介绍Spark功能切入点SparkContext用来创建和操作RDD,以及一个统一的切入点SparkSession,封装了SparkConf、SparkContext和SQLContext并作为DataSet和DataFrame的切入点。
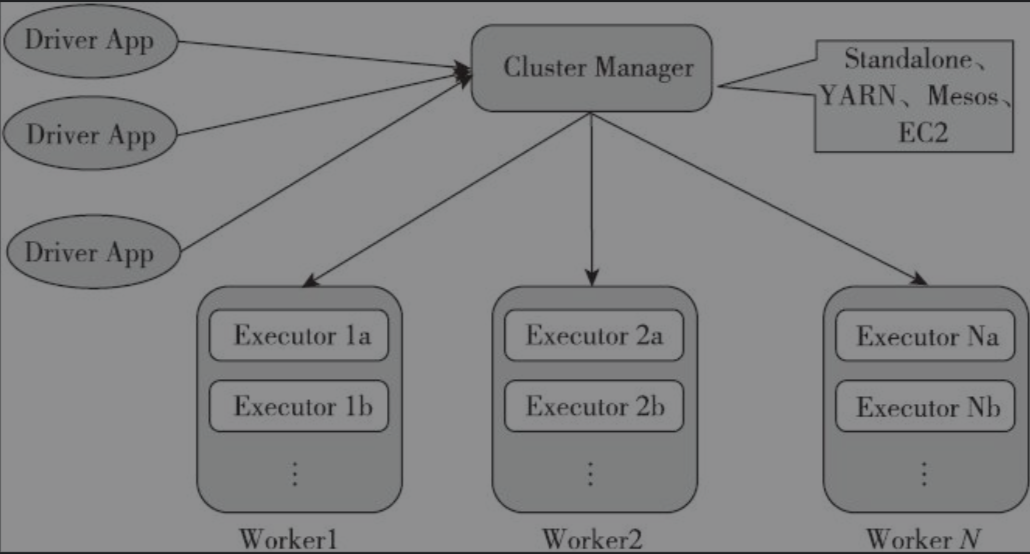
集群部署架构
- Cluster Manager:Spark的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源分配。目前,Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
- Worker:Spark的工作节点。对Spark应用程序来说,由集群管理器分配得到资源的Worker节点主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,同步资源信息给Cluster Manager。
- Executor:执行计算Task的一个线进程。主要负责Task的执行以及与Worker、Driver App的信息同步。
- Driver:客户端驱动程序,也可以理解为客户端应用程序,用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度。
SparkConf
Spark应用程序的配置参数,通过CouncurrentHashMap维护spark.开头的键值对参数。一旦构造了SparkContext,参数就不可以改变,Spark不支持在运行时修改参数。官方文档列举了一些常用参数常用参数。参数读取优先级如下
- 优先使用
SparkConf的setter方法设置的参数 - 通过-D传递给JVM的,或者通过
System.setProperty设置的参数。在初始化SparkConf时会自动加载 spark-submit传递的参数spark-defaults.conf中的参数
SparkContext
Spark功能的主要入口,表示与Spark集群的连接,用来在集群上创建RDD,累加器和广播变量
包含组件
SparkEnv: Spark运行时环境。Executor是处理任务的执行器,它依赖于SparkEnv提供的运行时环境。此外,在Driver中也包含了SparkEnv,这是为了保证local模式下任务的执行serializerManager: 序列化管理器RpcEnv: Rpc环境BlockManager: block管理器mapOutputTracker: map输出跟踪器
LiveListenerBus:SparkContext中的事件总线,接收各个使用方的事件,并且通过异步方式对事件进行匹配后调用SparkListener的不同方法SparkUI: Spark的用户界面。SparkUI间接依赖于计算引擎、调度系统、存储体系,Job、Stage、存储、Executor等组件的监控数据都会以SparkListenerEvent的形式投递到LiveListenerBus中,SparkUI将从各个SparkListener中读取数据并显示到Web界面SparkStatusTracker: 提供对Job、Stage等的监控信息ConsoleProgressBar: 依赖于SparkStatusTracker,在控制台展示Stage的进度DAGScheduler: DAG调度器,负责创建Job,将DAG中的RDD划分到不同的Stage、提交Stage等TaskScheduler: 任务调度器。TaskScheduler按照调度算法对集群管理器已经分配给应用程序的资源进行二次调度后分配给任务HeartbeatReceiver: 心跳接收器。所有Executor都会向HeartbeatReceiver发送心跳信息,HeartbeatReceiver接收到Executor的心跳信息后,首先更新Executor的最后可见时间,然后将此信息交给TaskScheduler作进一步处理。ContextCleaner: 上下文清理器。ContextCleaner实际用异步方式清理那些超出应用作用域范围的RDD、ShuffleDependency和Broadcast等信息JobProgressListener: 作业进度监听器。JobProgressListener将注册到LiveListenerBus中作为事件监听器之一使用EventLoggingListener: 将事件持久化到存储的监听器,是SparkContext中的可选组件。当spark.eventLog.enabled属性为true时启用。ExecutorAllocationManager: Executor动态分配管理器。根据工作负载动态调整Executor的数量。在配置spark.dynamicAllocation.enabled属性为true的前提下,在非local模式下或者当spark.dynamicAllocation.testing属性为true时启用ShutdownHookManager: 用于设置关闭钩子的管理器。可以给应用设置关闭钩子,这样就可以在JVM进程退出时,执行一些清理工作
初始化步骤
- 创建Spark执行环境
SparkEnv - 创建RDD清理器
metadataCleaner - 创建并初始化Spark UI
- Hadoop相关配置及Executor环境变量的设置;
- 创建任务调度
TaskScheduler - 创建和启动
DAGScheduler TaskScheduler的启动- 初始化块管理器
BlockManager - 启动测量系统
MetricsSystem - 创建和启动Executor分配管理器
ExecutorAllocationManager ContextCleaner的创建与启动- Spark环境更新
- 创建
DAGSchedulerSource和BlockManagerSource - 将
SparkContext标记为激活
SparkSession
提供了一个统一的切入点来使用Spark的各项功能,是对SparkContext、SQLContext及DataFrame等的一层封装。有以下成员属性
sparkContextsharedState:SharedState。在多个SparkSession之间共享的状态,包括SparkContext、缓存的数据、监听器及与外部系统交互的字典信息sessionState:SessionState。SparkSession的独立状态,包括SQL配置,临时表,已注册函数等sqlContext:SQLContext。Spark SQL的上下文信息conf:RuntimeConfigsqlListener: 伴生对象中的静态属性AtomicReference[SQLListener],主要用于SQL UIactiveThreadSession: 伴生对象中的静态属性InheritableThreadLocal[SparkSession],用于持有当前线程的激活的SparkSessiondefaultSession: 伴生对象中的静态属性AtomicReference[SparkSession],用于持有默认的Spark-Session
Builder
内部类静态类Builder是SparkSession实例的构建器,应用了工厂方法。有以下成员变量
options:HashMap[String, String]。用于缓存构建SparkConf所需的属性配置extensions:SparkSessionExtensions。用于拓展Spark Catalyst中的拓展规则userSuppliedContext:Option[SparkContext]。用于持有用户提供的SparkContext
有以下成员方法
config(),appName(),master(),enableHiveSupport(): 向options属性中添加配置参数**。getOrCreate(): 获取或创建SparkSession- 判断是否在driver上,只有在driver上才可能创建
SparkSession - 如果能从
activeThreadSession中获取到SparkSession并且还未停止,则直接返回。否则使用SparkSession.synchronized同步以下操作 - 尝试返回未停止的
defaultSession - 尝试获取
userSuppliedContext中的SparkContext,或则使用options内的配置属性创建一个SparkContext - 加载Catalyst拓展规则
- 构建
SparkSession并放入activeThreadSession和defaultSession并返回
def getOrCreate(): SparkSession = synchronized { assertOnDriver() // Get the session from current thread's active session. var session = activeThreadSession.get() if ((session ne null) && !session.sparkContext.isStopped) { applyModifiableSettings(session) return session } // Global synchronization so we will only set the default session once. SparkSession.synchronized { // If the current thread does not have an active session, get it from the global session. session = defaultSession.get() if ((session ne null) && !session.sparkContext.isStopped) { applyModifiableSettings(session) return session } // No active nor global default session. Create a new one. val sparkContext = userSuppliedContext.getOrElse { val sparkConf = new SparkConf() options.foreach { case (k, v) => sparkConf.set(k, v) } // set a random app name if not given. if (!sparkConf.contains("spark.app.name")) { sparkConf.setAppName(java.util.UUID.randomUUID().toString) } SparkContext.getOrCreate(sparkConf) // Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions. } // Initialize extensions if the user has defined a configurator class. val extensionConfOption = sparkContext.conf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS) if (extensionConfOption.isDefined) { val extensionConfClassName = extensionConfOption.get try { val extensionConfClass = Utils.classForName(extensionConfClassName) val extensionConf = extensionConfClass.newInstance() .asInstanceOf[SparkSessionExtensions => Unit] extensionConf(extensions) } catch { // Ignore the error if we cannot find the class or when the class has the wrong type. case e @ (_: ClassCastException | _: ClassNotFoundException | _: NoClassDefFoundError) => logWarning(s"Cannot use $extensionConfClassName to configure session extensions.", e) } } session = new SparkSession(sparkContext, None, None, extensions) options.foreach { case (k, v) => session.initialSessionOptions.put(k, v) } setDefaultSession(session) setActiveSession(session) // Register a successfully instantiated context to the singleton. This should be at the // end of the class definition so that the singleton is updated only if there is no // exception in the construction of the instance. sparkContext.addSparkListener(new SparkListener { override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = { defaultSession.set(null) } }) } return session }- 判断是否在driver上,只有在driver上才可能创建
REFERENCE
- Spark内核设计的艺术:架构设计与实现
文档信息
- 本文作者:wzx
- 本文链接:https://masterwangzx.com/2020/10/16/spark-session/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)