskBlockObjectWriter
将在shuffle阶段将map task的输出写入磁盘,这样reduce task就能够从磁盘中获取map task的中间输出了。有以下重要成员属性
file: 要写入的文件bufferSize: 缓冲大小syncWrites: 是否同步写blockId:BlockIdchannel:FileChannelmcs:ManualCloseOutputStreambs:OutputStreamfos:FileOutputStreamobjOut:SerializationStreamts:TimeTrackingOutputStreaminitialized: 是否已经初始化streamOpen: 是否已经打开流hasBeenClosed: 是否已经关闭committedPosition: 提交的文件位置reportedPosition: 报告给度量系统的文件位置numRecordsWritten: 已写的记录数
下面是重要的方法
open(): 打开要写入文件的各种输出流及管道。由此初始化方法可以看出来,blockId只有在创建bs(OutputStream)时使用到了,并且可以看出blockId只在是否压缩时使用到了,文件输出流由file成员属性决定,即最终写入的文件由file决定。private def initialize(): Unit = { fos = new FileOutputStream(file, true) channel = fos.getChannel() ts = new TimeTrackingOutputStream(writeMetrics, fos) class ManualCloseBufferedOutputStream extends BufferedOutputStream(ts, bufferSize) with ManualCloseOutputStream mcs = new ManualCloseBufferedOutputStream } def open(): DiskBlockObjectWriter = { if (hasBeenClosed) { throw new IllegalStateException("Writer already closed. Cannot be reopened.") } if (!initialized) { initialize() initialized = true } bs = serializerManager.wrapStream(blockId, mcs) objOut = serializerInstance.serializeStream(bs) streamOpen = true this } // SerializerManager.scala def wrapStream(blockId: BlockId, s: OutputStream): OutputStream = { wrapForCompression(blockId, wrapForEncryption(s)) } def wrapForCompression(blockId: BlockId, s: OutputStream): OutputStream = { if (shouldCompress(blockId)) compressionCodec.compressedOutputStream(s) else s } private def shouldCompress(blockId: BlockId): Boolean = { blockId match { case _: ShuffleBlockId => compressShuffle case _: BroadcastBlockId => compressBroadcast case _: RDDBlockId => compressRdds case _: TempLocalBlockId => compressShuffleSpill case _: TempShuffleBlockId => compressShuffle case _ => false } }recordWritten(): 用于对写入的记录数进行统计private def updateBytesWritten() { val pos = channel.position() writeMetrics.incBytesWritten(pos - reportedPosition) reportedPosition = pos } def recordWritten(): Unit = { numRecordsWritten += 1 writeMetrics.incRecordsWritten(1) // 2^14 if (numRecordsWritten % 16384 == 0) { updateBytesWritten() } }write(): 向输出流中写入数据override def write(kvBytes: Array[Byte], offs: Int, len: Int): Unit = { if (!streamOpen) { open() } bs.write(kvBytes, offs, len) }commitAndGet(): 把输出流中的数据写入文件并返回FileSegment。syncWrites表示强制等待当前流写完def commitAndGet(): FileSegment = { if (streamOpen) { // NOTE: Because Kryo doesn't flush the underlying stream we explicitly flush both the // serializer stream and the lower level stream. objOut.flush() bs.flush() objOut.close() streamOpen = false if (syncWrites) { // Force outstanding writes to disk and track how long it takes val start = System.nanoTime() fos.getFD.sync() writeMetrics.incWriteTime(System.nanoTime() - start) } val pos = channel.position() val fileSegment = new FileSegment(file, committedPosition, pos - committedPosition) committedPosition = pos // In certain compression codecs, more bytes are written after streams are closed writeMetrics.incBytesWritten(committedPosition - reportedPosition) reportedPosition = committedPosition numRecordsWritten = 0 fileSegment } else { new FileSegment(file, committedPosition, 0) } }
BlockManagerMessages
由BlockManagerMaster负责发送和接收的消息
RemoveExecutor: 移除ExecutorRegisterBlockManager: 注册BlockManagerUpdateBlockInfo: 更新block信息GetLocations: 获取block的位置GetLocationsMultipleBlockIds: 获取多个block的位置GetPeers: 获取其他BlockManager的BlockManagerIdGetExecutorEndpointRef: 获取Executor的EndpointRef引用RemoveBlock: 移除blockRemoveRdd: 移除RDD blockRemoveShuffle: 移除Shuffle blockRemoveBroadcast: 移除Broadcast blockGetMemoryStatus: 获取指定的BlockManager的内存状态GetStorageStatus: 获取存储状态GetBlockStatus: 获取block的状态GetMatchingBlockIds: 获取匹配过滤条件的blockHasCachedBlocks: 指定的Executor上是否有缓存的blockStopBlockManagerMaster: 停止BlockManagerMaster
BlockManagerMasterEndpoint
继承了前文所述的RPC组件中的ThreadSafeRpcEndpoint。有以下重要的成员属性
blockManagerInfo:BlockManagerId与BlockManagerInfo之间映射关系blockManagerIdByExecutor: Executor ID和BlockManagerInfo之间映射关系blockLocations:BlockId和BlockManagerId的set的映射关系,记录了block的存储位置topologyMapper: 集群所有结点的拓扑结构映射
重写了特质RpcEndpoint的receiveAndReply()方法,使用模式匹配将BlockManagerMessages中的消息交由对应的方法去处理。
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterBlockManager(blockManagerId, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint) =>
context.reply(register(blockManagerId, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint))
case _updateBlockInfo @
UpdateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size) =>
context.reply(updateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size))
listenerBus.post(SparkListenerBlockUpdated(BlockUpdatedInfo(_updateBlockInfo)))
case GetLocations(blockId) =>
context.reply(getLocations(blockId))
......
}
BlockManagerSlaveEndpoint
与BlockManagerMasterEndpoint的继承关系相同,同样重写了特质RpcEndpoint的receiveAndReply()方法,使用模式匹配将BlockManagerMessages中的消息交由对应的方法去处理。
OneForOneBlockFetcher
每个chunk代表一个block,用于BlockTransferService调用以完成block的下载。下面是重要的成员变量
client:TransportClientopenMessage:OpenBlocks。保存远端节点的appId、execId(Executor标识)和blockIdsblockIds: 字符串数组。与openMessage.blockIds一致listener:BlockFetchingListener,将在获取Block成功或失败时被回调chunkCallback:获取block成功或失败时回调,配合BlockFetchingListener使用
下面是主要的start()方法,用于开启获取流程
- 由
client向server端发送openMessage消息,回调方法放入缓存client端的缓存中,具体实现前文已经提过 - 在回调方法中,如果回调
onSuccess()则调用client.fetchChunk()获取所有block
public void start() {
if (blockIds.length == 0) {
throw new IllegalArgumentException("Zero-sized blockIds array");
}
client.sendRpc(openMessage.toByteBuffer(), new RpcResponseCallback() {
@Override
public void onSuccess(ByteBuffer response) {
try {
streamHandle = (StreamHandle) BlockTransferMessage.Decoder.fromByteBuffer(response);
logger.trace("Successfully opened blocks {}, preparing to fetch chunks.", streamHandle);
// Immediately request all chunks -- we expect that the total size of the request is
// reasonable due to higher level chunking in [[ShuffleBlockFetcherIterator]].
for (int i = 0; i < streamHandle.numChunks; i++) {
if (downloadFileManager != null) {
client.stream(OneForOneStreamManager.genStreamChunkId(streamHandle.streamId, i),
new DownloadCallback(i));
} else {
client.fetchChunk(streamHandle.streamId, i, chunkCallback);
}
}
} catch (Exception e) {
logger.error("Failed while starting block fetches after success", e);
failRemainingBlocks(blockIds, e);
}
}
@Override
public void onFailure(Throwable e) {
logger.error("Failed while starting block fetches", e);
failRemainingBlocks(blockIds, e);
}
});
}
private void failRemainingBlocks(String[] failedBlockIds, Throwable e) {
for (String blockId : failedBlockIds) {
try {
listener.onBlockFetchFailure(blockId, e);
} catch (Exception e2) {
logger.error("Error in block fetch failure callback", e2);
}
}
}
NettyBlockRpcServer
继承了RpcHandler,用于处理 NettyBlockTransferService中的 TransportRequestHandler中的请求消息,作为shuffle的server端
streamManager:OneForOneStreamManager,在之前RPC中已经介绍过了
重写了receive()和putBlockDataAsStream()
receive(): 主要接收并处理OpenBlocks和UploadBlock消息
- 当接收到
OpenBlocks消息时,获取到请求的BlockId,由BlockManager.getBlockData获取封装为ManagedBuffer的block数据(序列化)序列 - 调用
OneForOneStreamManager.registerStream()将block数据序列和app id 和channel一起注册到streams中,streamId自增生成 - 创建
StreamHandle消息(包含streamId和ManagedBuffer序列的大小),并通过响应上下文回复客户端 - 当接收到
UploadBlock消息时,获取到请求的元数据解析得到存储等级,类型信息和BlockId - 调用
BlockManager.putBlockData()写入本地存储体系中 - 通过响应上下文回复客户端
override def receive(
client: TransportClient,
rpcMessage: ByteBuffer,
responseContext: RpcResponseCallback): Unit = {
val message = BlockTransferMessage.Decoder.fromByteBuffer(rpcMessage)
logTrace(s"Received request: $message")
message match {
case openBlocks: OpenBlocks =>
val blocksNum = openBlocks.blockIds.length
val blocks = for (i <- (0 until blocksNum).view)
yield blockManager.getBlockData(BlockId.apply(openBlocks.blockIds(i)))
val streamId = streamManager.registerStream(appId, blocks.iterator.asJava,
client.getChannel)
logTrace(s"Registered streamId $streamId with $blocksNum buffers")
responseContext.onSuccess(new StreamHandle(streamId, blocksNum).toByteBuffer)
case uploadBlock: UploadBlock =>
// StorageLevel and ClassTag are serialized as bytes using our JavaSerializer.
val (level: StorageLevel, classTag: ClassTag[_]) = {
serializer
.newInstance()
.deserialize(ByteBuffer.wrap(uploadBlock.metadata))
.asInstanceOf[(StorageLevel, ClassTag[_])]
}
val data = new NioManagedBuffer(ByteBuffer.wrap(uploadBlock.blockData))
val blockId = BlockId(uploadBlock.blockId)
logDebug(s"Receiving replicated block $blockId with level ${level} " +
s"from ${client.getSocketAddress}")
blockManager.putBlockData(blockId, data, level, classTag)
responseContext.onSuccess(ByteBuffer.allocate(0))
}
}
BlockTransferService
用于发起block的上传和下载请求,作为shuffle的client端。下面是具体的两个方法
fetchBlockSync(): 同步下载block,实质就是调用未实现的fetchBlocks(),并且等待BlockFetchingListener处理获取后的block数据,这里要等待两个流程(请求block,拉取block数据,具体看总结部分)def fetchBlockSync( host: String, port: Int, execId: String, blockId: String, tempFileManager: DownloadFileManager): ManagedBuffer = { // A monitor for the thread to wait on. val result = Promise[ManagedBuffer]() fetchBlocks(host, port, execId, Array(blockId), new BlockFetchingListener { override def onBlockFetchFailure(blockId: String, exception: Throwable): Unit = { result.failure(exception) } override def onBlockFetchSuccess(blockId: String, data: ManagedBuffer): Unit = { data match { case f: FileSegmentManagedBuffer => result.success(f) case e: EncryptedManagedBuffer => result.success(e) case _ => try { val ret = ByteBuffer.allocate(data.size.toInt) ret.put(data.nioByteBuffer()) ret.flip() result.success(new NioManagedBuffer(ret)) } catch { case e: Throwable => result.failure(e) } } } }, tempFileManager) ThreadUtils.awaitResult(result.future, Duration.Inf) }uploadBlockSync(): 同步上传block,内部调用了未实现的uploadBlock()方法,同步的实现方式与fetchBlockSync()相同,只不过Promise对象在uploadBlock()方法内部创建了def uploadBlockSync( hostname: String, port: Int, execId: String, blockId: BlockId, blockData: ManagedBuffer, level: StorageLevel, classTag: ClassTag[_]): Unit = { val future = uploadBlock(hostname, port, execId, blockId, blockData, level, classTag) ThreadUtils.awaitResult(future, Duration.Inf) }
BlockTransferService有两个实现类:用于测试的MockBlockTransferService及NettyBlockTransferService
下面主要介绍NettyBlockTransferService。有以下重要成员对象
transportContext:TransportContextserver:TransportServer
下面是重要的成员方法
init():NettyBlockTransferService只有在其init()方法被调用,即被初始化后才提供服务private def createServer(bootstraps: List[TransportServerBootstrap]): TransportServer = { def startService(port: Int): (TransportServer, Int) = { val server = transportContext.createServer(bindAddress, port, bootstraps.asJava) (server, server.getPort) } Utils.startServiceOnPort(_port, startService, conf, getClass.getName)._1 } override def init(blockDataManager: BlockDataManager): Unit = { val rpcHandler = new NettyBlockRpcServer(conf.getAppId, serializer, blockDataManager) var serverBootstrap: Option[TransportServerBootstrap] = None var clientBootstrap: Option[TransportClientBootstrap] = None if (authEnabled) { serverBootstrap = Some(new AuthServerBootstrap(transportConf, securityManager)) clientBootstrap = Some(new AuthClientBootstrap(transportConf, conf.getAppId, securityManager)) } transportContext = new TransportContext(transportConf, rpcHandler) clientFactory = transportContext.createClientFactory(clientBootstrap.toSeq.asJava) server = createServer(serverBootstrap.toList) appId = conf.getAppId logInfo(s"Server created on ${hostName}:${server.getPort}") }fetchBlocks(): 发送下载远端block请求创建
RetryingBlockFetcher.BlockFetchStarter,如果最大重试次数大于0则创建RetryingBlockFetcher用于发送请求,否则直接调用blockFetchStarter的createAndStart()方法,创建TransportClient再创建OneForOneBlockFetcher并调用start()override def fetchBlocks( host: String, port: Int, execId: String, blockIds: Array[String], listener: BlockFetchingListener, tempFileManager: DownloadFileManager): Unit = { logTrace(s"Fetch blocks from $host:$port (executor id $execId)") try { val blockFetchStarter = new RetryingBlockFetcher.BlockFetchStarter { override def createAndStart(blockIds: Array[String], listener: BlockFetchingListener) { val client = clientFactory.createClient(host, port) new OneForOneBlockFetcher(client, appId, execId, blockIds, listener, transportConf, tempFileManager).start() } } val maxRetries = transportConf.maxIORetries() if (maxRetries > 0) { // Note this Fetcher will correctly handle maxRetries == 0; we avoid it just in case there's // a bug in this code. We should remove the if statement once we're sure of the stability. new RetryingBlockFetcher(transportConf, blockFetchStarter, blockIds, listener).start() } else { blockFetchStarter.createAndStart(blockIds, listener) } } catch { case e: Exception => logError("Exception while beginning fetchBlocks", e) blockIds.foreach(listener.onBlockFetchFailure(_, e)) } }在
RetryingBlockFetcher中实际上调用了fetchAllOutstanding()方法。内部发送获取block请求部分其实是调用的fetchBlocks()中传入的blockFetchStarter的createAndStart()方法与非重试的fetcher请求代码是一样的// RetryingBlockFetcher public void start() { fetchAllOutstanding(); } private void fetchAllOutstanding() { // Start by retrieving our shared state within a synchronized block. String[] blockIdsToFetch; int numRetries; RetryingBlockFetchListener myListener; synchronized (this) { blockIdsToFetch = outstandingBlocksIds.toArray(new String[outstandingBlocksIds.size()]); numRetries = retryCount; myListener = currentListener; } // Now initiate the fetch on all outstanding blocks, possibly initiating a retry if that fails. try { fetchStarter.createAndStart(blockIdsToFetch, myListener); } catch (Exception e) { logger.error(String.format("Exception while beginning fetch of %s outstanding blocks %s", blockIdsToFetch.length, numRetries > 0 ? "(after " + numRetries + " retries)" : ""), e); if (shouldRetry(e)) { initiateRetry(); } else { for (String bid : blockIdsToFetch) { listener.onBlockFetchFailure(bid, e); } } } }如果出现异常会调用
shouldRetry()判断是否需要重试,异常是IOException并且当前的重试次数retryCount小于最大重试次数maxRetries。之后调用initiateRetry()方法进行重试,重试次数+1,新建RetryingBlockFetchListener后,使用线程池(Executors.newCachedThreadPool)提交重试任务(等待一段时间后,再次调用fetchAllOutstanding()),重试机制是异步的// RetryingBlockFetcher private synchronized boolean shouldRetry(Throwable e) { boolean isIOException = e instanceof IOException || (e.getCause() != null && e.getCause() instanceof IOException); boolean hasRemainingRetries = retryCount < maxRetries; return isIOException && hasRemainingRetries; } private synchronized void initiateRetry() { retryCount += 1; currentListener = new RetryingBlockFetchListener(); logger.info("Retrying fetch ({}/{}) for {} outstanding blocks after {} ms", retryCount, maxRetries, outstandingBlocksIds.size(), retryWaitTime); executorService.submit(() -> { Uninterruptibles.sleepUninterruptibly(retryWaitTime, TimeUnit.MILLISECONDS); fetchAllOutstanding(); }); }
uploadBlock(): 发送向远端上传block的请求- 创建
TransportClient - 序列化存储等级和类型
- 如果大于
spark.maxRemoteBlockSizeFetchToMem则调动TransportClient.uploadStream()作为流将block上传 - 否则调用
TransportClient.sendRpc()直接将block数据作为字节数组上传
override def uploadBlock( hostname: String, port: Int, execId: String, blockId: BlockId, blockData: ManagedBuffer, level: StorageLevel, classTag: ClassTag[_]): Future[Unit] = { val result = Promise[Unit]() val client = clientFactory.createClient(hostname, port) // StorageLevel and ClassTag are serialized as bytes using our JavaSerializer. // Everything else is encoded using our binary protocol. val metadata = JavaUtils.bufferToArray(serializer.newInstance().serialize((level, classTag))) val asStream = blockData.size() > conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM) val callback = new RpcResponseCallback { override def onSuccess(response: ByteBuffer): Unit = { logTrace(s"Successfully uploaded block $blockId${if (asStream) " as stream" else ""}") result.success((): Unit) } override def onFailure(e: Throwable): Unit = { logError(s"Error while uploading $blockId${if (asStream) " as stream" else ""}", e) result.failure(e) } } if (asStream) { val streamHeader = new UploadBlockStream(blockId.name, metadata).toByteBuffer client.uploadStream(new NioManagedBuffer(streamHeader), blockData, callback) } else { // Convert or copy nio buffer into array in order to serialize it. val array = JavaUtils.bufferToArray(blockData.nioByteBuffer()) client.sendRpc(new UploadBlock(appId, execId, blockId.name, metadata, array).toByteBuffer, callback) } result.future }- 创建
总结
异步获取远端block的流程如下
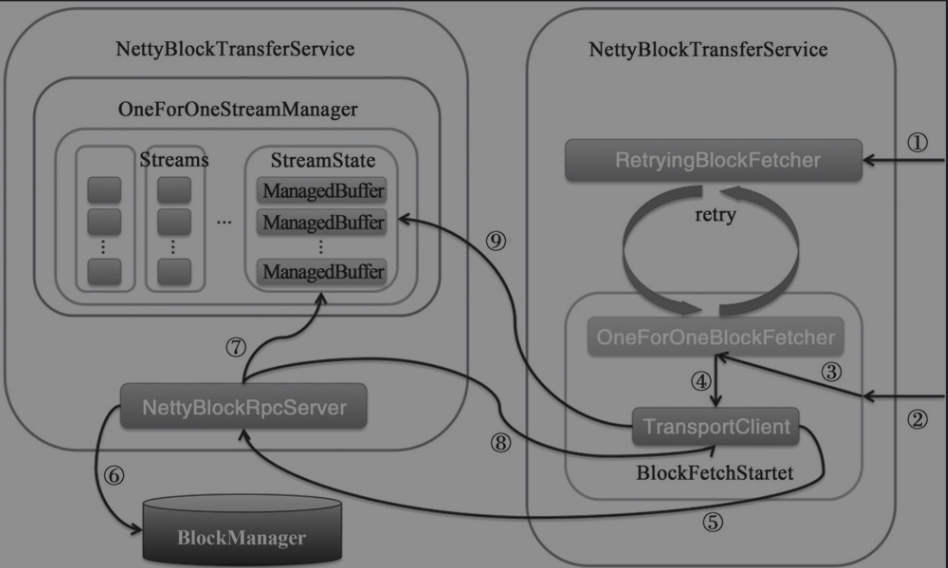
- client端调用
NettyBlockTransferService.fetchBlocks()方法获取block,如果指定重试次数,则调用RetryingBlockFetcher.start(),内部调用BlockFetchStarter.createAndStart()并且失败异步重试,同时传入BlockFetchingListener用于获取block到本地后的成功或者失败回调函数(观察者模式) - 如果未指定重试次数,则是直接调用
BlockFetchStarter.createAndStart(),失败不重试 BlockFetchStarter.createAndStart()将调用OneForOneBlockFetcher.start()OneForOneBlockFetcher.start()将调用TransportClient.sendRpc()方法发送OpenBlocks消息。接着用于处理server端响应的回调函数在TransportResponseHandler中注册- server端的
TransportRequestHandler接收到了client端发送的消息,然后调用NettyBlockRpcServer处理OpenBlocks消息 NettyBlockRpcServer.receive()中循环调用BlockManager.getBlockData()在本地存储系统中获取block数据序列- 接着调用
OneForOneStreamManager.registerStream(),将block数据序列注册为一个流 - 创建
StreamHandle包含流Id和block数据序列大小通过成功回调函数响应给client端 - client端的
TransportResponseHandler接收到server端的响应消息,然后调用之前注册的回调函数,迭代请求返回的流id中的所有chunk id(chunk与block意义相同),调用TransportClient.fetchChunk() - 这个方法调用后与1~9的流程类似,先想server端请求,server端再将block数据返回具体如下。从远端节点的缓存streams中找到与streamId对应的
StreamState,并根据索引返回StreamState的ManagedBuffer序列中的某一个ManagedBuffer(block数据)。最后调用步骤1和2中注册的观察者BlockFetchingListener处理获取到block数据
异步上传block至远端的流程如下
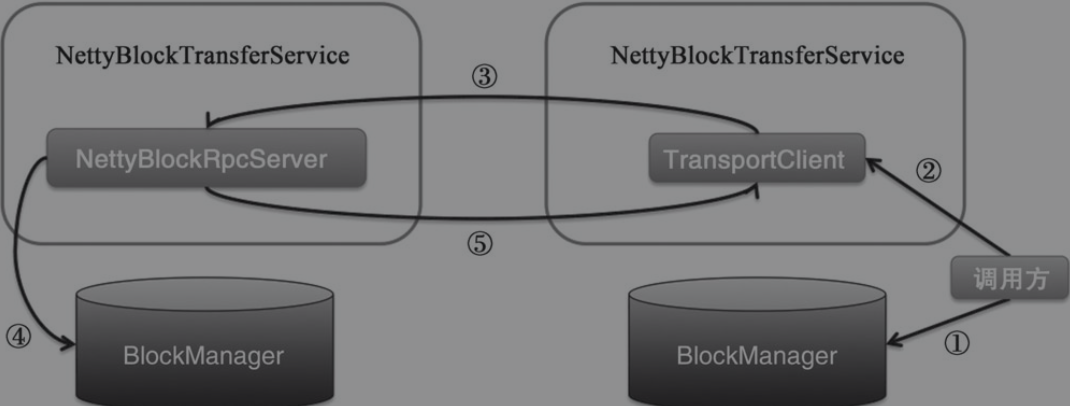
- client端要通过
BlockManager获取block数据,转化为ManagedBuffer类型 - 调用
NettyBlockTransferService.uploadBlock()方法上传block到远端节点 - 内部调用了
TransportClient.sendRpc()方法发送UploadBlock消息,接着用于处理server端响应的回调函数在TransportResponseHandler中注册 - server端的
TransportRequestHandler接收到了client端发送的消息,然后调用NettyBlockRpcServer处理UploadBlock消息。NettyBlockRpcServer.receive()中循环调用BlockManager.putBlockData()将block数据写入本地存储系统中 NettyBlockRpcServer将处理成功的消息返回给客户端,client端的TransportResponseHandler接收到server端的响应消息,然后调用之前注册的回调函数
REFERENCE
- Spark内核设计的艺术:架构设计与实现
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/09/11/store-transfer/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)