Anlysis阶段所起到的主要作用就是将逻辑算子树中未被解析的UnresolvedRelation和UnresolvedAttribute两种对象解析成Typed对象
Catalog
在关系数据库中,Catalog通常可以理解为一个容器或数据库对象命名空间中的一个层,主要用来解决命名冲突等问题。在Spark SQL中,Catalog主要用于各种函数资源信息和元数据信息(数据库、数据表、 数据视图、数据分区与函数等)的统一管理。
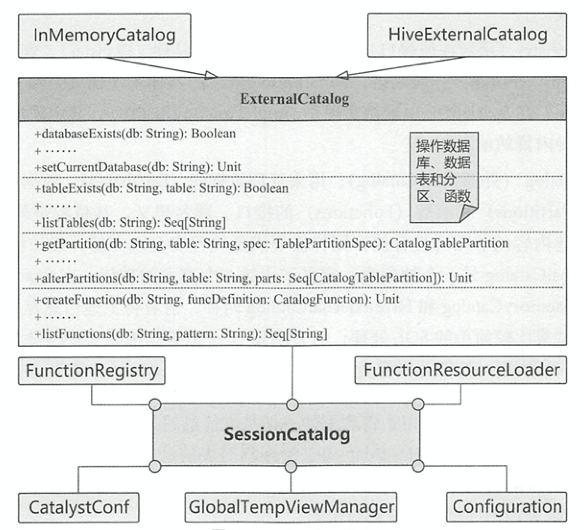
如图所示,Spark SQL 中的Catalog体系实现以SessionCatalog为主体, 通过SparkSession提供给外部调用。 本质上,SessionCatalog起到了 一个代理的作用, 对底层的元数据信息、临时表信息、视图信息和函数信息进行了封装。 包括ANTLR解析树ParserInterface, Catalyst配置信息SQLConf, Hadoop配置信息Configuration,还有以下四个通过传递静态工厂方法进行构造
GlobalTempViewManager: 全局的临时视图管理器,被DataFrame.createGlobalTempView()方法调用,进行跨session的视图管理 。GlobaLTempViewManager通过synchronized关键字保证了线程安全,提供了对全局视图(大小写敏感)的原子操作, 包括创建、更新、删除和重命名等。 内部通过HashMap维护视图名和其对应逻辑计划的映射关系FunctionResourceLoader: 函数资源加载器。通过 Jar包或文件去加载用户自定义的函数和 Hive 中的各种函数FunctionRegistry: 函数注册接口,实现对函数的注册、查找和删除 等功能。默认实现是SimpleFunctionRegistry,采用HashMap维护已注册的内置函数mutable.HashMap[FunctionIdentifier, (ExpressionInfo, FunctionBuilder)],其中FunctionBuilder为Seq[Expression] => Expression函数类型的别名ExternalCatalog: 外部系统Catalog,通过与外部系统交互来管理数据库、数据表、数据partitions和函数的接口。具体实现有InMemoryCatalog,将Catalog信息存储在内存中;HiveExternalCatalog利用Hive元数据库来实现持久化管理
与GlobalTempViewManager类似,SessionCatalog内部通过HashMap管理非全局临时视图。通过currentDb字符串变量保存当前所操作的数据库。
Rule
Spark SQL通过基于Rule的方法对逻辑计划树的结构进行转化或者改写以达到解析和优化等功能。Rule是一个抽象类,子类通过实现def apply(plan: TreeType): TreeType方法去定义不同的迭代规则。不同的Rule组合在一起就变成了Batch,下面介绍一下Analyser中的Batch
Hints
与hint有关的规则,固定最大迭代次数
ResolveBroadcastHints: 解析有关广播的hint, 如BROADCAST,BROADCAST JOIN等ResolveCoalesceHints: 解析COALESCE,REPARTITIONRemoveAllHints: 移除所有不合法的hint
Substitution
表示对结点做替换操作,固定最大迭代次数,有以下四条规则
CTESubstitution: CTE(公用表表达式)对应的是With语句,在SQL中主要用于子查询模块化。CTESubstitution的规则遍历逻辑计划树,匹配到With(child, relations)逻辑计划结点替换成解析后的CTE,合并多个子查询的逻辑计划with A as (select * from student), B as (select * from A) select * from B == Parsed Logical Plan == CTE [A, B] : :- 'SubqueryAlias `A` : : +- 'Project [*] : : +- 'UnresolvedRelation `student` : +- 'SubqueryAlias `B` : +- 'Project [*] : +- 'UnresolvedRelation `A` +- 'Project [*] +- 'UnresolvedRelation `B` == Analyzed Logical Plan == ID: string, NAME: string, AGE: string Project [ID#10, NAME#11, AGE#12] +- SubqueryAlias `B` +- Project [ID#10, NAME#11, AGE#12] +- SubqueryAlias `A` +- Project [ID#10, NAME#11, AGE#12] +- SubqueryAlias `student` +- Relation[ID#10,NAME#11,AGE#12] csvWindowsSubstitution: 遍历逻辑计划树,当匹配到WithWindowDefinition(windowDefinitions, child)表达式时,将其子节点中UnresolvedWindowExpression转换成WindowExpressionEliminateUnions: 当Union结点只有一个子结点时,替换为children.head结点SubstituteUnresolvedOrdinals: 通过配置参数spark.sql.orderByOrdinal和spark.sql.groupByOrdinal进行设置,默认都为true。将Order by,Group by的下标表示法映射到对应的列
Resolution
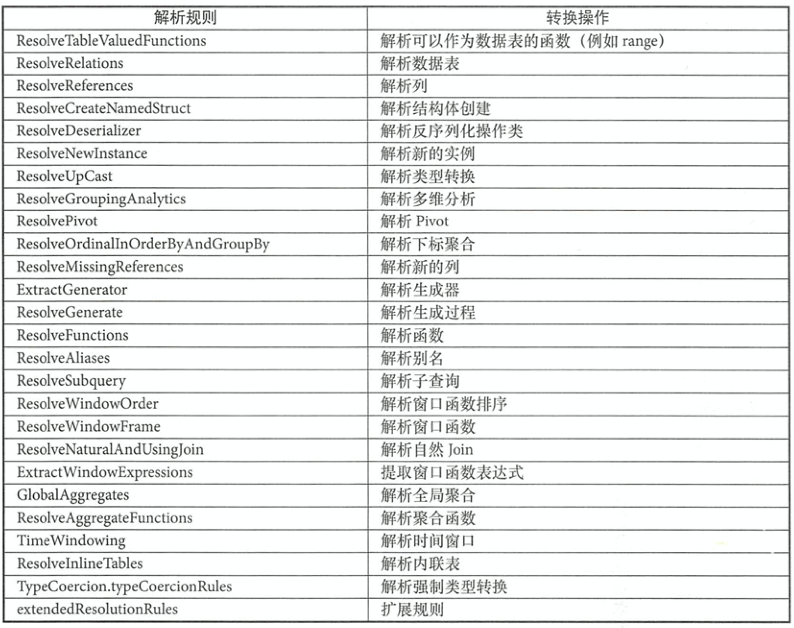
涉及了常见的数据源、数据类型、数据转换和处理操作等,固定最大迭代次数,如下表所示
Nondeterministic
只会迭代应用一次,只包含PullOutNondeterministic规则,用来将逻辑计划中非Project和Filter算子的不确定的表达式提取出来,然后将这些表达式放在内层或最终的Project算子中
UDF
只会迭代应用一次,只包含HandleNullInputsForUDF规则,用来处理输入数据为Null的情形,从上至下进行表达式的遍历,当匹配到ScalaUDF类型的表达式时,会创建If表达式来进行Null值的检查
FixNullability
只会迭代应用一次,只包含FixNullability规则,用来统一设定逻辑计划中表达式的nullable属性,遍历解析后的逻辑计划树,如果某列来自于其子节点,则其nullable值根据子节点对应的输出信息进行设置
Subquery
只会迭代应用一次,只包含UpdateOuterReferences规则,
Cleanup
固定最大迭代次数,只包含CleanupAliases规则,用来删除逻辑计划中无用的别名信息
RuleExecutor
RuleExecutor用于驱动Rule规则。如下图所示,Once和FixedPoint都继承自Strategy,表示规则最大迭代次数(一次或者多次)。Batch内部包含一套规则和Strategy。
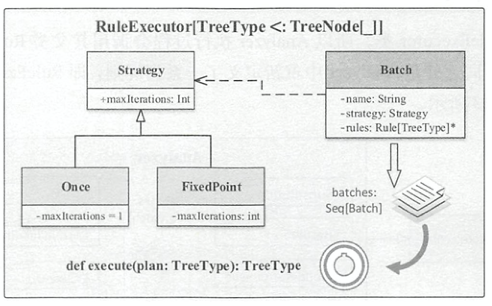
RuleExecutor.execute()方法按照batches顺序和Batch内的rules顺序,对传入的树节点节点应用对应规则。
def execute(plan: TreeType): TreeType = {
var curPlan = plan
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
// 对plan顺序应用batch内规则
val result = rule(plan)
val runTime = System.nanoTime() - startTime
if (!result.fastEquals(plan)) {
queryExecutionMetrics.incNumEffectiveExecution(rule.ruleName)
queryExecutionMetrics.incTimeEffectiveExecutionBy(rule.ruleName, runTime)
logTrace(
s"""
|=== Applying Rule ${rule.ruleName} ===
|${sideBySide(plan.treeString, result.treeString).mkString("\n")}
""".stripMargin)
}
queryExecutionMetrics.incExecutionTimeBy(rule.ruleName, runTime)
queryExecutionMetrics.incNumExecution(rule.ruleName)
// Run the structural integrity checker against the plan after each rule.
if (!isPlanIntegral(result)) {
val message = s"After applying rule ${rule.ruleName} in batch ${batch.name}, " +
"the structural integrity of the plan is broken."
throw new TreeNodeException(result, message, null)
}
result
}
iteration += 1
// 当前batch内, 多次应用规则直到最大迭代次数
if (iteration > batch.strategy.maxIterations) {
// Only log if this is a rule that is supposed to run more than once.
if (iteration != 2) {
val message = s"Max iterations (${iteration - 1}) reached for batch ${batch.name}"
if (Utils.isTesting) {
throw new TreeNodeException(curPlan, message, null)
} else {
logWarning(message)
}
}
continue = false
}
// // 当前batch内, 多次应用规则直到plan不发生变化
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
if (!batchStartPlan.fastEquals(curPlan)) {
logDebug(
s"""
|=== Result of Batch ${batch.name} ===
|${sideBySide(batchStartPlan.treeString, curPlan.treeString).mkString("\n")}
""".stripMargin)
} else {
logTrace(s"Batch ${batch.name} has no effect.")
}
}
curPlan
}
解析过程
按照前一章所述的Unresolved逻辑计划解析过程,现在继续对SELECT NAME FROM STUDENT WHERE AGE > 18 ORDER BY ID DESC的解析过程做分析。Analyzer继承自RuleExecutor,实现了batches属性,定义了之前所述的那些规则。在解析时,会调用其父类的execute()方法,传入的是Unresolved逻辑计划树的根结点,返回Resolved逻辑计划树,具体规则应用细节如下
首先其作用的是
ResolveRelations规则,通过lookupTableFromCatalog()方法直接根据其表名,从SessionCatalog中查找元信息,即可得到分析后的Relation逻辑计划,该节点上会插入一个别名节点。此外,Relation中列后面的数字表示下标。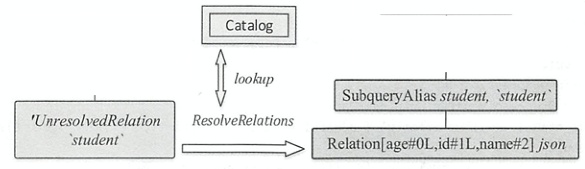
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp { case i @ InsertIntoTable(u: UnresolvedRelation, parts, child, _, _) if child.resolved => EliminateSubqueryAliases(lookupTableFromCatalog(u)) match { case v: View => u.failAnalysis(s"Inserting into a view is not allowed. View: ${v.desc.identifier}.") case other => i.copy(table = other) } case u: UnresolvedRelation => resolveRelation(u) } def resolveRelation(plan: LogicalPlan): LogicalPlan = plan match { case u: UnresolvedRelation if !isRunningDirectlyOnFiles(u.tableIdentifier) => val defaultDatabase = AnalysisContext.get.defaultDatabase val foundRelation = lookupTableFromCatalog(u, defaultDatabase) resolveRelation(foundRelation) // The view's child should be a logical plan parsed from the `desc.viewText`, the variable // `viewText` should be defined, or else we throw an error on the generation of the View // operator. case view @ View(desc, _, child) if !child.resolved => // Resolve all the UnresolvedRelations and Views in the child. val newChild = AnalysisContext.withAnalysisContext(desc.viewDefaultDatabase) { if (AnalysisContext.get.nestedViewDepth > conf.maxNestedViewDepth) { view.failAnalysis(s"The depth of view ${view.desc.identifier} exceeds the maximum " + s"view resolution depth (${conf.maxNestedViewDepth}). Analysis is aborted to " + s"avoid errors. Increase the value of ${SQLConf.MAX_NESTED_VIEW_DEPTH.key} to work " + "around this.") } executeSameContext(child) } view.copy(child = newChild) case p @ SubqueryAlias(_, view: View) => val newChild = resolveRelation(view) p.copy(child = newChild) case _ => plan }- 应用
ResolveReferences规则,成功解析Filter结点的age属性 - 应用
ImplicitTypeCasts规则,根据表达式的预期输入类型强制转换类型,对age属性进行强制类型转换 - 应用
ResolveReferences规则,成功解析Project结点和Sort结点
最终解析的Resolved逻辑计划树如下所示
== Analyzed Logical Plan ==
NAME: string
Project [NAME#11]
+- Sort [ID#10 DESC NULLS LAST], true
+- Project [NAME#11, ID#10]
+- Filter (cast(AGE#12 as int) > 18)
+- SubqueryAlias `student`
+- Relation[ID#10,NAME#11,AGE#12] csv
REFERENCE
- Spark SQL内核剖析
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/11/05/spark-sql-resolved-logical-plan/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)